
项目开发目的和意义
书写汉字是几乎所有国人的最自然技能之一。日常生活中有很多场景需要对写在纸上的汉字进行识别或者录入电脑。如下图是一位同事咨询该字如何发音,如果能够识别它就能达到认识它的目的。
本项目是属于手写体文字识别应用,旨在华为Atlas200DK上实现通过拍照所书写汉字进行识别的系统。该系统能够对写在纸上的多个汉字,使用摄像头捕获视频/图像,实时检测手写文字区域并给出识别类别。该系统与用户交互的部分包括从摄像头图像采集、模型推断到输出结果的完整流程。其中模型推断部分采用的是深度神经网络,目前深度学习在文字识别方面有着广泛的应用,多分类问题是其中重要的一类。然而,深层网络模型的结构通常很复杂,对于一般的多类别分类任务,所需的深度网络参数通常随着类别数量的增加而呈现超线性增长。本项目需要识别字库中字的类别数高达3,755类,而且模型推断的速度在整个识别流程中占据较大部分,所以其速度对于用户体验至关重要。如何研究一个速度快、模型小、实用性强的方案变得极具挑战性。本项目的单字版在华为Atlas200DK上实现了借助摄像头对少量书写汉字的实时检测和识别,具有完整性、代表性和实用性,满足了在实际场景下用摄像头进行文字的拍照感知、实时检测和识别的需求。
总体设计
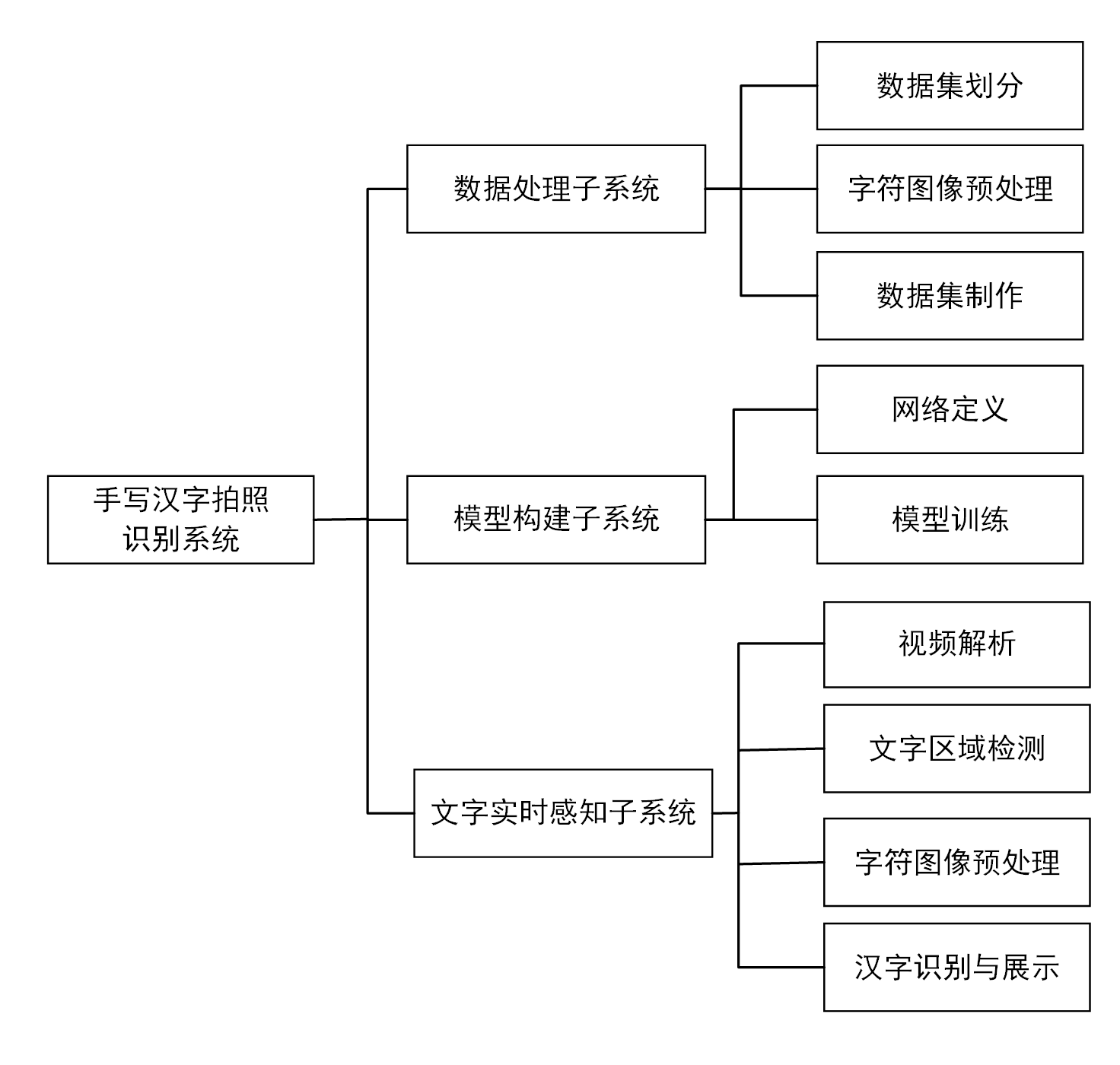
系统可以划分为数据处理、模型构建和训练、文字识别等三个主要子系统,各子系统相对独立,但存在数据关联。其中数据处理包括汉字集划分、新数据集制作、图像增强等;模型构建和训练包括网络构建、模型训练等;文字识别包括单字检测和识别。为了说明各模块之间的结构关系,细化的整体结构图如下图所示。系统整体功能结构图
算法设计
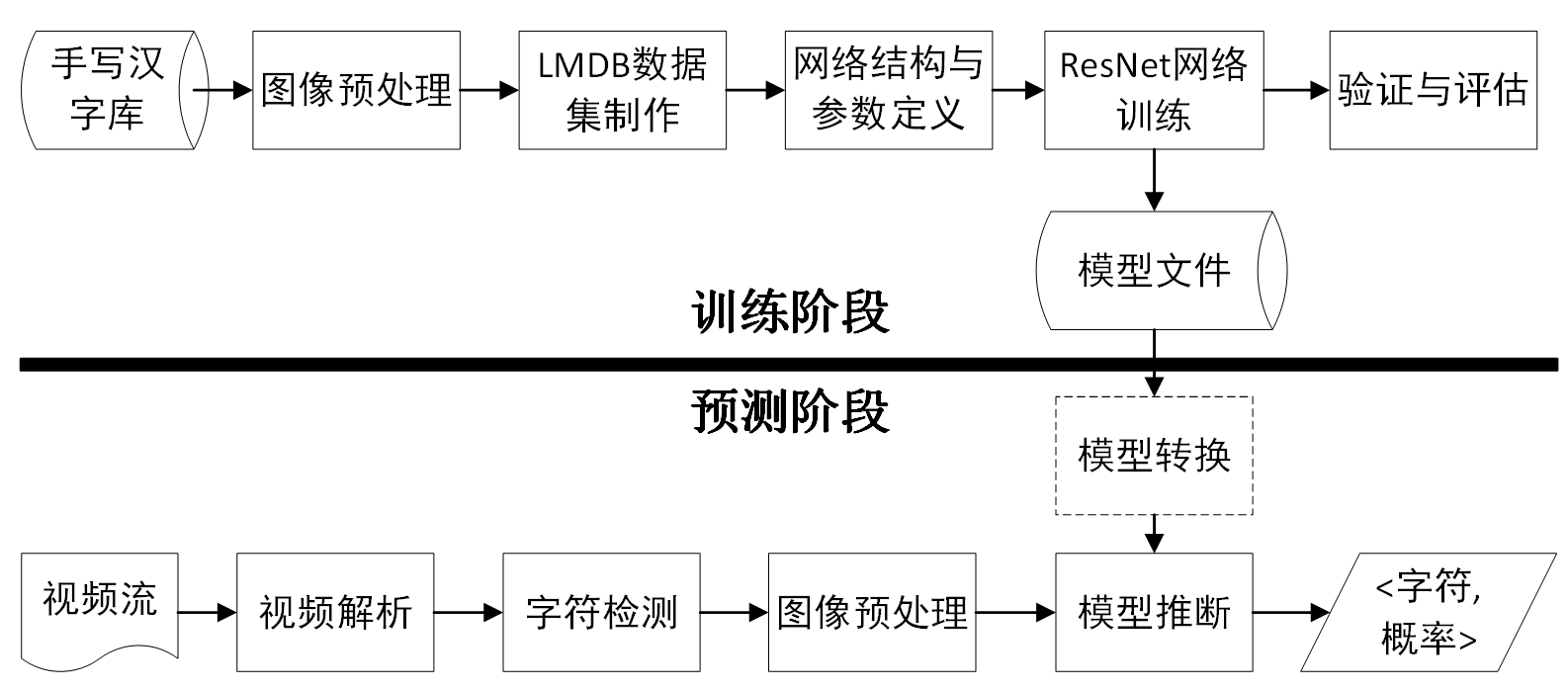
整个算法包括训练和推断两个阶段。训练阶段在HITHCD-2018数据子集上借助Caffe生成定制版ResNet模型。推断阶段包括摄像头图像采集、字符检测、图像预处理、文字识别等模块后给出输出反馈,具体流程见下图所示。
系统流程
手写数据集
使用HITHCD-2018数据集的子数据集。HITHCD-2018是哈尔滨工业大学收集的、用于手写汉字识别(HCCR)的大型数据库,有超过5346书写者书写,是目前规模最大、字类最多的数据库(Tonghua Su et al. HITHCD–2018: Handwritten Chinese Character Database of 21K-Category, ICDAR, 2019)。我们使用子数据集,共563,250个样本,它覆盖了3755个类别的国标第一级字符(GB2312-1980 Level 1)。其中训练数据中为每个字符类提供了120个样本,测试集每类提供30个样本,后者可以用于超参数验证。数据集制作
