ST测试
概述
MindStudio提供了新的ST(System Test)测试框架,可以自动生成测试用例,在真实的硬件环境中,验证算子功能的正确性和计算结果准确性,并生成运行测试报告,包括:
- 基于算子信息库生成算子测试用例定义文件。
- 基于算子测试用例定义文件生成不同shape、dtype的测试数据和基于AscendCL的测试用例。
- 编译算子工程并将算子部署到算子库,最后在硬件环境中执行测试用例,验证算子运行的正确性。
- 自动生成运行报表(st_report.json)功能,报表记录了测试用例信息及各阶段运行情况。
- 根据用户定义并配置的算子期望数据生成函数,回显期望算子输出和实际算子输出的对比测试结果,验证计算结果的准确性。
生成ST测试用例定义文件
- 创建ST测试用例。有以下三种方式:
- 右键单击算子工程根目录,选择。
- 右键单击算子信息定义文件:{工程名} /cpukernel/op_info_cfg/aicpu_kernel/xx.ini,选择。
- 若已经存在了对应算子的ST Case,可以右键单击“testcases”目录,或者“testcases > st”目录,选择,追加ST测试用例。
- 在弹出的“Create ST Cases for an Operator”界面中选择需要创建ST测试用例的算子。如下图所示。
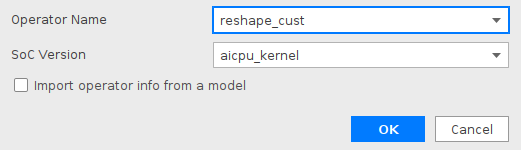
- Operator:下拉选择算子名称。
- SoC Version:下拉选择昇腾AI处理器的类型。若对AI CPU算子进行ST测试,默认选择aicpu_kernel。
- 若不勾选“Import operator info from a model”,单击“OK”后,会生成shape为空的算子测试用例定义文件。用户需要进行shape信息的配置,用于生成测试数据及测试用例,也可以根据需要进行其他字段的配置,每个字段的详细要求可参见AI CPU算子ST测试用例定义文件参数解释。
- 若用户勾选“Import operator info from a model”,选择包含算子的Tensorflow模型文件(*.pb)或者onnx格式的模型文件后,界面会显示获取到的模型文件的首层shape信息。
用户也可以在“Input Nodes Shape”中修改首层输入的shape信息。单击“OK”后,工具会自动根据首层shape信息dump出选择算子的shape信息,生成对应的算子测试用例定义文件。
此文件用于生成测试数据及测试用例,可以参见AI CPU算子ST测试用例定义文件参数解释进行相关字段的修改。

该功能需要在运行环境中安装TensorFlow框架和onnx库。若为Windows操作系统则需要在Windsows本地安装TensorFlow框架和onnx库。
- 若要将算子与标杆数据对比,需要定义并配置算子期望数据生成函数。
- 自定义实现算子期望数据生成函数。
算子期望数据生成函数需要开发者使用Python语言自行实现,用于在CPU上运行生成标杆数据。例如,开发者可以使用numpy等接口实现与自定义算子功能相同的函数。标杆数据用来与自定义算子生成数据进行对比,根据对比结果确定自定义算子精度。算子期望数据生成函数用python语言实现,在一个python文件中可以实现多个算子期望数据生成函数。该函数的输入、输出、属性与自定义算子的输入、输出、属性的Format、Type、Shape保持一致。
- 配置算子测试用例定义文件。
在算子测试用例文件中配置算子期望数据生成函数。有两种场景,分别为“Design”视图和“Text”视图下进行配置。
- 若在“Design”视图下,配置方法为在“Expected Result Verification”下的“Script Path”中选择算子期望数据生成函数的python文件所在路径。在“Script Function”中输入算子期望数据生成函数的函数名。

“Script Function”中可以输入算子期望数据生成函数的函数名,也可以为空。
- 当输入算子期望数据生成函数的函数名时,ST测试时会使用该函数名对应的函数生成标杆数据。
- 当输入为空时,会自动匹配Script Path路径下的python文件中与自定义算子同名的函数,用于ST测试时生成标杆数据。若无同名函数,则会提示匹配失败。
- 若在Text视图下,增加“calc_expect_func_file”参数,其值为算子期望数据生成函数对应的文件路径及算子函数名,如:
"calc_expect_func_file": "/home/teste/test_*.py:function", //配置期望算子文件
