
项目意义
目前工业界通用的人像分割主要采用绿屏技术,需要专门的绿屏设备及环境,不利于普通用户的广泛使用。传统的人像分割使用背景减除法,严重依赖人像和背景的色差。在颜色相近的区域会产生不稳定的分割结果。并且具有对环境的高度依赖性。而基于简单神经网络的人像分割方法具有较低的精度,会在分割时产生人像关键部位的缺失,不完整。复杂的神经网络方法由于其较高的复杂度通常难以满足实时高效的需求。
本项目基于速度快、精度高的Atlas 200 DK,实现了借助摄像头对人像视频进行实时检测和分割,并对其背景进行替换,满足了在实际场景下用摄像头进行人像视频的拍摄、实时分割和背景替换的需求。
概述
该项目使用Atlas 200 DK外接摄像头捕获人像图片,经过PortraitNet网络输出与输入相同大小的逐像素分割结果,对每个像素点分别进行预测,判断其为背景还是人像,而从通过对人像的分割达到背景替换或虚化的目的。
模型设计
PortraitNet主要分为两个模块:encoder模型与decoder模块,网络结构如图1所示。encoder部分对输入的三通道图像进行特征提取,decoder部分对特征图进行上采样得到与输入图像相同大小的分割结果。
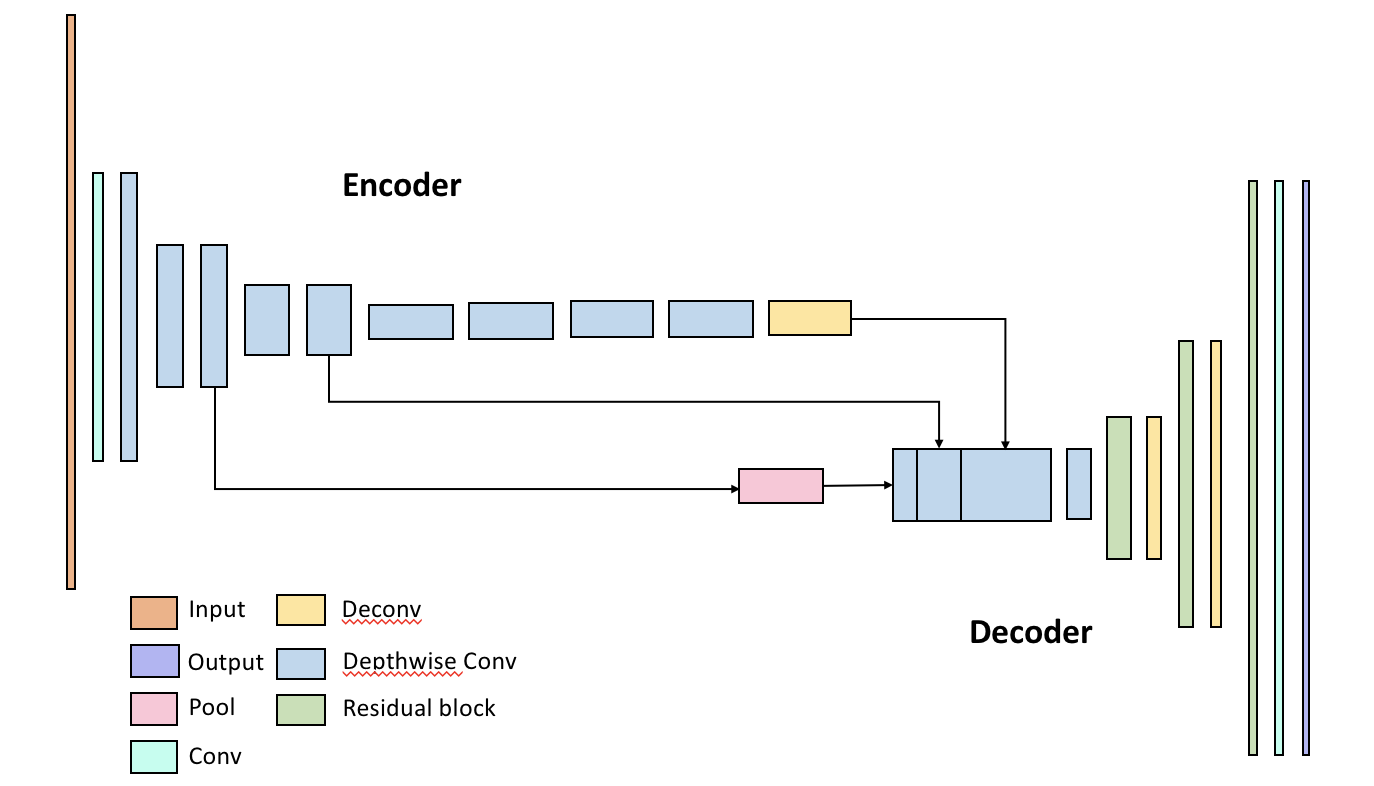
图1 PortraitNet网络模型结构图
Encoder部分