在caffe中经常使用的数据类型是lmdb,不是常见的jpg,jpeg,png,tif等格式。比起单张图片,它具有I/O效率高、支持多线程并发读写、节省内存、语义完全符合ACID性等特点。由于本项目所用HITHCD数据集存储形式为gnt,我们需要对其进行格式转换,输出成一个lmdb库文件。gnt的存储形式如下图所示,前4个字节是当前图片所占的字节数,紧跟的2个字节是图片对应标签的ASCII编码,再往后4个字节分别是宽和高,最后是图片具体信息,如此往复。gnt文件存储情况

生成lmdb需要准备的条件如下:
- 编译好caffe并编写好convert_imageset。
- 被转换gnt文件,注意需要为所示标准格式。
- 一个标签文件lexicon3755.txt。
- 用命令编辑好的shell脚本create-lmdb.sh。
下面依次进行说明。
该部分核心代码封装在convert_imageset程序中,主要实现gnt转lmdb。考虑到现有caffe框架仅提供jpg,png等格式转lmdb,若以此制作数据,需将gnt转为单张图片过渡,存储和I/O效率成本较高,我们对其进行了重写,其流程图所示。
制作LMDB流程图
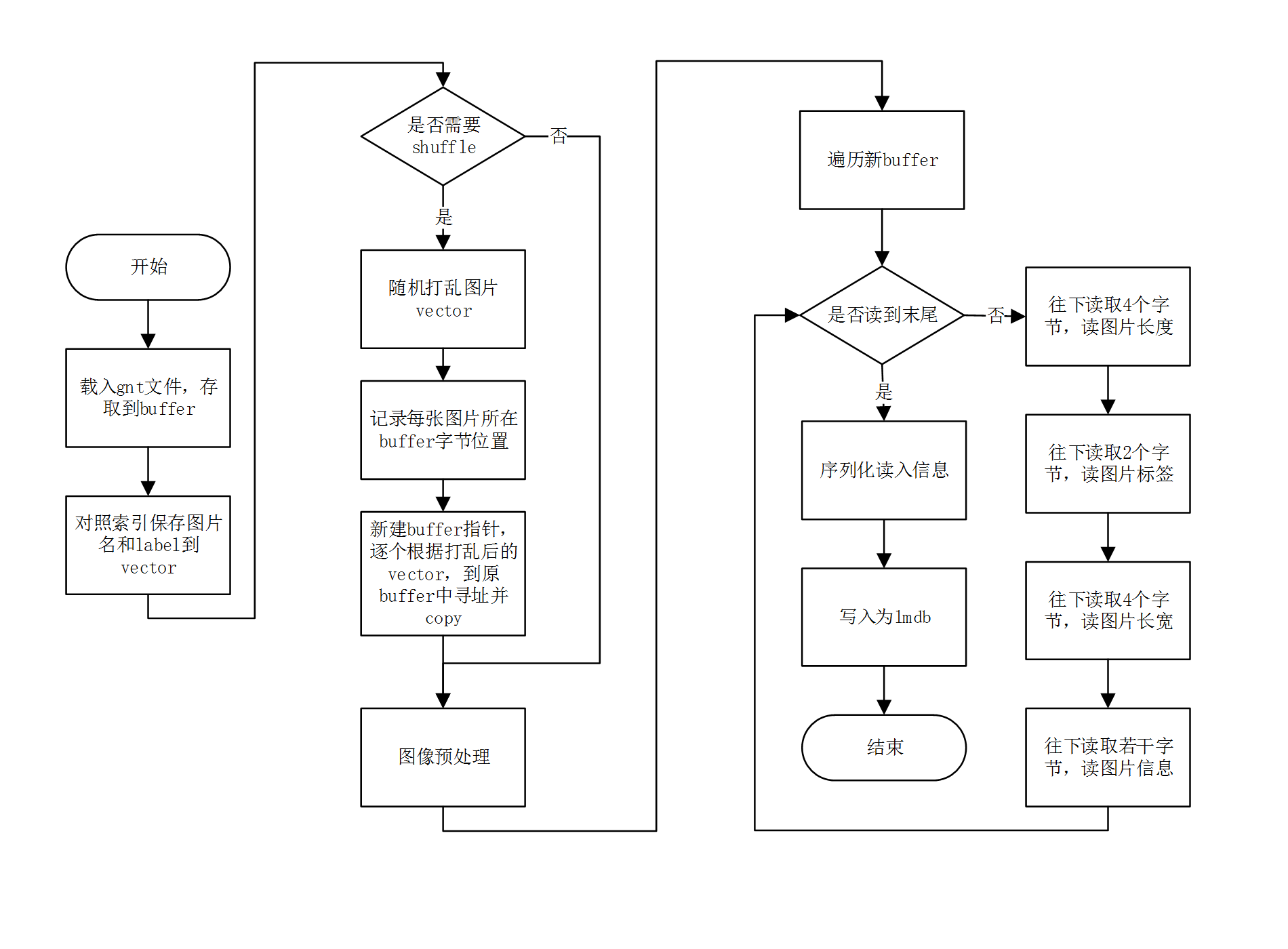
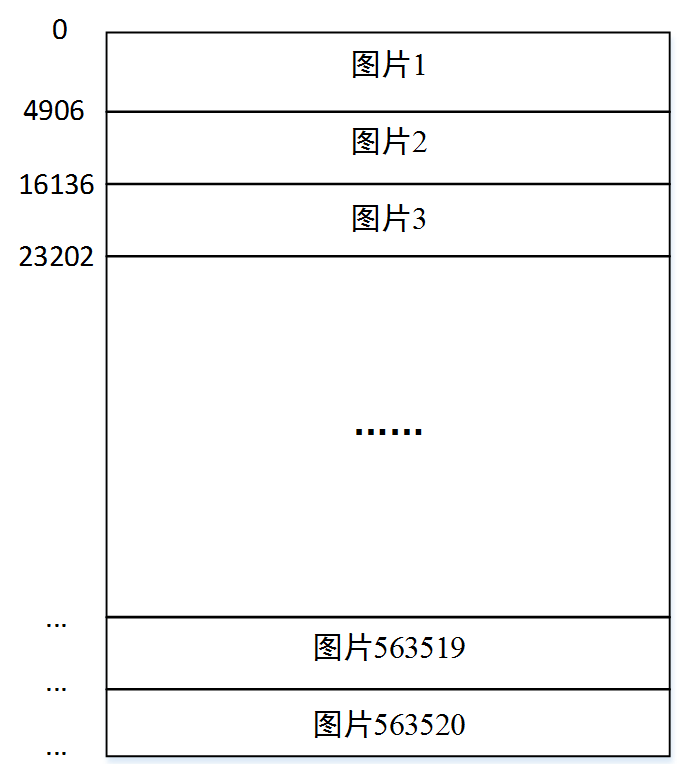
具体的,主要是解析gnt文件,并将其转存为lmdb格式,供后续caffe卷积神经网络网络训练使用。首先,载入gnt文件,将其保存为char*buffer。接下来将图片名(从1到563250)和label(one-hot编码格式)存取到std::vector<std::pair<std::string, int>>中。进一步考虑是否需要打乱训练样本,若需要,则打乱vector并记录每张图片所在字节位置。记录字节需新建start数组,维度为样本数n+1,情况如图所示,start[0]=0,start[1]=4906,start[2]=16136,start[3]=23202,…,start[n]=gnt所占字节数。据此根据打乱后的vector顺序,再逐个到start数组中寻址,将原有图片信息copy到新buffer指针中,如此往复,直到读到原buffer指针末尾。