其中,/home/teste/test_*.py为算子期望数据生成函数的实现文件,function为对应的函数名称。算子期望数据生成函数文件路径和函数名称用冒号隔开。
示例:test_add.py文件为add算子期望数据生成文件,函数实现如下:
def calc_expect_func(input_x, input_y, out): res = input_x["value"] + input_y["value"] return [res, ]
用户需根据开发的自定义算子完成算子期望数据生成函数。测试用例定义文件中的全部Input、Output、Attr的name作为算子期望数据生成函数的输入参数。
- 若在“Design”视图下,配置方法为在“Expected Result Verification”下的“Script Path”中选择算子期望数据生成函数的python文件所在路径。在“Script Function”中输入算子期望数据生成函数的函数名。
- 自定义实现算子期望数据生成函数。
- 若要使用python脚本批量生成测试用例,采用fuzz方式生成测试用例。
- 实现fuzz测试参数生成脚本。该脚本可以自动生成测试用例定义文件中Input[xx]、Output[xx]、Attr内除了name的任何参数。
下面以随机生成shape和value参数为例,创建一个fuzz_shape.py供用户参考。该示例会随机生成一个1-4维,每个维度取值范围在1-64的shape参数,用于ST测试。
- 导入脚本所需依赖。
import numpy as np
- 实现fuzz_branch()方法,若用户自定义随机生成待测试参数的方法名,需要在算子测试用例定义文件中Fuzz Function字段配置自定义方法。
def fuzz_branch(): # 生成测试参数shape值 dim = random.randint(1, 4) x_shape_0 = random.randint(1, 64) x_shape_1 = random.randint(1, 64) x_shape_2 = random.randint(1, 64) x_shape_3 = random.randint(1, 64) if dim == 1: shape = [x_shape_0] if dim == 2: shape = [x_shape_0, x_shape_1] if dim == 3: shape = [x_shape_0, x_shape_1, x_shape_2] if dim == 4: shape = [x_shape_0, x_shape_1, x_shape_2, x_shape_3] # 根据shape随机生成x1、x2的value fuzz_value_x1 = np.random.randint(1, 10, size=shape) fuzz_value_x2 = np.random.randint(1, 10, size=shape) # 用字典数据结构返回shape值,将生成的shape值返回给input_desc的x1、x2和output_desc的y的shape参数。其中x1、x2、y测试用例定义文件输入、输出的name。 return {"input_desc": {"x1": {"shape": shape,"value": fuzz_value_x1}, "x2": {"shape": shape,"value": fuzz_value_x2}}, "output_desc": {"y": {"shape": shape}}}- 该方法生成测试用例定义文件Input[xx]、Output[xx]、Attr内除了name的任何参数,用户可自定义实现参数的生成方法,以满足算子测试的需求。
- 该方法的返回值为字典格式,将该方法生成的参数值以字典的方式赋值给算子进行st测试。返回的字典结构与测试用例定义文件中参数结构相同。
- 该方法生成的测试用例定义文件命名格式为Test_optype_001_ sub_case_001_format_type,format和type的取值为该case中第一个Output中的值。若case中没有Output,则文件名不包含后缀,文件名为Test_OpType_001_ sub_case_001。
- 导入脚本所需依赖。
- 将算子测试用例定义文件中需要随机生成的字段的值设为"fuzz"。
此时显示K-Level Test Cases配置项,包含Fuzz Script Path和Fuzz Case Num选项。
- 在Fuzz Script Path中输入fuzz生成测试参数的脚本的相对路径或绝对路径,如:“fuzz_shape.py”。
