
项目意义
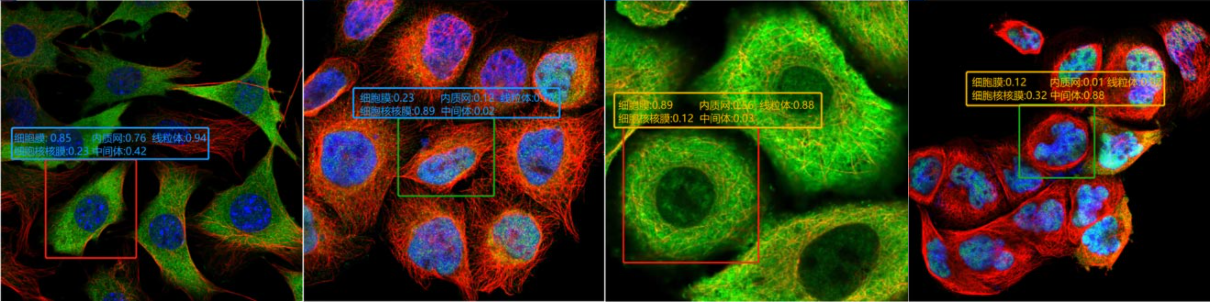
免疫荧光显微图

该项目所使用的图像数据来自人类蛋白质图谱数据库(human protein atlas),其目的是利用各种组学技术(包括抗体成像、质谱分析、蛋白质组学等)绘制所有人类蛋白质在细胞和组织中的表达和空间分布图。该数据库可免费使用,有助于加速生命科学研究和药物发现。
对细胞中的蛋白质进行可视化成像是生物医学研究的常用手段,这些蛋白质可能是下一个医学突破的关键。然而,由于高通量显微镜技术的进步,这些图像的生成速度远远超过了手动评估的速度。
因此,开发自动化生物医学图像分析工具,用以加速对人类细胞和疾病的理解,具有迫切而广泛的需求。
使用深度学习工具,对人类蛋白质荧光显微图片中蛋白所处的细胞器进行精准的识别,将训练好的模型移植到Atlas 200开发板上,使用Atlas 200开发板对未标注的蛋白质荧光显微图片进行亚细胞位置的预测,拓展AscendAI处理器在生物领域的应用。
问题描述
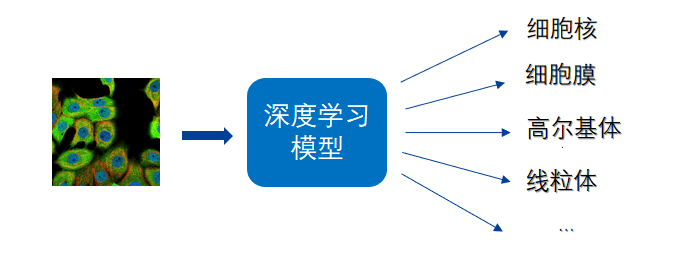
首先需要使用有标注的数据训练一个深度神经网络模型。然后给定未标注的蛋白质荧光显微图像,使用训练好的模型对图像中的亚细胞定位模式进行识别,给出细胞器位置标签。从本质上来说,这属于一个多标签的分类问题。
项目挑战
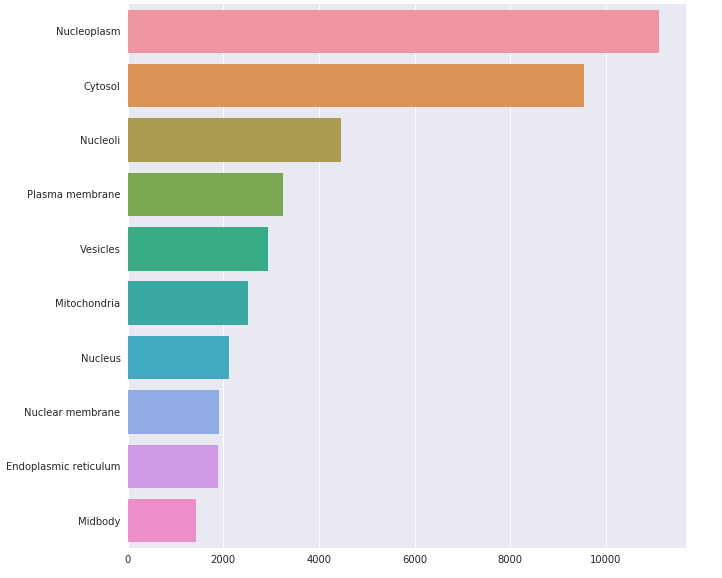
- 不同类别的样本数量相差悬殊,有些类别的样本数量很多,有些类别的样本数量偏少,样本分布极不均衡。