解析完gnt后,需经过图像预处理,并且由于部署环境(atlas 200dk)仅支持彩色图像输入,因此图片应转为rgb存入lmdb。随后遍历新buffer,判断是否读到末尾。若否,则往下读取4个字节的图片长度信息,再读取2个字节的图片标签信息(以ASCII码存储),紧接着是4个字节的图片长宽信息,最后是图片的实际内容。以下图1为例,所占字节为4906,其尺寸为68*72,因图片总长、label、长宽占了共4+4+2=10个字节,总计4896+10=4906字节。这样循环往复,一直读到文件末尾。读取完毕后,还需要对读入信息序列化,写入为lmdb格式,即完成了整个制作流程。
start数组保存信息示意图
lexicon3755.txt为第0-3754类汉字的label,按行保存即可,如图所示。
lexicon3755.txt示意图

最后,编写shell文件create_lmdb.sh,用来生成lmdb文件3755_train_RGB/data.mdb和3755_test_RGB/data.mdb,内容如下所示。其中shuffle设置是否打乱样本,默认为不打乱,resize_height和resize_width设置resize的图片长宽,默认保持原图大小不变,lexicon3755.txt为字典路径,hwtrn.gnt为输入gnt文件路径,./3755_train_RGB为输出lmdb路径。
#!/usr/bin/en sh
convert_imageset --shuffle=true –resize_height=112 –resize_width=112 \
lexicon3755.txt \
hwtrn.gnt \
./3755_train_RGB\
Pause图像预处理
图像的亮度、对比度等属性对识别的影响很大,书写的同个汉字在不同环境下也有不同。然而,在识别问题中,这些因素不应该影响最后的识别结果。为了尽可能减少无关因素的影响,我们对原始数据进行了预处理和增强,提高了网络的泛化能力。该部分流程如下图所示:
数据增强流程

大律法二值化主要是利用最大类间方差,将图片分为前景和背景两部分。本项目中,它的目的是为了保持手写汉字灰度不变,将背景统一为纯白底色,增加识别的鲁棒性。调用threshold(img, img, 0, 255, THRESH_TOZERO | THRESH_OTSU)函数,可实现项目需求。如示意图所示。
大律法二值化效果图(左为原始图像,右为大律法校正图像)

