性能调优流程
鲲鹏CPU性能优化
性能环境变量配置
性能调优环境变量配置如表1所示。
参数名称 |
默认值 |
说明 |
推荐值 |
|---|---|---|---|
MIES_USE_MB_SWAPPER |
0 |
开启高性能Swap(不设置时默认关闭);Atlas 推理系列产品上需要关闭该参数。
|
maxPreemptCount >0 时,表示使用Swap功能,此时建议开启高性能Swap。 export MIES_USE_MB_SWAPPER=1 |
MIES_RECOMPUTE_THRESHOLD |
0.5 |
表示当前可下发的请求block数占总block数的比例(也就是block资源利用率)。 以0.5为例,当前可下发的请求资源利用率小于0.5时,就会触发重计算,释放少量请求的block,来保证其他请求资源使用。阈值范围只能是[0,1),值越大越容易触发重计算。0表示所有请求都无法下发。 |
取值建议在0.5上下浮动调整。 export MIES_RECOMPUTE_THRESHOLD=0.5 |
MIES_TOKENIZER_SLIDING_WINDOW_SIZE |
5 |
tokenizer流式decode时,滑动窗口大小,长度越长稳定性越好,长度越短(比如为1时)可能会出现解码后空格缺失等问题。 |
5 export MIES_TOKENIZER_SLIDING_WINDOW_SIZE=5 |
最优性能参数配置
最优性能配置各参数说明及取值如表2所示。
配置类型 |
配置项 |
配置介绍 |
推荐配置 |
|---|---|---|---|
调度配置 |
maxPrefillBatchSize |
prefill阶段一个batch中包含的请求个数的上限。 |
小于等于maxBatchSize的值,建议设置为:maxBatchSize/2 ,若显存溢出可适当调小。 |
maxPrefillTokens |
prefill阶段一个batch中包含的input token总数的上限。 |
maxPrefillBatchSize * 数据集token id平均输入长度。 |
|
maxBatchSize |
decode阶段一次推理包含的请求最大个数。 |
|
|
supportSelectBatch |
|
|
|
prefillTimeMsPerReq |
平均每个请求prefill时间。 supportSelectBatch=true时生效。 |
建议值:600;若需要降低首token时延可适当调小。 |
|
decodeTimeMsPerReq |
平均每个请求decode时间。 supportSelectBatch=true时生效。 |
建议值:50。 |
|
maxQueueDelayMicroseconds |
prefill组Batch时,最大等待时长。 |
建议值:500。 |
|
maxPreemptCount |
每一批次最大可抢占请求的上限,即限制一轮调度最多抢占请求的数量,最大上限为maxBatchSize,取值大于0则表示开启可抢占功能。 |
[0, maxBatchSize],当取值大于0时,cpuMemSize取值不可为0。 建议值:0(关闭)。 |
|
模型配置 |
worldSize |
节点可以使用的NPU卡数。 |
根据用户实际环境情况启用NPU卡数量。 |
npuDeviceIds |
推理使用的一组NPU卡号。 |
[0, 1, 2, ..., worldSize-1] |
|
npuMemSize |
单卡预留给KVCache的显存,单位GB。 |
npuMemSize=(单卡总空闲-权重/NPU卡数-后处理占用)*系数,其中系数取0.8。 通常情况下,大模型推理主要是显存Bind,因此该值配置的越大,KVCache可用的显存越多,BatchSize就越大,吞吐量将会更优。 说明:
在一些小模型场景下,显存充足,主要是计算Bind,调大显存效果并不明显。 |
|
cpuMemSize |
CPU中可以用来申请KVCache的size上限。单位:GB。 开启Swap时生效,如何开启请参考性能环境变量配置中的MIES_USE_MB_SWAPPER环境变量。 |
建议值:5。 |
|
cacheBlockSize |
表示一个block块的大小;NPU显存会被分成一个一个的block。 例如配置128,表示一个block实际大小为128*sizof(cache数据类型)字节。如果相同的显存,设置的block size越小,那么block num越多。 |
根据请求平均输入输出大小确定,一般默认为128,如果平均输入较小可以适当调小。 |
|
其他配置 |
logLevel |
设置日志级别。 |
建议值:"Error",打印Error级别的日志。 |
操作步骤
以下操作步骤以LLaMa3-8B双卡,数据类型bf16为例,进行最优性能的配置,环境信息举例如下:
本机显存大小为32G的卡,NPU数量为8卡,已占用3G。
- 计算模型配置参数,请参考表2中的“npuMemSize”参数计算出“npuMemSize”的值并根据计算结果调整配置中的该值,计算过程如下所示。
- 计算模型的权重大小,进入模型权重文件所在目录,使用“du -h”命令查看模型的权重大小。如图1所示,LLaMa3-8B模型权重大小为15G。
