
本项目实现的超分辨率图像算法模型介绍
SRCNN 和 FSRCNN:
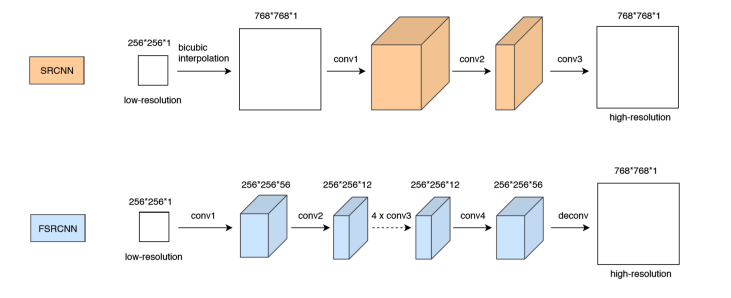
经典的超分辨网络 SRCNN 与 FSRCNN 的模型如图所示:
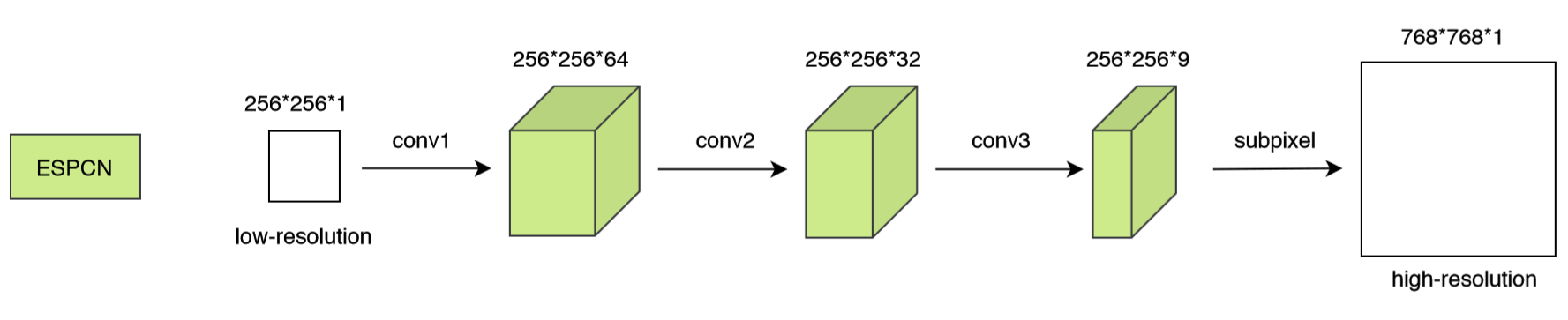
ESPCN的模型如图所示:
算法模型实现
超分辨率算法转移系统搭建
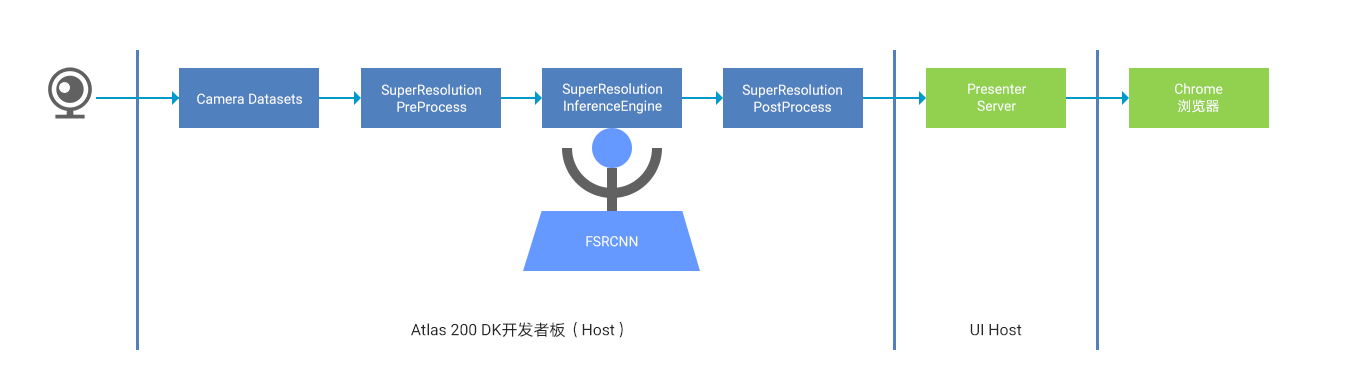
在Atlas 200 DK硬件平台上搭建了两个图像超分辨率转换系统:基于图像文件输入的转换系统和基于摄像头图像数据输入的转换系统,分别如图所示。

在基于图像文件输入的超分辨率图像转换系统中,使用图像数据作为输入。在从文件中读取图像数据后,经过预处理送入超分辨率图像算法模型进行放大,然后保存在本地的存储设备上,具体步骤为:
1. ImageDatasets 模块利用 OpenCV 读取低分辨率图像数据。对于 SRCNN 模型,此处需要继续使用 OpenCV 进行 bicubic 插值放大,FSRCNN 和 ESPCN 则不需要。
2. 在 SuperResolutionPreProcess 预处理模块中,使用 EZDVPP 对图片进行 resize 预处理,使得图片的分辨率与模型输入的分辨率(例如 256 x 256)相匹配。(实际上,模型输入的分辨率最好与输入图像的分辨率相同,避免此处的 resize)。
3. SuperResolutionInferenceEngine 会加载已训练好的 SRCNN、FSRCNN 和 ESPCN 超分辨模型及其权值,对图片做推理,得到宽高放大后的图像数据。
4. SuperResolutionPostProcess 对接收到的灰度图像进行后处理,最后使用 OpenCV 将图像进行保存。
而在基于摄像头图像输入的转换系统中, 使用Atlas 200 DK外接的树莓派摄像头获取的低分辨率视频数据作为输入,利用超分辨网络模型进行实时的推理放大,并将得到的高分辨率视频数据推送到 Web UI 进行显示。其具体步骤为:
