插件机制

在通过加速库进行开发时,请使用张量作为输入。
大部分算子功能可以由加速库提供的单Operation或者根据单Operation组图完成。如果一些功能通过单Operation或者组合Operation无法支持,用户可以通过PluginOperation机制,即插件机制,开发自定义的PluginOperation,满足对应的功能。
使用流程
在使用插件机制时,用户需要自行管理因编写的插件代码导致的安全性或系统不可控行为。请确保编写的代码可靠并遵循相关安全规范和最佳实践。
图1 插件机制使用流程
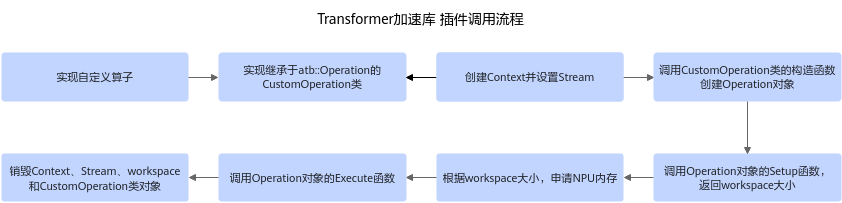
- 实现所需要的自定义算子。
- 实现继承于atb::Operation的CustomOperation类。
- 调用步骤2创建的CustomOperation类的构造函数创建类对象。
- 创建Context并设置Stream。
- 调用CustomOperation对象的Setup函数,返回workspace大小。
- 根据workspace(workspace包含中间过程输出的Tensor)大小,申请NPU内存。
- 调用CustomOperation对象的Execute函数。
- 销毁Context,Stream,workspace和CustomOperation类对象。
典型样例说明
以使用Ascend C创建Add算子为例。
- 实现所需要的自定义算子。这里以Ascend C实现为例,用户可根据实际需求选择其他方式实现自定义算子。
- 设计Add算子所需的tiling数据。
- 实现KernalAdd类,包含以下实现。
- 公共类
- 构造函数KernelAdd()。
- 初始化函数Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum),完成内存初始化相关操作。
- 核心处理函数Process(),实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作。
- 私有类
- CopyIn(int32_t progress),数据搬入函数。
- Compute(int32_t progress),数据计算函数。
- CopyOut(int32_t progress),数据搬出函数。
- 公共类
- 核函数定义
- add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z),其中x,y为输入内存,z为输出内存。实现tiling获取以及对init()和process()的调用逻辑。
- 对核函数的调用进行封装,得到add_custom_do函数,便于主程序调用。
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z) { add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z); }
- 实现继承于atb::Operation的CustomOperation类。
根据Add算子的具体情况实现AddOperation并重载Operation类的成员函数,具体可参考以下实现。
- GetName(),获取算子名称。
- Infershape(const atb::SVector<atb::TensorDesc> &inTensorDescs, atb::SVector<atb::TensorDesc> &outTensorDescs),根据inTensor指定outTensor的信息。
- GetInputNum(),获取inTensor数量。
- GetOutputNum(),获取outTensor数量。
- Setup(const atb::VariantPack &variantPack, uint64_t &workspaceSize)。
- Execute(const atb::VariantPack &variantPack, uint8_t *workspace, uint64_t workspaceSize, atb::Context* context)。
- 调用2创建的CustomOperation类的构造函数创建类对象。
AddOperation *addOp = new AddOperation("addOperation"); - 创建Context并设置Stream。
atb::Context *context = nullptr; // Context主要负责对NPU中使用的Stream进行管理 int ret = atb::CreateContext(&context); void *stream = nullptr; ret = aclrtCreateStream(&stream); context->SetExecuteStream(stream); // 设置指定Stream为Context中的executeStream
- 调用CustomOperation对象的Setup函数,返回workspace大小。
atb::VariantPack variantPack; // 此处先声明VariantPack类对象,其中包含Tensor的信息,此处省略对其具体的构造过程 uint64_t workspaceSize = 0; addOp ->Setup(variantPack, workspaceSize, context); // 传入variantPack和workspaceSize参数,setup函数中根据实际variantPack所需空间计算出workspaceSize大小并返回 - 根据workspace大小,申请NPU内存。
void* workspace = nullptr; aclrtMalloc(&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); // AscendCL的NPU内存分配函数,根据步骤三中计算出来的workspaceSize以ACL_MEM_MALLOC_HUGE_FIRST方式对workspace分配NPU内存空间
- 调用Operation对象的Execute函数。
addOp->Execute(variantPack, workspace, workspaceSize, context); // 进行具体的addOp的执行操作
- 销毁Context、Stream、workspace和CustomOperation类对象。
int ret = DestroyContext(context); // 销毁context ret = aclrtDestroyStream(stream); // 销毁stream ret = aclrtFree(workspace); // 销毁workspace delete addOp; // 销毁addOp
父主题: ATB算子编译模式如何工作