aclCompileOpt
typedef enum {
ACL_PRECISION_MODE, // 网络模型的算子精度模式
ACL_AICORE_NUM, // 模型编译时使用的AI Core数量
ACL_AUTO_TUNE_MODE, // 算子的自动调优模式
ACL_OP_SELECT_IMPL_MODE, // 选择算子是高精度实现还是高性能实现
ACL_OPTYPELIST_FOR_IMPLMODE, // 列举算子类型的列表,该列表中的算子使用ACL_OP_SELECT_IMPL_MODE指定的模式
ACL_OP_DEBUG_LEVEL, // TBE算子编译debug功能开关
ACL_DEBUG_DIR, // 保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径,包括算子.o/.json/.cce等文件。
ACL_OP_COMPILER_CACHE_MODE, // 算子编译磁盘缓存模式
ACL_OP_COMPILER_CACHE_DIR, // 算子编译磁盘缓存的目录
ACL_OP_PERFORMANCE_MODE, // 通过该选项设置是否按照算子执行高性能的方式编译算子
ACL_OP_JIT_COMPILE, // 选择是在线编译算子,还是使用已编译的算子二进制文件
ACL_OP_DETERMINISTIC, // 是否开启确定性计算
ACL_CUSTOMIZE_DTYPES, // 模型编译时自定义某个或某些算子的计算精度
ACL_OP_PRECISION_MODE, // 指定算子内部处理时的精度模式,支持指定一个算子或多个算子。
ACL_ALLOW_HF32, // hf32是昇腾推出的专门用于算子内部计算的精度类型,当前版本不支持
ACL_PRECISION_MODE_V2, // 网络模型的算子精度模式,相比ACL_PRECISION_MODE选项,ACL_PRECISION_MODE_V2是新版本中新增的,精度模式更多,同时原有精度模式选项值语义更清晰,便于理解
ACL_OP_DEBUG_OPTION // 当前仅支持配置为oom,表示开启Global Memory访问越界检测
} aclCompileOpt;
|
编译选项 |
取值说明 |
|---|---|
|
ACL_PRECISION_MODE |
用于配置网络模型的算子精度模式。如果不配置该编译选项,默认采用allow_fp32_to_fp16。
|
|
ACL_AICORE_NUM |
用于配置模型编译时使用的AI Core数量。 当前版本设置无效。 |
|
ACL_AUTO_TUNE_MODE |
该参数后续废弃,请勿配置,否则后续版本可能存在兼容性问题。若涉及调优,请参见《AOE工具使用指南》。 用于配置算子的自动调优模式。
|
|
ACL_OP_SELECT_IMPL_MODE |
用于选择算子是高精度实现还是高性能实现。如果不配置该编译选项,默认采用high_precision。
|
|
ACL_OPTYPELIST_FOR_IMPLMODE |
通过ACL_OPTYPELIST_FOR_IMPLMODE选项设置算子类型的列表(多个算子使用英文逗号进行分隔),与ACL_OP_SELECT_IMPL_MODE选项配合使用,设置列表中的算子通过高精度实现或高性能实现。 |
|
ACL_OP_DEBUG_LEVEL |
用于配置TBE算子编译debug功能开关。
说明:
配置为2(即开启ccec编译选项)时,会导致算子Kernel(*.o文件)大小增大。动态Shape场景下,由于算子编译时会遍历可能的Shape场景,因此可能会导致算子Kernel文件过大而无法进行编译,此种场景下,建议不要配置ccec编译选项。 由于算子Kernel文件过大而无法编译的报错日志示例如下: message:link error ld.lld: error: InputSection too large for range extension thunk ./kernel_meta_xxxxx.o |
|
ACL_DEBUG_DIR |
用于配置保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径(默认路径:执行应用的当前路径/kernel_meta),包括算子.o/.json/.cce等文件。具体生成哪些文件以ACL_OP_DEBUG_LEVEL选项设置的取值为准。 路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 |
|
ACL_OP_COMPILER_CACHE_MODE |
用于配置算子编译磁盘缓存模式。该编译选项需要与ACL_OP_COMPILER_CACHE_DIR配合使用。