1. CameraDatasets模块与Camera驱动进行交互,从摄像头获取低分辨率(例如352 x 288) 的 YUV420SP 格式的视频数据。(Atlas 200 DK 开发者套件(型号:3000) 提供了一套帮助开发者轻松获取摄像头图像的 API 接口媒体库,详细的接口使用方法可参考《HiAI Media API》)。
2. 在 SuperResolutionPreProcess 预处理模块中,使用 EZDVPP 对每帧图像进行 resize预处理,使得图像的分辨率与模型输入的分辨率(例如 256 x 256)相匹配。(实际上,模型输入的分辨率最好与摄像头分辨率 352 x 288 相同,避免此处的 resize。Ascend DK提供了媒体数据处理接口,帮助开发者更方便的对图片进行预处理,详细的接口使用方法可参考《Ascend DK API》)。
3. SuperResolutionInferenceEngine 会加载已训练好的超分辨模型及其权值,对图片做推理,得到宽高放大后的灰度图像数据。
4. SuperResolutionPostProcess 对接收到的灰度图像进行后处理,使用 EZDVPP 将图片依次转化为 YUV420 和 JPEG 格式,然后通过调用 Presenter Agent 的 API 发送到 UI Host上部署的 Presenter Server 服务进程,Presenter Agent Api 的详细使用方法可参考《Ascend DK API》。
5. Presenter Server 将接收到的图像推送给 Web UI(Presenter Agent)。
6. 用户可通过 Chrome 浏览器访问 Presenter Server,实时查看超分辨放大后的视频数据。
超分辨率算法模型的实现与移植
法模型的实现和移植步骤为:
1. 首先,基于 Caffe 框架,搭建相应的超分辨率算法模型的训练框架,并完成模型的训练,得到全精度的算法模型。