- 在Fuzz Case Num中输入利用fuzz脚本生成多少条测试用例,如:2000。
- (可选)在Fuzz Function中配置自定义的随机生成待测试参数的方法,若不配置默认使用 fuzz_branch方法。
- fuzz用例不采取正交生成,因此在该场景下算子测试用例定义文件中各字段的取值需唯一。
- 实现fuzz测试参数生成脚本。该脚本可以自动生成测试用例定义文件中Input[xx]、Output[xx]、Attr内除了name的任何参数。
- 修改Case信息后,单击“Save”,修改会保存到算子测试用例定义文件。
算子测试用例定义文件存储目录为算子工程根目录下的“testcases/st/OpType/aicpu_kernel”文件夹下,命名为OpType_case_timestamp.json
请勿更改算子测试用例定义文件命名格式和将其他文件的以该命名格式保存在算子工程根目录下的“testcases/st/OpType/aicpu_kernel”文件夹下。否则会导致文件解析错误。
运行ST测试用例
- (可选)修改工程目录下的“cpukernel/CMakeLists.txt”文件。
- 运行ST测试用例。右键单击生成ST测试用例定义文件中生成的ST测试用例定义文件(路径:“testcases > st > OpType > aicpu_kernel > xxxx.json”),选择“Run ST Case 'xxx'”。
表1 运行配置信息 参数
说明
Name
运行配置名称,用户可以自定义。
Test Type
选择st_cases 。
Execute Mode
- Remote Execute:远程执行测试
- Local Execute:本地执行测试
说明:
Local Execute不支持Windows操作系统。
Deployment
当Execute Mode选择Remote Execute时,deployment功能,详细请参见Deployment,可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。
CANN Machine
CANN工具所在设备deployment信息。
说明:该参数仅支持Windows操作系统。
Environment Variables
- 在文本框中添加环境变量。
多个环境变量用英文分号隔开。
- 单击文本框后的图标,在弹出的对话框中填写。
- 在Name中输入环境变量名称:PATH_1。
- 在Value中输入环境变量值:路径1。
勾选Instead system environment variables可以显示系统环境变量。
Operator Name
选择需要运行的算子。
SoC Version
配置 昇腾AI处理器的类型。
说明:昇腾AI处理器类型为Atlas 推理系列产品系列时,请用户根据实际情况选择具体的类型。
Executable File Name
下拉选择需要执行的测试用例定义文件。
若对AI CPU算子进行ST测试,测试用例文件前有(AI CPU)标识。
Toolchain
工具链配置器,根据已安装的CANN包预置架构一致的自定义Toolchain,支持本地和远程编译功能。
可单击“Manage toolchains……”自定义配置Toolchain,配置详情请参见Toolchains。
Case Names
选择运行的Case Name。
说明:默认全选所有用例,可以去除勾选部分不需要运行的用例。
Enable Auto Build&Deploy
选择是否在ST运行过程中执行编译和部署。
Advanced Options
高级选项。
ATC Log Level
选择ATC 日志级别。
- INFO
- DEBUG
- WARNING
- ERROR
- NULL
Precision Mode
精度模式。
- force_fp16
- allow_mix_precision
- allow_fp32_to_fp16
- must_keep_origin_dtype
Device Id
设备ID,设置运行ST测试的芯片ID。用户根据使用的AI芯片ID填写。
Error Threshold
配置自定义精度标准,取值为含两个元素的列表:[val1,val2]
- val1:算子输出结果与标杆数据误差阈值,若误差大于该值则记为误差数据。
- val2:误差数据在全部数据占比阈值。若误差数据在全部数据占比小于该值,则精度达标,否则精度不达标。
取值范围为[0.0,1.0]。
Generate Error Report
生成比对不一致数据的报表。