灰度均衡法由Cheng-Lin Liu, Fei Yin等人在“Online and offline handwritten Chinese character recognition: Benchmarking on new databases”中提出,目的是为了尽可能使得训练样本汉字灰度值相近,提高识别的准确率。对于给定的像素值在0到255之间的汉字样本,首先进行灰度均值计算,若大于110,即样本图片更接近白色、笔画颜色偏浅,则对其进行笔画增粗、增黑,其前后效果如图所示。
灰度均衡效果图(左为原始图像,右为灰度均衡校正图像)

对于给定的caffe网络,训练的样本需为统一尺寸。因此,在预处理过程中,还需要对汉字进行居中padding和大小归一化。该部分的主要步骤为:1.根据长宽比,将汉字resize到尽可能接近目标尺寸;2.采用邻接线性插值法,将样本padding为正方形。如图所示的“知”字,我们将原有68*72大小处理为了112*112的标准图片,并采用cvtColor(img, img, COLOR_GRAY2BGR)将其转为三通道,完成了整个预处理流程。
居中padding及归一化示意图(左为原始图像,右为预处理后标准图像)

文字检测
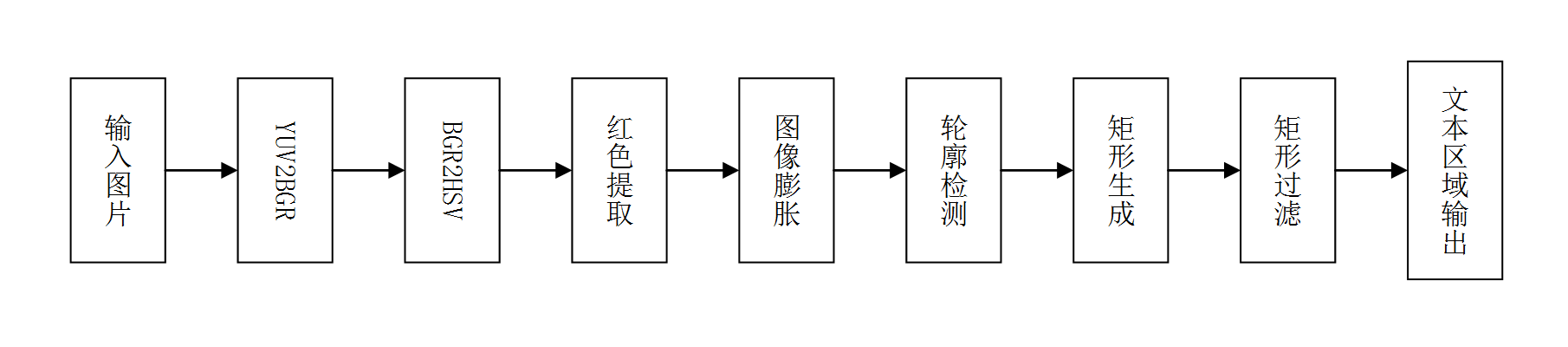
针对onCameraFrame里内容进行单字检测,整个过程见文字检测流程示意图,关键步骤的效果见单字检测关键过程的示意图。首先考虑到摄像头中真实场景的复杂背景信息,以及OpenCV有限的区域提取能力,我们固定手写汉字颜色为红色,以简化轮廓提取难度。因为红色在BGR颜色空间是不连续的,将图片转为HSV颜色空间进行颜色过滤操作。具体做法为:首先接收摄像头发送的格式为YUV420SP的图片,对该图片转为BGR格式,转换后如图所示。
文字检测流程
单字检测关键过程的示意图
 |  |  |  |  |
| (a) 原图 | (b) hsv图 | (c) 轮廓提取图 | (d) 轮廓膨胀图 | (e) 区域提取图 |
接着使用H(170,180),S(100,255), V(100,255),做为颜色阈值对图像进行颜色提取,结果如图(b)和图(c)所示。随后使用OpenCV的膨胀方法对提取的文本区域进行膨胀处理,以便于更明显的区分文本区域和背景,结果如图(d)所示。接下来在膨胀后的图像上提取轮廓,并针对该轮廓求最小水平矩形。