2. 其次,完成计算机模型到 Ascend 310 模型的转换,使用 Matrix 提供的模型管家接口将 Caffe 模型转换为 Ascend 310 AI处理器支持的模型,如图所示。
3. 然后,将转换后的模型在 SuperResolutionInferenceEngine 中运行,并验证图像转换后的效果和性能。
4. 采用模型量化、剪枝等方法优化算法模型的性能。
在移植模型的过程中,在图像输入大小、图像预处理和 PSNR 计算等方面需要注意以下的一些实现细节。
1.图像输入格式
由于进行模型推演之前使用了 DVPP 模块进行处理,因此此处的 input format 需要指定为 YUV420SP 格式。模型的输入数据范围为[0, 1],此处需将[0, 255]的数据乘上 1/255进行归一化。
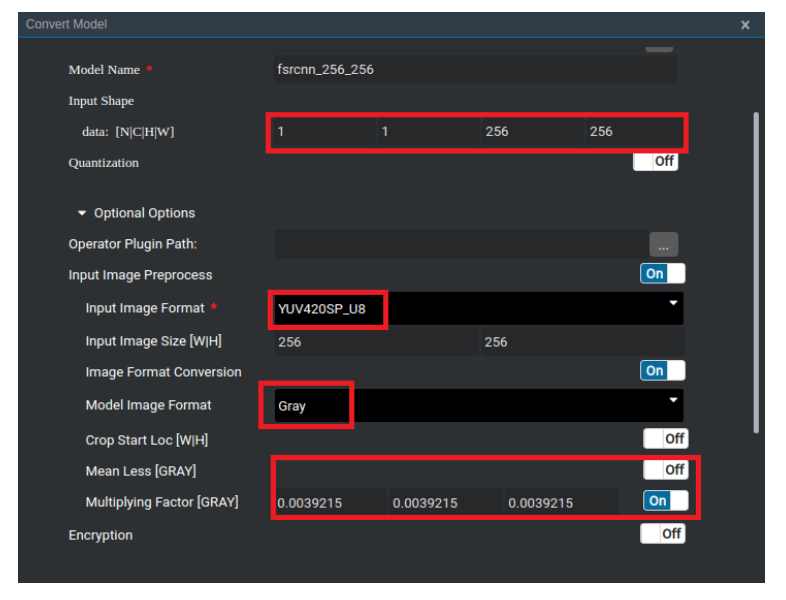
2. 图像的预处理处理步骤
由于软件平台目前存在的一些限制如 DVPP 的输入不支持 Gray、转换模型时 Input Image Preprocess 的输入也不支持灰度。因此,当输入图像是灰度图的时候,需要进行特殊处理,先将其构造成 B=G=R=Gray 的彩色图像,再进行后续处理。数据格式的转换可概括为:Gray -> BGR -> YUV -> Gray:
Gray -> BGR
使用 OpenCV 以 BGR 的数据格式导入图片,当图片实际上为灰度格式时,OpenCV 会自动生成 B=G=R=Gray 的彩色图像数据,完成这一步转换。
BGR -> YUV
使用 EZDVPP 进行图像处理,将 BGR 格式转换为 YUV420SP 格式。
YUV -> Gray
在转换模型时进行该设置,将图像转换成灰度格式进行推演。
3. 反卷积层处理