- 标签数据繁多,共计29种不同的亚细胞位置标签,高质量的标注数据数量较少。
- 图像尺寸不统一,存在多种不同尺寸(如800*800, 1728*1728,2048*2048.),且图像尺寸偏大。
数据增广
扩增小类图像样本数量
- 随机水平垂直翻转。
- 随机镜像翻转。
- 随机旋转。
- 随机剪切。
上采样
使用批处理的方式训练模型,在构造批量的数据时,对稀有类别的数据进行上采样,增加稀有类别数据被选中的概率,使得模型在训练的过程中能够多学习稀有类别数据的特征,缓解数据不平衡带来的模型训练失衡问题。
阈值搜索
在模型训练完毕之后,相对于传统的使用0.5作为正负样本之间的阈值,对每一个类别的分类阈值实施网格搜索,为每一个类别找到相应最优的阈值。
挑选输入图像块
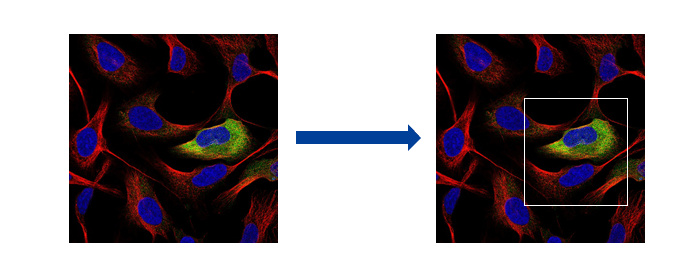
考虑到图片尺寸可能太大难以学习的问题,我们从原图中抽出能代表整幅图中亚细胞定位模式的关键区域,再提取特征。具体方案采用候选框提取(selective search)、边缘框(edge box)等无监督方法,选择图像块(patch)作为输入,再利用卷积层提取特征。
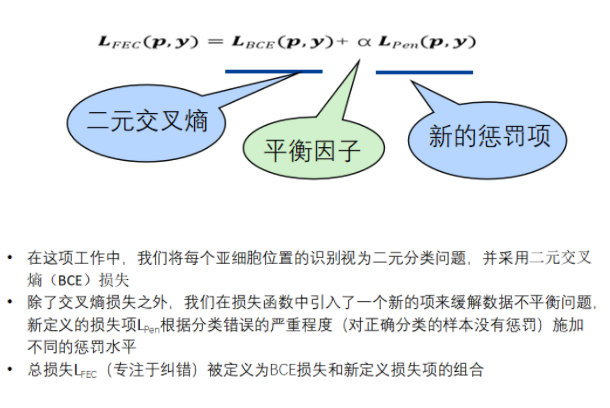
损失函数
主干网络
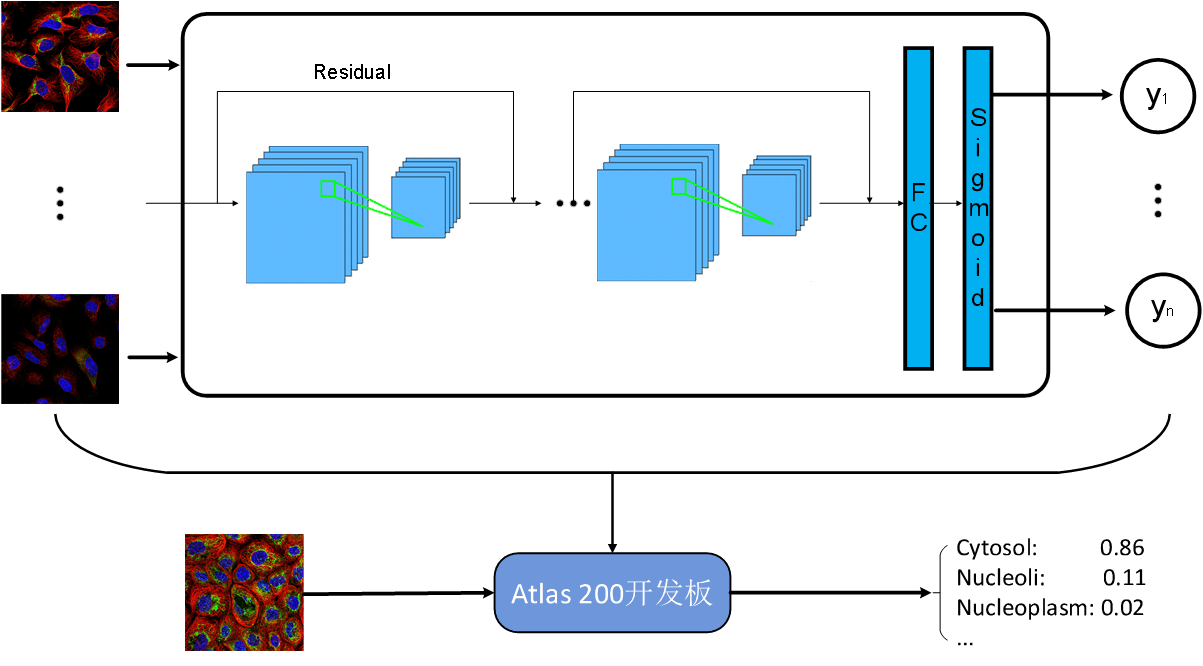
使用在ImageNet上预训练过的ResNet网络模型。
在已有模型的基础上添加一个全连接层和sigmoid层。
使用数据集训练模型,然后将训练好的模型导入到Atlas平台上,之后使用Atlas平台对输入图片进行预测,输出预测结果。