考虑到存在可能的误差区域以及一个字分成多个区域,我们使用轮廓间的相对距离(即轮廓间距离/图像对角线距离)进行是否属于同一区域的判断,具体做法是设定距离阈值,计算两两轮廓间距离除以图像对角线距离得到相对距离,该距离小于距离阈值时,属于同一区域,该距离大于等于距离阈值时,属于不同区域,最后使用交并集算法进行区域合并。然后设定面积阈值,计算合并后的每个水平矩形的面积,并除以图像面积得到相对面积,当相对面积在距离阈值区间时,判定为文字区域,否则,舍弃,最后返回我们标定的文字区域坐标范围。最后的提取区域如图(c)所示。
文字识别
本节按照模型训练、模型转换、推断时的数据结构设计以及部署流程设计等四个方面展开。
模型训练
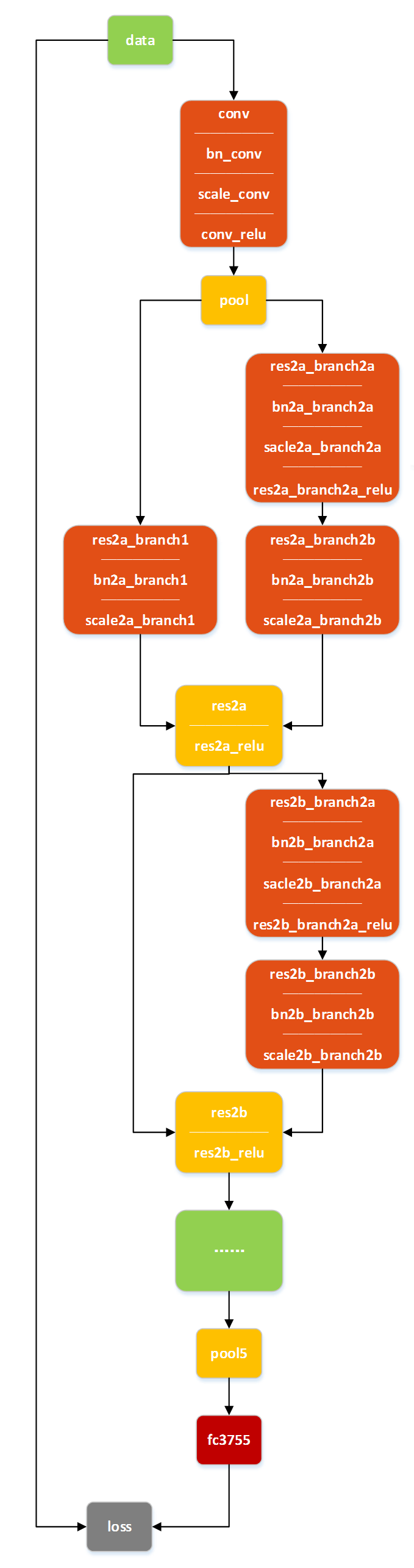
文字识别部分采用定制版ResNet来完成模型的学习与推断,它们的作用是用来对检测出来的文字进行分类。ResNet的网络结构在ResNet-50的基础上进行了简化,共有18层构成,如图所示。其中,resnet2b模块下方绿色省略部分为pool到resnet2b的重复构建,共有5个主体卷积池化结构。
ResNet-18网络结构图
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: false
mean_value: 0
mean_value: 0
mean_value: 0
}
data_param {
#训练集data.mdb路径
source: "L:/vs_projects/gnt2lmdb/gnt2lmdb/3755_train_RGB"
batch_size: 64
backend: LMDB
}
}
#测试集
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
mean_value: 0
mean_value: 0
mean_value: 0
}
data_param {
#测试集data.mdb路径
source: "L:/vs_projects/gnt2lmdb/gnt2lmdb/3755_test_RGB"
batch_size: 100
backend: LMDB
}
}
输出定义如下:
layer {
bottom: "pool5"
top: "fc3755"
name: "fc3755"
type: "InnerProduct"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 1
}
inner_product_param {
num_output: 3755