在搭建 FSRCNN 模型的过程中发现,对于 Deconv 反卷积层,当 outputH/W 与 inputH/W不成整数倍的时候,Deconv 层的运行速度非常慢。例如,当 kernel_size=9, stride=3, pad=4,inputH/W=256 时,outputH=3*256-2=766,此时整个 FSRCNN 模型推演耗时超过几百毫秒。修改 pad 为 3 之后,outputH=3*256=768,模型的运行速度极大提升,耗时缩短为 10 毫秒以下。因此为了提升模型实现的速度,要确保相应的模型参数之间的匹配。
4、图像在 Web 界面上的显示
在使用摄像头获取数据作为输入的样例中,网络放大得到的灰度图像需要发送至Presenter Server 进行展示。此处采取的处理步骤为:
Gray -> BGR
根据网络输出的灰度图像,新建 B=G=R=Gray 的彩色图像数据。
BGR -> YUV
使用 EZDVPP 将 BGR 数据转换为 YUV 格式。
YUV -> JPEG
使用 EZDVPP 将 YUV 数据转换为 JPEG 格式,调用 API 发送至 Presenter Server 端。
在转换模型时进行该设置,将图像转换成灰度格式进行推演。
Server 端接收到数据后进行解码等一系列后续操作,最终在 Web 界面上绘制出得到的灰度图像数据(实际上,绘制的是 RGB 三个分量相等的彩色图像)。
超分辨率算法实现的结果与性能
基于图像文件输入的图像超分辨率转换后的结果
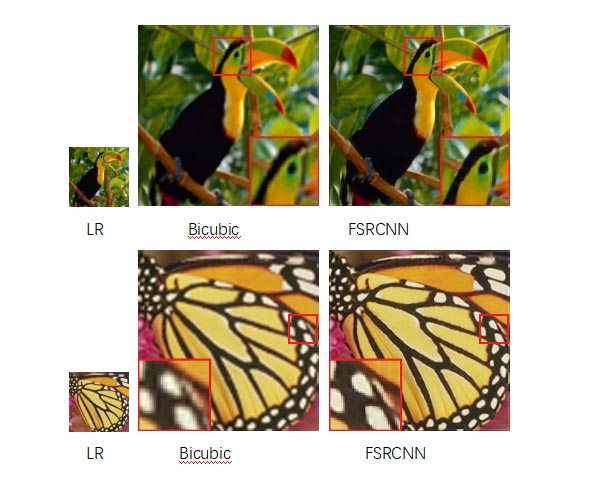
FSRCNN 超分辨网络在 Atlas 200 DK 上运行得到的结果
使用 Set5 数据集在Atlas 200 DK上进行测试得到的 PSNR(dB)
超分辨率算法模型的实现 PSNR 结果

基于摄像头图像数据输入的图像转换处理结果

基于摄像头数据输入的图像超分辨率转换系统实现结果
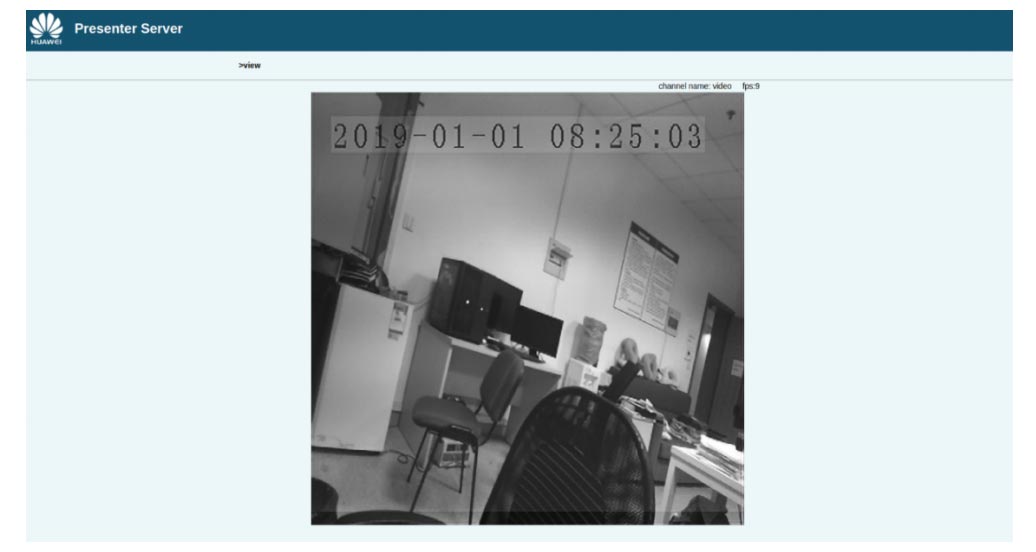
Web 界面展示使用 FSRCNN 超分辨网络进行放大得到的结果
本项目的硬件平台
本项目使用的硬件平台为Atlas 200 DK 开发者套件(型号:3000)和树莓派摄像头。
其连接如图所示:
