
概述
意见挖掘(opinion mining),亦称情感分析(sentiment analysis),其主要目的是从非结构化的评论文本中抽取结构化的意见信息,主要包括意见持有者(opinion holder)、评价对象(target)与评价方面(aspect)、评价(evaluation)及其正面、负面或中性的情感极性(polarity)等。作为一个新兴的研究领域,意见挖掘研究近年来引起自然语言处理研究界广泛的关注,并在舆情分析、产品推荐、品牌分析、智能客服等得到广泛的应用。
本项目以酒店服务领域为例,探索如何应用深度学习方法在华为Atlas 200 AI加速模块上实现一个完整的面向酒店服务的意见挖掘系统,从而构建基于华为Atlas 200 AI加速模块的自然语言处理应用生态。
总体设计
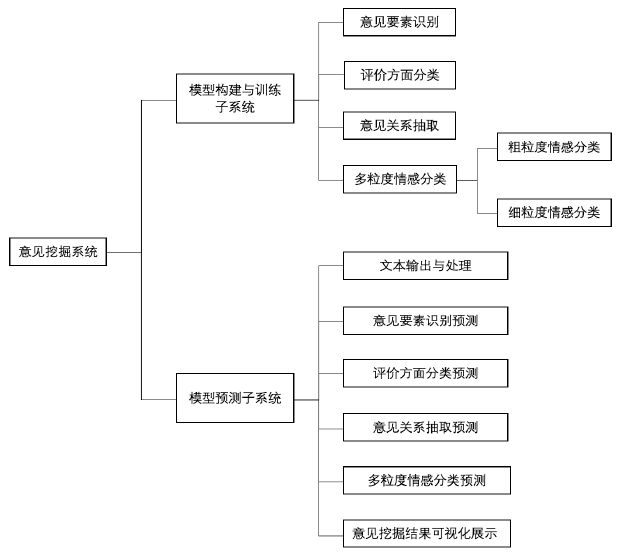
图1 系统总体设计图
如图 1 所示,本项目涵盖意见要素识别、意见关系抽取、评价方面分类(aspect categorization)以及对象(target)、方面(aspect)和评论(review)多粒度情感极性分类等多个意见挖掘子任务,并提供相应的训练、预测以及意见挖掘结果可视化展示等功能,可以提高一站式的意见挖掘信息服务。
算法设计
整个算法包括模型训练和模型预测两个阶段,相应的流程分别如图2和图3所示。
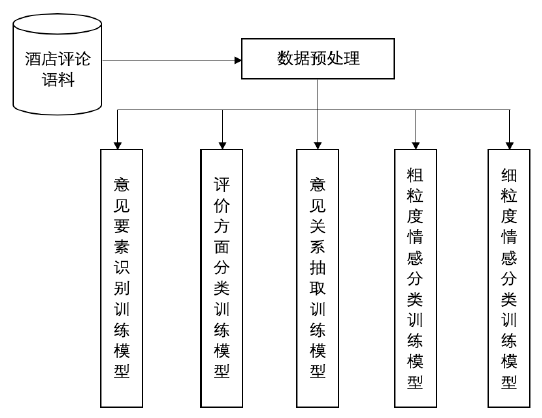
图2 训练流程粗略图
如图 2 所示,模型训练的主要流程为:训练数据集->深度学习方法->模型。根据各子任务的特点,我们分别采用 LSTM、BERT 等深度学习方法从训练数据集构建相应的模型。
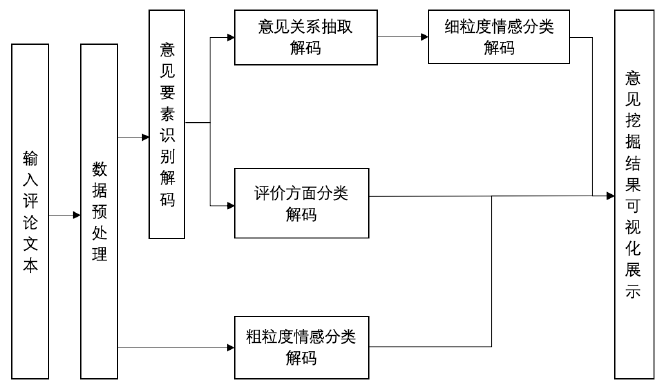
图3 解码预测流程图
图3所示,本项目的解码预测采用管道策略,具体流程为:评论文本->意见要素识别->Apect分类解码->意见关系抽取解码->细粒度(target和Apect)情感分类->粗粒度(review)情感分类->意见挖掘结果可视化与展示。
技术
本项目的模型解码部分是基于华为 Ascend 310 AI处理器实现的,而训练模型则是在TensorFlow 1.12 神经网络框架下构建的。具体模型包括:
- 基于 BERT 的意见要素识别模型。
- 基于 LSTM 的 Aspect 分类模型。
- 基于 LSTM 的意见关系抽取模型。
- 基于 Vanilla-Attention LSTM 的细粒度(target)情感分类模型。
- 基于 LSTM 的粗粒度(review)情感分类模型。
硬件
使用了华为自主研发的 Atlas 200 DK 开发者套件(型号:3000),该项目的模型解码预测部分是在该开发板上完成的。
优化点
可以优化的地方大概有以下三个方面:
- 在上述子任务中,意见关系抽取模型性能相对较低。将来可考虑探索新的模型框架,以提升意见关系性能。
- 目前的系统没有使用结构化的信息,将来可以考虑融合句法和语义结构等信息以进一步提高意见挖掘性能。
- 目前的系统采用管道策略,意见挖掘被拆分为多个子任务,多个模型上分别解码影响系统的预测速度。将来可考虑任务或模型融合,以提高预测速度。
效果展示
系统预测分析的大致操作流程:通过文件菜单选取分处理的意见文本文件,然后点击 Run 菜单就能分析出该文本的意见信息。分析结果的总体效果如图 4 所示。