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "fc3755"
bottom: "label"
name: "loss"
type: "SoftmaxWithLoss"
top: "loss"
}
网络中间层配置及完整resnet18.prototxt脚本另见项目文件。
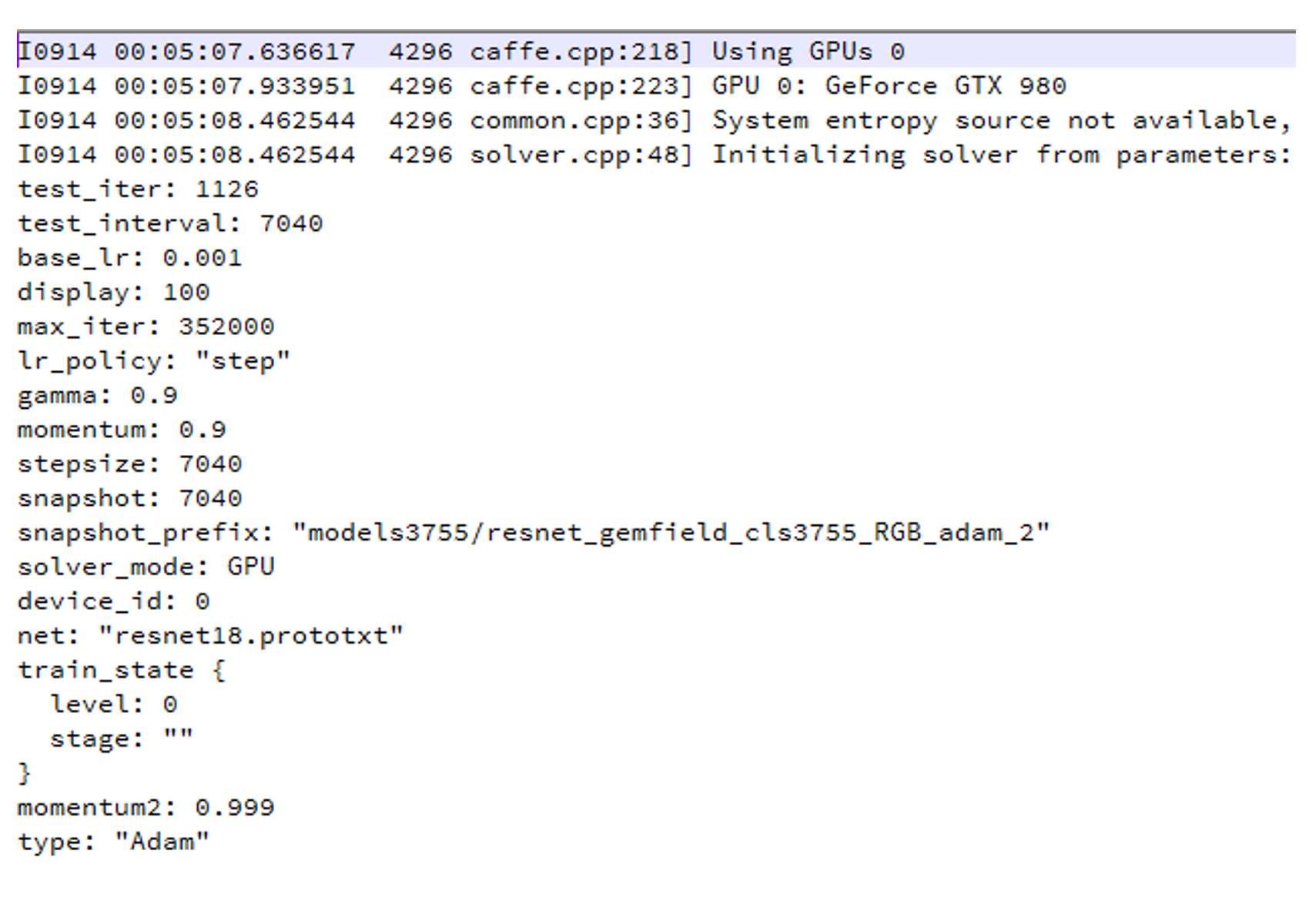
写好深度学习网络prototxt文件后,还需在solver.prototxt中定义训练的各种参数,如下所示:
#网络模型prototxt路径
net: "resnet18.prototxt"
#测试时迭代次数
test_iter: 1126
#每隔多少个step跑一次测试集
test_interval: 7040
#All parameters are from the cited paper above
base_lr: 0.001
momentum: 0.9
momentum2: 0.999
#since Adam dynamically changes the learning rate, we set the base learning
#rate to a fixed value
lr_policy: "step"
gamma: 0.9
stepsize: 7040
display: 100
#The maximum number of iterations
max_iter: 352000
snapshot: 7040
snapshot_prefix: "models3755rgb/resnet_gemfield_cls3755_RGB_adam"
type: "Adam"
solver_mode: GPU最后,定义如下resnet.bat文件,双击即可开始训练。caffe-master Buildx64Releasecaffe.exe train --solver=solver2.prototxtpause
训练过程如图所示:
训练过程展示
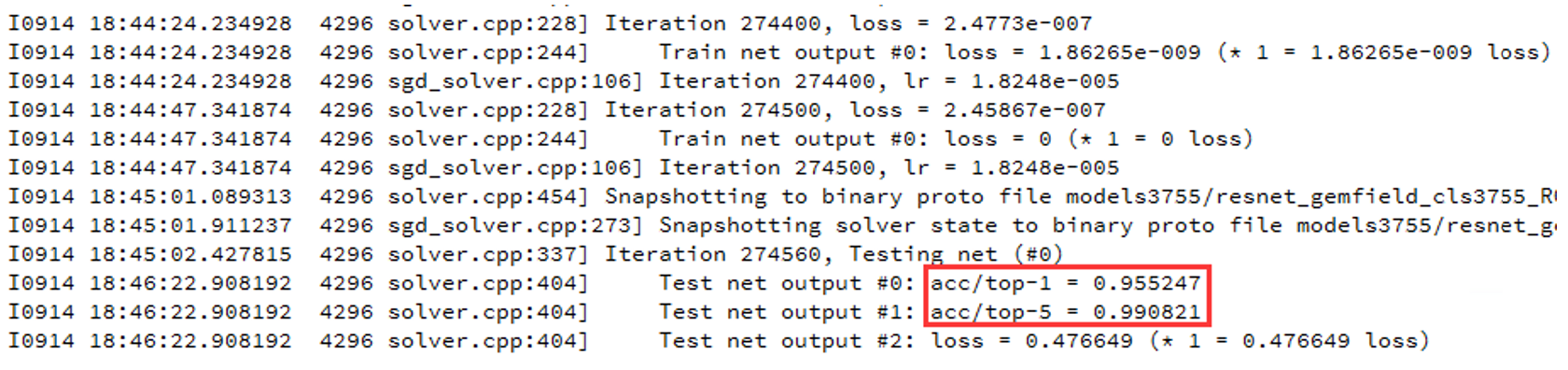
测试集验证情况如图所示:
测试集top-1&top-5展示
网络每隔7040个step会保存一次模型文件,最终训练出的部分文件如下图所示。
网络模型展示

模型转换
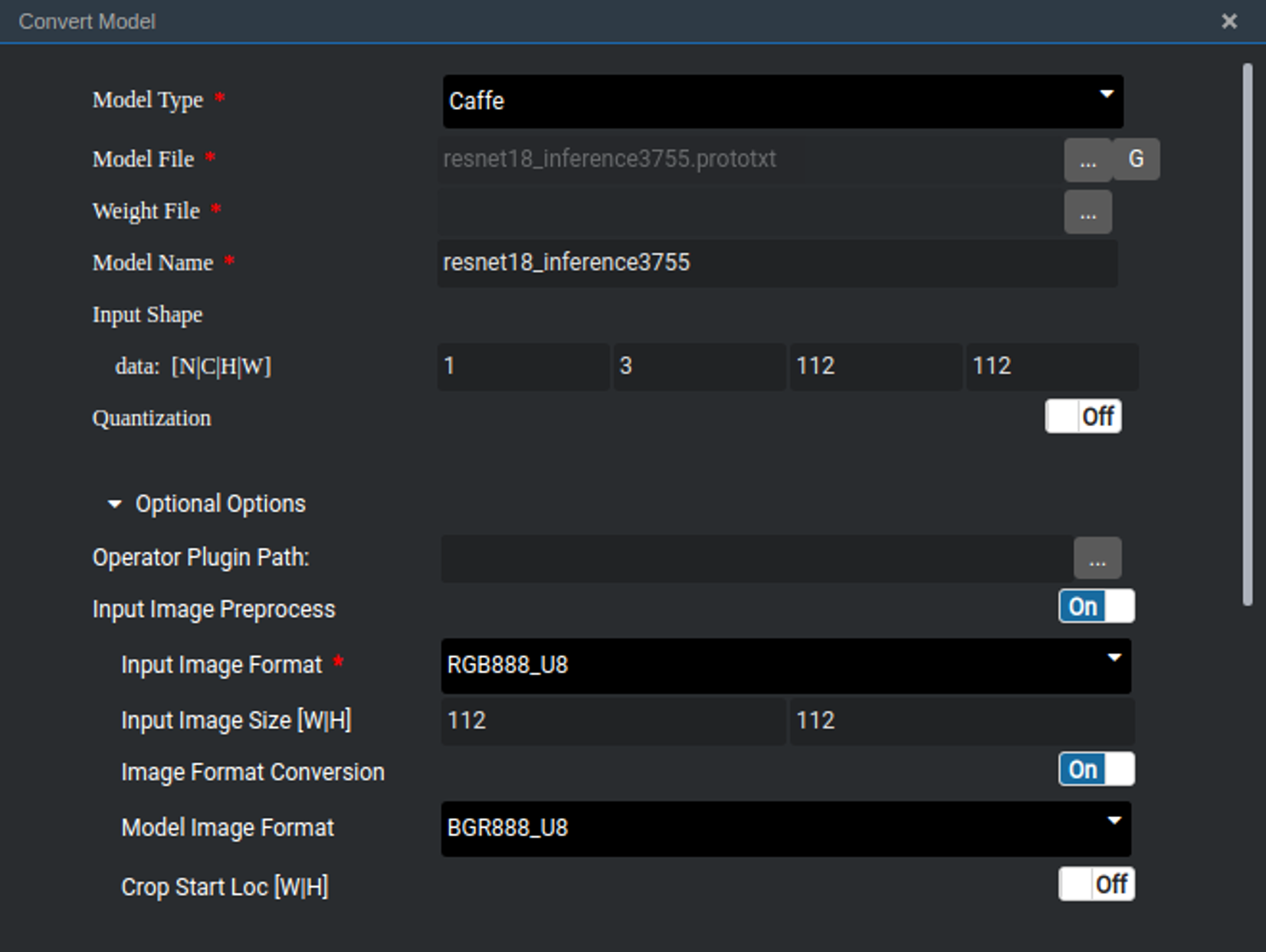
要将训练好的Caffe模型应用到Atlas200DK上,首先要将其转换为Ascend 310 AI处理器支持的离线模型,模型转换的参数如图所示。Model File为记录网络结构的prototxt文件,Weight File为记录参数值的caffemodel文件推理过程的batch size需要设为1,图像的宽、高和通道数不变,因此输入的维度N、C、H、W分别对应为1、3、112、112。为了使输入图像的格式符合模型输入要求,还需在模型转换中设置图像预处理的参数,其中输入图像的格式Input Image Format需调整为RGB888_U8, 输入的图像大小Input Image Size为112*112,其他选项一律设为off。模型转换过程尤为重要,参数需要按照caffe模型要求来调整,否则模型的输出会与期望不符,转换之后的模型为om文件,将其添加入工程中。
模型转换时的关键配置
推断时的数据结构设计
模型部署模块数据结构设计参考了目标检测的数据类型,汉字识别在其基础上添加了如下数据类型:
// 每个汉字的矩形框
struct CRect {
hiai::Point2D lt; // left top
hiai::Point2D rb; // right bottom
};
// 每张图片的检测与识别结果
struct ImageResults{
int num;// 每帧图像中的汉字数量
std::vector OutputT output_datas;//每帧图像中汉字输出向量集合
std::vector //每帧图像中汉字的矩形框集合
};
// 多帧图像检测与识别结果集合
struct CEngineTransT{
bool status;
std::string msg; // error message
hiai::BatchInfo b_info;
std::vector imgss;//每帧图像集合
std::vector results;//每帧识别结果集合
};部署流程设计
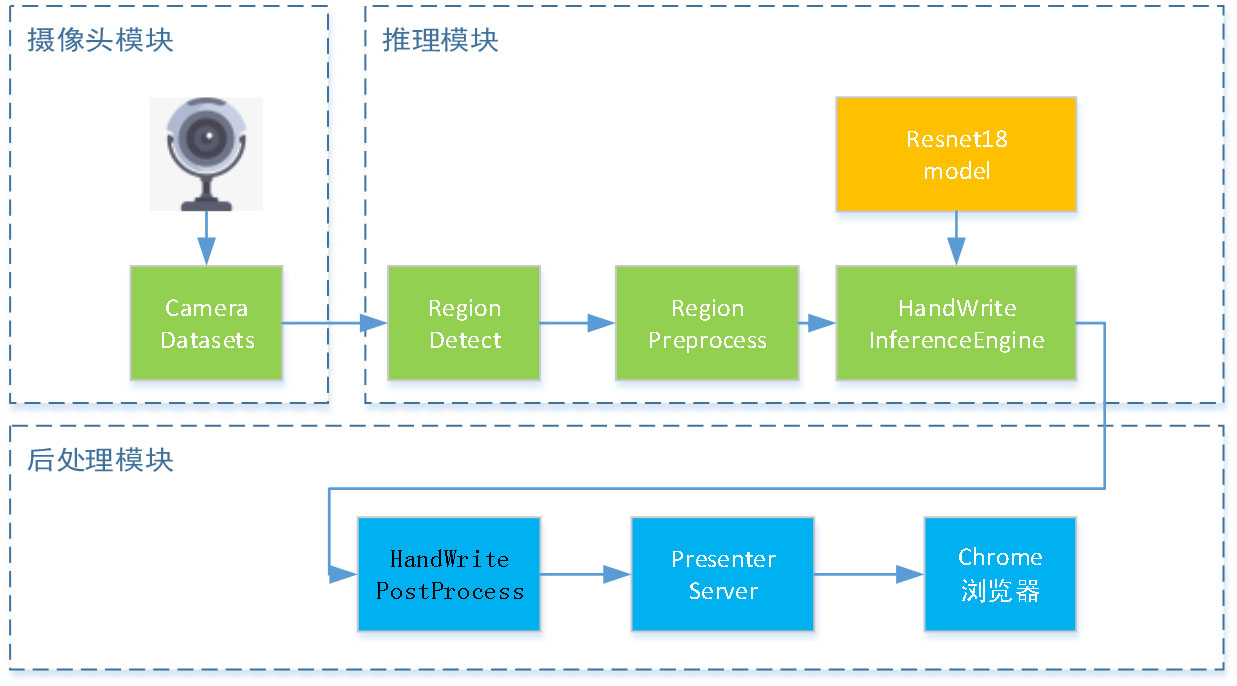
根据汉字检测与识别的需求,共设计了三个Engine,分别为摄像头模块、推理模块、后处理模块,部署流程图如图所示。摄像头模块与Camera驱动进行交互,设置摄像头的帧率、图像分辨率、图像格式等相关参数,从摄像头中获取YUV420SP格式的视频数据,每一帧传给推理引擎进行计算。以此工程为例,其中帧率fps为5,图像分辨率取1280x720,摄像头图像格式为默认的YUV420SP。推理模块接收摄像头数据,对YUV420SP格式的每帧图像进行以下两方面的处理:一方面将其转为RGB格式的图像,使用OpenCV对图像进行处理,检测出汉字的矩形框集合,接下来依次对每个汉字子图像通过模型进行推理,得到输出向量的结果集合;另一方面还需将每帧图像转换JPEG格式,以便于查看摄像头图像。将JPEG格式的每帧图像集合和每帧识别结果集合作为输入传给后处理引擎模块。后处理模块接收上一个引擎的推理结果与摄像头JPEG图像,将矩形框集合添加到Presenter Server记录检测目标位置信息的数据结构DetectionResult类中,作为摄像头图像的检测结果,通过调用Presenter Agent的API发送到UI Host上部署的Presenter Server服务进程。Presenter Server根据接收到的推理结果,求出汉字最大预测概率值所对应的索引,在索引表中查找对应汉字,在JPEG图像上进行汉字矩形框位置及汉字识别结果的标记,并将图像信息发送给Web UI。索引表为一个记录汉字与其对应索引值的表,为txt文件,在Ubuntu系统下以UTF-8的格式存储,其中每一行对应一个汉字。
部署流程图
结果
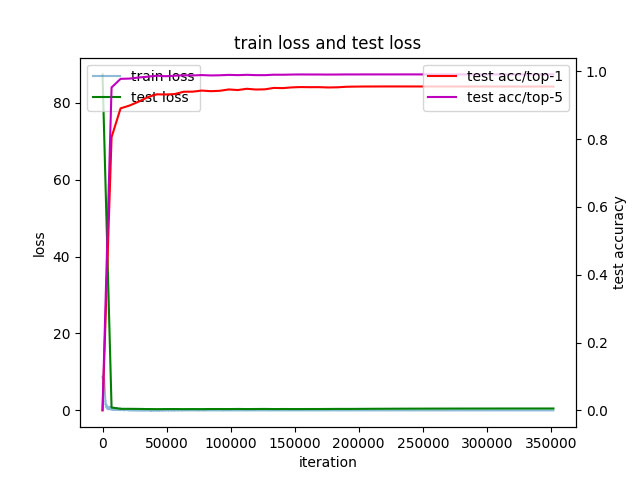
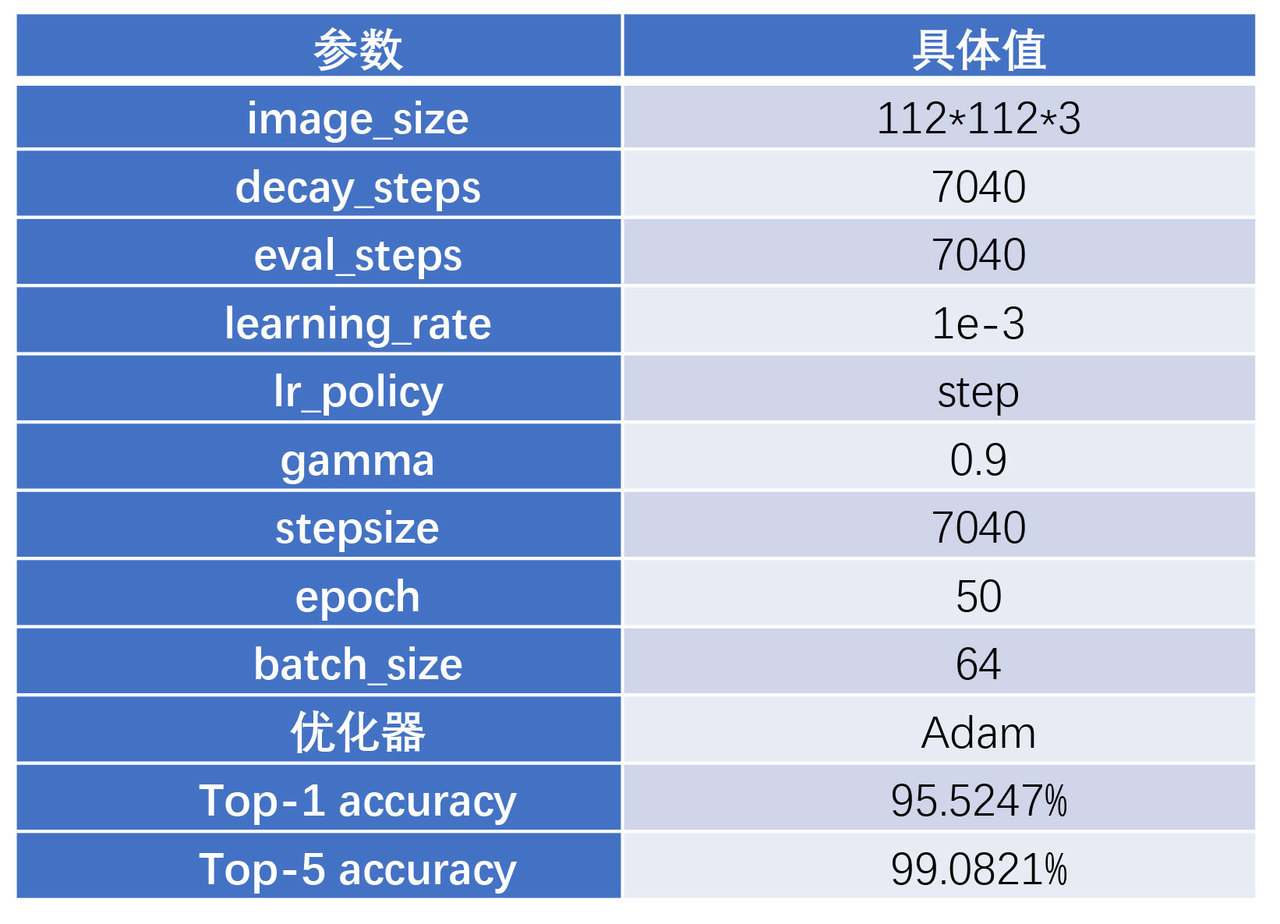
我们首先在HITHCD-2018数据子集上实验。图是ResNet在3755类手写汉字数据下的训练过程和验证过程。表为 ResNet网络训练3755类手写汉字的关键网络参数表和测试结果。
ResNet在3755类手写汉字训练集下的accuracy和loss
ResNet网络在3755类手写汉字识别任务中的网络参数和测试结果
然后针对拍照识别的两种实际场景,进行了测试。第一种场景的硬件布局图见图所示,第二种场景的布局如图。第一种场景多见于感知外界已有(已经张贴好的)手写文字,第二种场景可以用于实时书写实时识别的场合。
场景1:摄像头的平视布局

场景2:摄像头的俯视布局

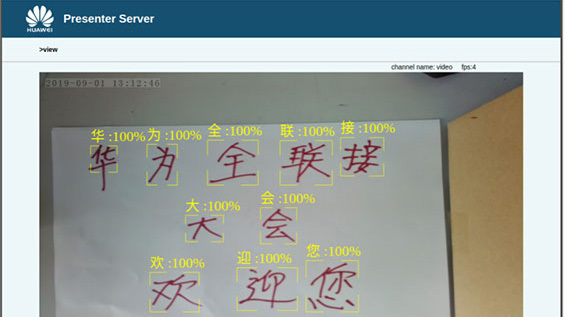
我们测试了两种场景,给出典型的效果图。对于场景1的识别效果如图所示,对于场景2样例如图所示。最后,我们测算了系统的主要时间消耗情况。一帧图片的整图字符检测约60毫秒,识别阶段每个字的平均识别时间约为3毫秒。在光线稳定的情况下,单字识别准确率90%以上,符合项目要求。



后续可扩展性
本项目聚焦于少量手写汉字的识别任务。后续可以扩展到包含复杂背景的大量手写汉字识别场景,比如手写作文文字的检测与识别等任务。