接口简介
概述
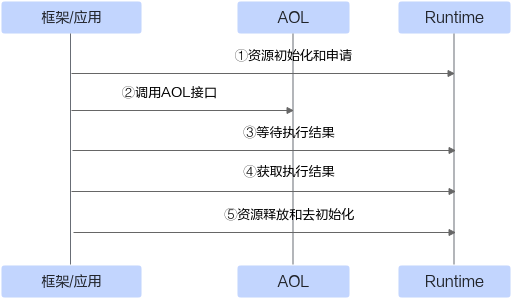
为加速模型算力释放,CANN(Compute Architecture for Neural Networks)提供了算子加速库(Ascend Operator Library,简称AOL)。该库提供了一系列丰富且深度优化过的高性能算子API,更亲和昇腾AI处理器,调用流程如图1所示。开发者可直接调用算子库API使能模型创新与应用,以进一步提升开发效率和获取极致模型性能。
接口说明
本文档针对不同领域的算子API阐述了具体的接口定义、功能描述、参数说明、约束限制和调用示例等,指导开发者快速上手调用算子API。此外,还提供不同框架IR(Intermediate Representation)定义的算子规格信息,方便开发者自行构建网络模型。

API分类 |
说明 |
API支持度 |
|---|---|---|
NN算子和融合算子API依赖的公共Meta接口,如创建aclTensor、aclScalar、aclIntArray等。 |
- |
|
Neural Network算子是CANN基础算子,接口前缀为aclnnXxx,覆盖TensorFlow、Pytorch、MindSpore、ONNX等框架中深度学习算法相关的计算类型,包括Softmax、MatMul、Convolution等典型计算。 目前该类算子API在整个算子库中占最大比重。 |
Atlas 200/300/500 推理产品不支持该接口。 |
|
融合算子接口前缀为aclnnXxx,提供了Flash Attention、MC2等高性能融合算子。 该类算子本质是将多个独立的基础“小算子”(如向量Vector、矩阵Cube等)融合成一个“大算子”,达到提升算子性能或内存收益的目的。 |
Atlas 200/300/500 推理产品不支持该接口。 Atlas 200/500 A2推理产品不支持该接口。 Atlas 训练系列产品不支持该接口。 |
|
Digital Vision Pre-Processing算子是CANN基础算子,接口前缀为acldvppXxx,提供高性能视频/图片编解码、图像裁剪缩放等预处理API。 |
Atlas 200/300/500 推理产品不支持该接口。 Atlas 200/500 A2推理产品不支持该接口。 Atlas 训练系列产品不支持该接口。 Atlas 推理系列产品不支持该接口。 |
|
罗列了基于Ascend IR定义的算子信息。 |
- |
|
罗列了基于TensorFlow框架原生IR定义的算子信息。 |
- |
|
- |
罗列了基于Caffe框架原生IR定义的算子信息。 |
Atlas A2训练系列产品/Atlas 800I A2推理产品不支持该接口。 |
- |
罗列了基于ONNX框架原生IR定义的算子信息。 |
- |