在encoder部分,主要利用深度可��离��积来降低网络的参数量,提高网络的运行速度。为了减少特征提取部分的运行时间,我们只使用了10层卷积层来进行特征提取,最大下采样倍数为16倍。为了充分利用模型的特征提取能力,在使用较少卷积层的情况下提高分割准确率结果,考虑将不同分辨率的特征图在channel维度进行拼接进行后续的decoder操作。由于在encoder部分分别进行了2倍、4倍、8倍、16倍的下采样,以下采样8倍的特征图的尺寸为基准,将下采样4倍、8倍、16倍的特征进行channel维度的拼接,由于不同下采样倍数的特征图分辨率大小不同,在channel维度上拼接时需要对下采样4倍的特征图进行核为2×2的max pool操作,对下采样16倍的特征图进行2倍的上采样操作,用反卷积层实现,这样可以将特征图的尺寸对齐为下采样8倍的特征图的尺寸,因为可以在channel维度上进行特征图拼接,拼接后的特征图channel数为896,在该融合后的特征图后使用1×1的卷积将通道数从896降低为128,降低模型的复杂度。
Decoder部分
Decoder部分相对较为简单,主要涉及两个操作,一个是对特征图进行上采样的反卷积层,每次扩大倍数为2倍,由于encoder部分下采样倍数为8倍,故共需三层反卷积层将特征图上采样为与输入图像相同的尺寸。在反卷积层之间,添加Residual block来进行过渡,采用Residual block的出发点是希望能更好的保存图像的边缘信息。其中Residual Block的结构如图2所示。
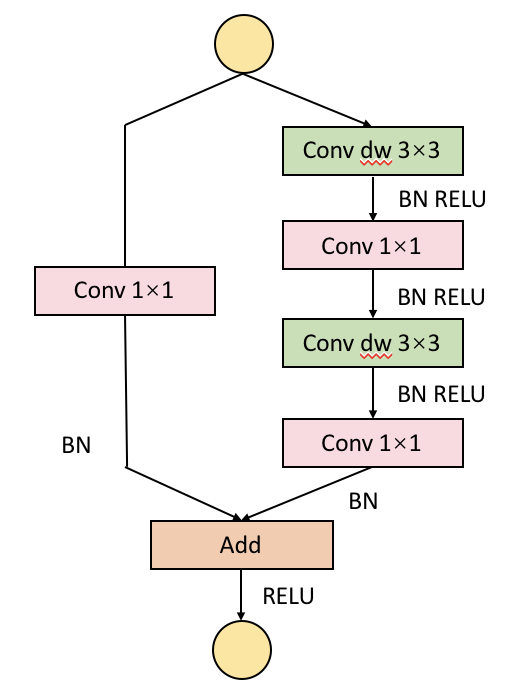
图2 Residual Block结构图