该选项默认开启,针对比对失败的用例,将算子期望数据与实际用例执行结果不一致的数据保存在{case.name}_error_report.csv文件中。使用“Generate error report”功能前,需要指定算子期望数据生成函数自定义脚本,请参见3。
- Host侧运行用户设置。
Host侧运行用户需在deployment中添加,并且该用户必须为HwHiAiUser属组。配置deployment请参见Deployment。
- 在运行环境上有两种方式配置相关组件的环境变量。
- 在远程设备上配置环境变量。
针对Ascend EP,需要在硬件设备的Host侧配置安装组件路径的环境变量。
以Host侧运行用户在~/.bashrc文件中配置runtime或comlpiler、driver组件的安装路径。若没有配置,请参考以下操作。- 修改~/.bashrc文件,在文件中添加如下内容。
# Ascend-cann-toolkit环境变量(请根据实际路径修改) source $HOME/Ascend/ascend-toolkit/set_env.sh - 使环境变量生效。
source ~/.bashrc
- 修改~/.bashrc文件,在文件中添加如下内容。
- 在Environment Variables中添加环境变量。
在运行ST测试用例中运行的窗口中Environment Variables参数进行环境变量配置。
- 在文本框中添加环境变量。
ASCEND_DRIVER_PATH=/usr/local/Ascend/driver; ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/latest; ASCEND_AICPU_PATH=${ASCEND_HOME}/<target architecture>-linux; 若远程设备为推理环境: LD_LIBRARY_PATH=${ASCEND_DRIVER_PATH}/lib64:${ASCEND_HOME}/lib64:$LD_LIBRARY_PATH; 若远程设备为训练环境: LD_LIBRARY_PATH=${ASCEND_DRIVER_PATH}/lib64/driver:${ASCEND_DRIVER_PATH}/lib64/common:${ASCEND_HOME}/lib64:$LD_LIBRARY_PATH;请根据driver和CANN的实际安装路径,远程操作系统的使用架构修改环境变量内容。
- 也可以单击
 ,在弹出的对话框中填写。
,在弹出的对话框中填写。
分别在Name中输入环境变量名称,在Value中输入环境变量值。
- 在文本框中添加环境变量。
- 在远程设备上配置环境变量。
- 单击“Run”。
MindStudio会根据算子测试用例定义文件在算子根目录“testcases/st/out/<operator name>”下生成测试数据和测试代码,并编译出可执行文件,在指定的硬件设备上执行测试用例。运行成功后会打印对比报告及保存运行信息。
- 将执行结果和与标杆数据对比报告打印到Output窗口中。
- 在算子根目录“testcases/st/out/<operator name>”下生成st_report.json文件。st_report.json文件信息含义请参见表2。
表2 st_report.json报表主要字段及含义 字段
说明
run_cmd
-
-
命令行命令。
report_list
-
-
报告列表,该列表中可包含多个测试用例的报告。
trace_detail
-
运行细节。
st_case_info
测试信息,包含如下内容。
- expect_data_path:期望计算结果路径
- case_name:测试用例名称
- input_data_path:输入数据路径
- planned_output_data_paths:实际计算结果输出路径
- op_params:算子参数信息
stage_result
运行各阶段结果信息,包含如下内容。
- status:阶段运行状态,表示运行成功或者失败
- result:输出结果
- stage_name:阶段名称
- cmd:运行命令
case_name
-
测试名称。
status
-
测试结果状态,表示运行成功或者失败。
expect
-
期望的测试结果状态,表示期望运行成功或者失败。
summary
-
-
统计测试用例的结果状态与期望结果状态对比的结果。
test case count
-
测试用例个数。
success count
-
测试用例的结果状态与期望结果状态一致的个数。
failed count
-
测试用例的结果状态与期望结果状态不一致的个数。