若同时打开调试开关(将ACL_OP_DEBUG_LEVEL选项配置为非0值),则系统会忽略ACL_OP_COMPILER_CACHE_MODE选项的配置,对调试场景的编译结果不做缓存。 启用算子编译缓存功能时,可以通过配置文件(编译算子时在ACL_OP_COMPILER_CACHE_DIR选项指定的路径下自动生成op_cache.ini配置文件)、环境变量两种方式来设置缓存文件夹的磁盘空间大小:
若同时配置了op_cache.ini文件和环境变量,则优先读取op_cache.ini文件中的配置项,若op_cache.ini文件和环境变量都未设置,则读取系统默认值:默认磁盘空间大小500M,默认保留缓存的空间50%。 |
|
ACL_OP_COMPILER_CACHE_DIR |
用于配置算子编译文件的缓存目录(默认路径:$HOME/atc_data)。该编译选项需要与ACL_OP_COMPILER_CACHE_MODE配合使用。 路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 如果设置了ACL_OP_DEBUG_LEVEL编译选项,则只有编译选项值为0才会启用编译缓存功能,其它取值禁用编译缓存功能。 |
|
ACL_OP_PERFORMANCE_MODE |
该参数已废弃,请勿配置,否则后续版本可能存在兼容性问题。 通过该选项设置是否按照算子执行高性能的方式编译算子,默认采用normal方式。 取值范围:
|
|
ACL_OP_JIT_COMPILE |
选择是在线编译算子,还是使用已编译的算子二进制文件。
Atlas 200/300/500 推理产品,该选项默认值为enable。 Atlas 训练系列产品,该选项默认值为enable。 Atlas 推理系列产品,该选项默认值为enable。 Atlas 200I/500 A2推理产品,该选项默认值为enable。 Atlas A2训练系列产品/Atlas 800I A2推理产品,该选项默认值为disable。 |
|
ACL_OP_DETERMINISTIC |
是否开启确定性计算。
通常建议不开启确定性计算,因为确定性计算往往会导致算子执行变慢,进而影响性能。当发现模型多次执行结果不同,或者是进行精度调优时,可开启确定性计算,辅助模型调试、调优。 |
|
ACL_CUSTOMIZE_DTYPES |
*.cfg配置文件路径,包含文件名,配置文件中列举需要指定计算精度的算子名称或算子类型,每个算子单独一行。通过该配置,在模型编译时,可自定义某个或某些算子的计算精度。 配置约束:
|
|
ACL_OP_PRECISION_MODE |
设置算子精度模式的配置文件(.ini格式)路径以及文件名,路径和文件名:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符.
|
|
ACL_ALLOW_HF32 |
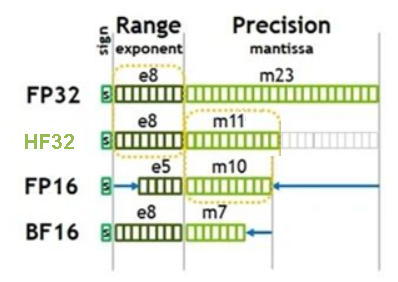
当前版本不支持该参数。 算子内部计算时是否允许HF32类型替换FP32类型,true允许,false不允许,当前版本该配置仅针对Conv类算子与Matmul类算子生效。默认针对Conv类算子,启用FP32转换为HF32;默认针对Matmul类算子,关闭FP32转换为HF32。 HF32是昇腾推出的专门用于算子内部计算的单精度浮点类型,与其他常用数据类型的比较如下图所示。HF32与FP32支持相同的数值范围,但尾数位精度(11位)却接近FP16(10位)。通过降低精度让HF32单精度数据类型代替原有的FP32单精度数据类型,可大大降低数据所占空间大小,实现性能的提升。
说明:
|
|
ACL_PRECISION_MODE_V2 |
网络模型的算子精度模式,如果不配置该编译选项,默认采用fp16。 相比ACL_PRECISION_MODE选项,ACL_PRECISION_MODE_V2是新版本中新增的,精度模式选项值语义更清晰,便于理解。
|
|
ACL_OP_DEBUG_OPTION |
当前仅支持配置为oom,表示开启算子编译阶段的Global Memory访问越界检测。 编译算子前调用aclSetCompileopt接口将ACL_OP_DEBUG_OPTION配置为oom,同时配合调用aclrtCtxSetSysParamOpt接口将ACL_OPT_ENABLE_DEBUG_KERNEL配置为1,开启Global Memory访问越界检测,这时执行算子过程中,若从Global Memory中读写数据(例如读算子输入数据、写算子输出数据等)出现内存越界,AscendCL会返回“EZ9999”错误码,表示存在算子AI Core Error问题。 |