- 计算“npuMemSize”的值,计算公式为:Floor[(单卡总空闲-权重/NPU卡数)* 系数],系数取值为0.8。
npuMemSize = Floor[ (32 - 3 - 15/2 )] * 0.8 = 17G。

“Floor”表示计算结果向下取整。
根据计算结果,配置示例如下所示:
"ModelDeployParam": { "engineName" : "mindieservice_llm_engine", "modelInstanceNumber" : 1, "tokenizerProcessNumber" : 8, "maxSeqLen" : 2560, "npuDeviceIds" : [[4,6]], "multiNodesInferEnabled" : false, "ModelParam" : [ { "modelInstanceType": "Standard", "modelName" : "LLaMa3-8B", "modelWeightPath" : "/home/data/acltransformer_testdata/weights/LLaMa3-8B", "worldSize" : 2, "cpuMemSize" : 5, "npuMemSize" : 17, "backendType": "atb" } ] }, - 计算调度配置参数,请参考表4中的“maxBatchSize”参数计算出“maxBatchSize”的值并根据计算结果调整配置中的该值,计算过程如下所示。根据计算公式:maxBatchSize = Total Block Num/Block Num,需要先计算出“Total Block Num”和“Block Num”的值。
- 计算“Total Block Num”的值。
- 方式一(实测获取):
- “Total Block Num”的值可以通过跑一次性能后在Python日志中的“npuBlockNum”获取。
- “Total Block Num”的值也可以直接从info级打屏日志k_caches[0].shape=torch.Size([npuBlockNum, -, -, -])中torch.Size的第一个值获取。
- 方式二(公式计算):
Total Block Num = Floor[NPU显存/(模型网络层数*cacheBlockSize*模型注意力头数*注意力头大小*Cache类型字节数*Cache数)],公式中各参数的取值信息如表3所示。
表3 Total Block Num公式中的参数值 参数
取值
NPU显存
1中“npuMemSize”的值:17。
模型网络层数
模型网络层数是模型权重文件config.json中的num_hidden_layers值,LLaMa3-8B的模型网络层数取值为:32。
cacheBlockSize
默认值:128。该参数的值与表1中cacheBlockSize的值保持一致。
模型注意力头数
模型注意力头数是模型权重文件config.json中num_attention_heads参数的值。
“模型注意力头数*注意力头大小”的值为模型权重文件config.json中hidden_size参数的值,即注意力头大小可以根据模型注意力头数计算获得。
说明:对于GQA类模型(分组查询注意力类模型,例如LLaMa3-8B),需使用模型权重文件config.json中num_key_value_heads参数的值而不是num_attention_heads参数的值作为“模型注意力头数”的值参与计算,即对于两卡LLaMa3-8B,每张卡上的“模型注意力头数*注意力头大小”的值应该为8*128/2=512。
注意力头大小
Cache类型字节数
由模型config.json文件中的torch.dtype决定,一般为float16类型,取值为:2。
Cache数
Key+Value的值,默认值:2。
将以上参数值代入公式,得到Total Block Num = Floor[17*1024*1024*1024/(32 * 128 * 8*128/2*2*2)] = 2176。
注:以上算式中128/2是由于LLaMa3-8B双卡,所以注意头数需均分在2张卡上。
- 方式一(实测获取):
- 计算每个请求所需“Block Num”的值,公式中各参数的取值信息如表4所示。
根据计算公式:
- 所需最大Block Num = Ceil(输入Token数/cacheBlockSize)+Ceil(最大输出Token数/cacheBlockSize)
- 所需最小Block Num = Ceil(输入Token数/cacheBlockSize)
- 所需平均Block Num = Ceil(输入Token数/cacheBlockSize)+Ceil(平均输出Token数/cacheBlockSize)
表4 Block Num公式中的参数值 参数
取值
输入Token数
首次一般参考数据集的平均输入,取值100。
第二次则可以直接取返回结果中的average_input_length的值,示例取值:186。
最大输出Token数
从config.json文件中的maxIterTimes参数获取,示例取值:512。
