概述
文本行识别技术运用最广泛的是使用卷积神经网络和循环神经网络的组合框架,模型称为卷积-递归神经网络(Convolutional Recurrent Neural Network,CRNN)。本案例提出的CANN模型是对经典CRNN模型的优化,用自注意力机制代替了原来的RNN。读者可在本案例的基础上基础上,复现其他深度学习模型,探索并实现OCR、机器翻译等更多复杂应用。
案例简介
本案例将CANN模型在Atlas 200DK开发者套件上进行了移植与部署,完成了文本的端到端的识别。
系统总体设计
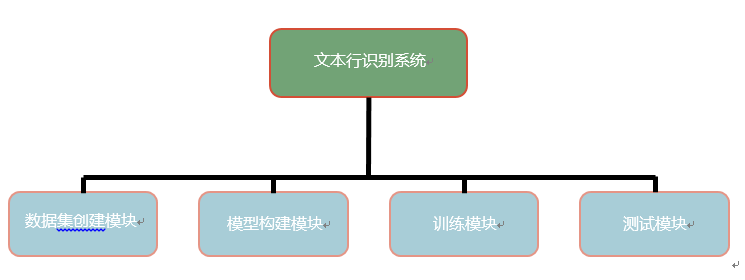
1. 数据集创建:数据集创建用于创建字符表,对原始数据进行预处理,并且生成训练数据集和测试数据集。案例用到的数据集为中文作文数据集SCUT-EPT,包括常见汉字、数字、特殊字符、标点符号等。
2. 模型构建:主要用来搭建文本识别的CANN等模型。模型构建依赖很多超参数,并且需要知道字符表大小,还需要一些基础模块,这些模块由Modules类提供。
3. 训练:训练模型包含数据检查和模型训练两个主要功能。训练过程中需保存训练好的模型,训练程序通过检查模型在验证集上的正确率保存正确率最高的模型。
4. 测试:测试模块用于测试训练好的模型在测试集上的正确率。
模型介绍
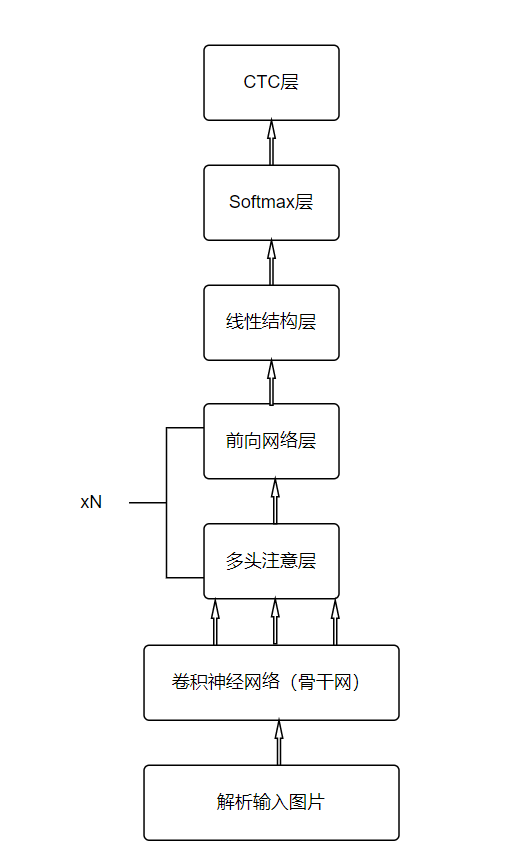
本案例使用的CANN模型是对经典CRNN模型的优化,用自注意力机制代替原来的RUN。由于自注意力机制的运算只需要用矩阵乘法即可实现,因此训练和预测速度都会快于RNN。RNN在训练和推理时,每个时刻的隐层状态都由上一个时刻的隐层状态和当前时刻的输入决定,本质上是一个串行的过程,而自注意力机制在计算每个时刻的隐层状态时,可以并行地计算所有时刻的隐层状态,因此可以减少计算时间。
CANN模型主要由一个卷积神经网络和若干层自注意力机制加全连接层组成,其中卷积神经网络为骨干网,自注意力层用于提取序列特征,每个自注意力层后面跟了一个全连接层,用于整合多个头的特征。CANN模型网络结构如下图所示。
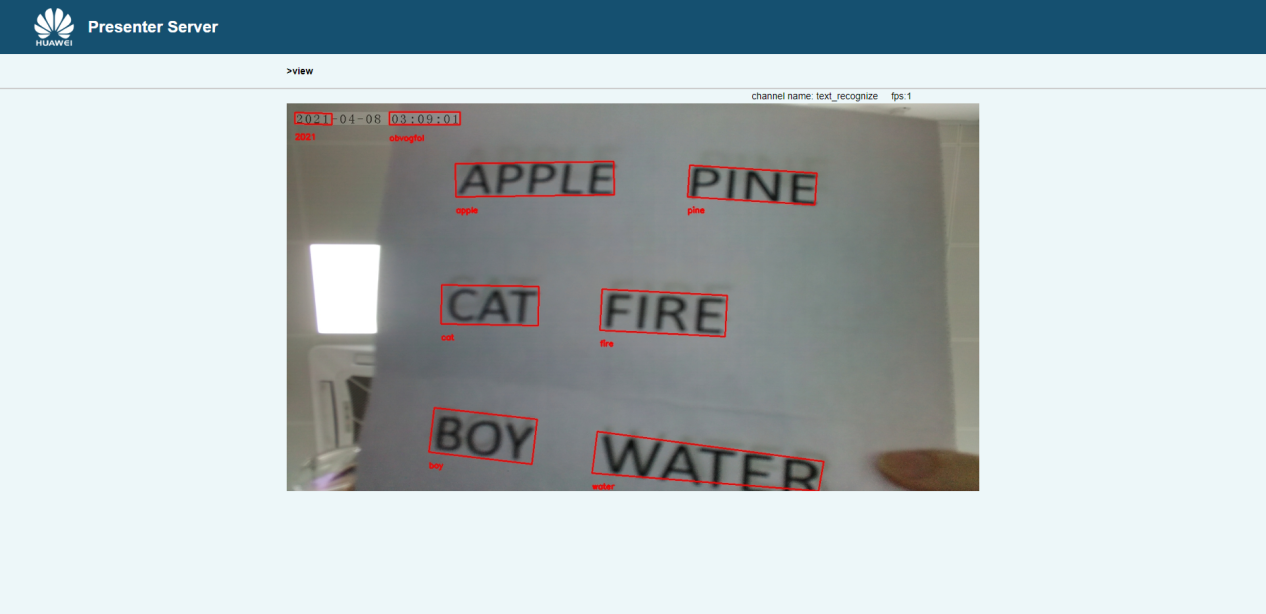
效果展示