平均输出Token数
实际运行测试数据集后统计的平均输出长度,示例取值:346。
cacheBlockSize
默认值:128。该参数的值与表1中cacheBlockSize的值保持一致。
将以上参数值代入公式:
- 所需最小Block Num = Ceil(186/128) = 2
- 所需最大Block Num = Ceil(186/128)+Ceil(512/128) = 6
- 所需平均Block Num = Ceil(186/128)+Ceil(346/128) = 5
“Ceil”表示计算结果向上取整。
- 计算“maxBatchSize”的取值范围。
根据2.a和2.b计算出的“Total Block Num”和“Block Num”值,然后使用公式maxBatchSize=Floor[Total Block Num/Block Num]计算“maxBatchSize”的取值范围。
- 最小maxBatchSize = Floor[Total Block Num/所需最大Block Num] = 362
- 最大maxBatchSize = Floor[Total Block Num/所需最小Block Num] = 1088
- 平均maxBatchSize = Floor[Total Block Num/所需平均Block Num] = 435
由以上公式得到“maxBatchSize”的取值范围为[362,1088],设置初始值为435,然后根据吞吐量或者时延要求进行调整,具体场景请参见最佳实践。
- 计算“Total Block Num”的值。
- 计算“maxPrefillBatchSize”和“maxPrefillTokens”的值。
- “maxPrefillBatchSize”的计算方式请参见表2中“maxPrefillBatchSize”参数,建议设置为:“maxBatchSize”值的一半。
maxPrefillBatchSize = Floor[maxBatchSize/2] = 435/2 = 217
- “maxPrefillTokens”的值一般不超过8192,其计算方式请参见表2中“maxPrefillTokens”参数。
maxPrefillTokens = maxPrefillBatchSize * 数据集token id平均输入长度 = 217*186 = 40362
根据公式计算出的值大于8192,所以“maxPrefillTokens”的取值为8192。
- “maxPrefillBatchSize”和“maxPrefillTokens”的值一般根据“maxBatchSize”的值进行调整,其值不建议过大。
- “maxPrefillTokens”一般不用超过8192,若显存溢出可进一步适当调小“maxPrefillBatchSize”和“maxPrefillTokens”的值。
- “maxPrefillBatchSize”的计算方式请参见表2中“maxPrefillBatchSize”参数,建议设置为:“maxBatchSize”值的一半。
- 通过配置“maxPreemptCount”和“cpuMemSize”参数确认Swap抢占,请参见表2配置其建议值。
如果是显存受限场景,可开启“maxPreemptCount”(即设置为1或2),“cpuMemSize”可从5调整至40。
- 通过配置“supportSelectBatch”、“prefillTimeMsPerReq”和“decodeTimeMsPerReq”参数确认prefill/decode切换调度策略。
- 当严格要求首token时延时:
- 当严格要求吞吐量时(首token时延要求适中):
“supportSelectBatch”设置为“true”。
“prefillTimeMsPerReq”和“decodeTimeMsPerReq”按照模型实际平均首token时延和decode时延设置,也可参见表2使用推荐配置,然后根据下列场景进行调优。
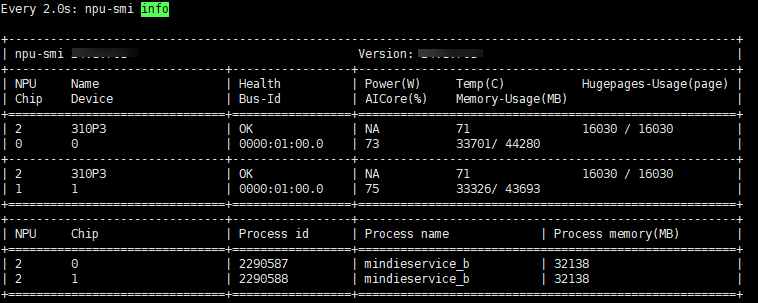
- 实际运行时,若测试场景是显存bound,可进一步调整“npuMemSize”的值。在调试过程中,重开一个窗口使用以下命令查看占卡情况,如果剩余空间还很大,可以调大npuMemSize的值,重复2~5后再次进行调试。
watch npu-smi info
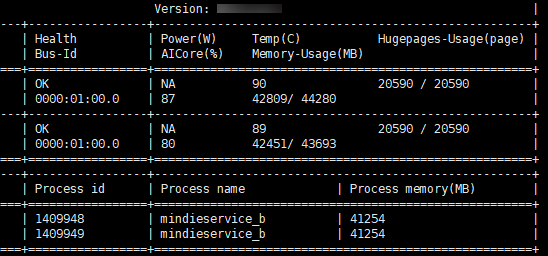
- 当npuMemSize的值不够大时,可以继续调大空闲值,如图2。
- 当npuMemSize的值过大时,则会报“Npu out of memory”错误,如图3所示。
- 根据“Npu out of memory”报错信息,将npuMemSize的值调小(比如在原来的值上减2,避免卡死),则可以达到最优npuMemSize的值。如图4,大概是占据95%卡的状态。
这时从性能返回结果可以看出来lpot会优于配置之前的值,并且GenerateSpeedPerClient也有很大的提升。



测试性能的数据集问题条数尽量超过1000条以上(可参考MindIE Benchmark支持的开源数据集CEval、MMLU,均在1000条以上),否则平均性能会有较大波动。