图4 系统界面与分析结果展示
如图4所示,系统结果展示界面主要由两部分组成:上半部分为输入文本和中间结果展示(主要包括意见要素抽取、意见关系识别和细粒度极性分类),可分别点击相应的按键显示相应的结果,具体如图 5~图 7所示。界面的下半部分为意见挖掘结果的聚集融合和可视化展示,具体如图 8~图 11 所示。

图5 输入意见文本展示。
图6 为意见要素抽取结果展示,以句子为单位,每行表示从一个句子中抽取的意见要素,包括对象、评价等。

图6 要素抽取展示
图7为意见关系抽取结果,每行表示一条意见信息,格式为(<实体>,e,<评价>)。

图7 意见关系抽取展示
图8 为关于酒店服务的整体情感极性。其中,红色表示积极,蓝色表示消极。

图8 整体情感极性比例
图9和图10分别为一级、二级 Aspect的情感极性分类结果展示。其中,红色表示积极,蓝色表示消极。
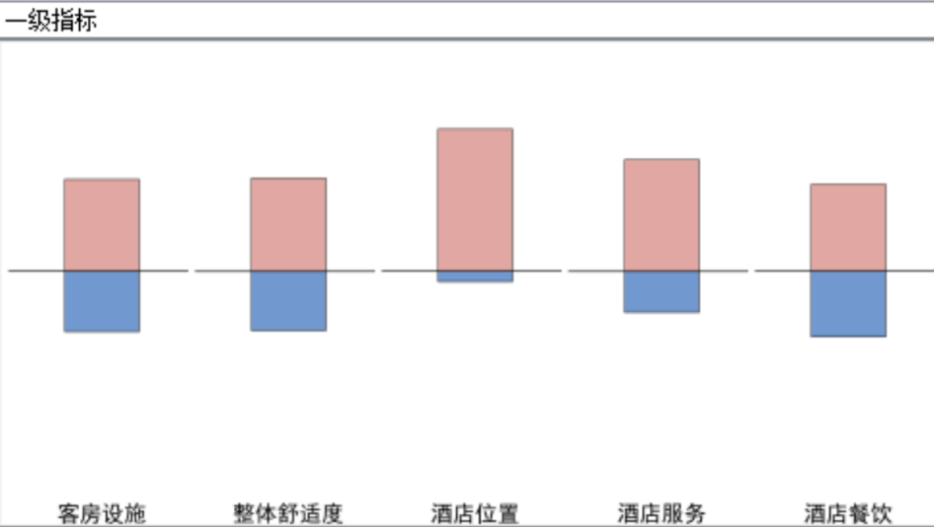
图9 一级 Aspect情感极性
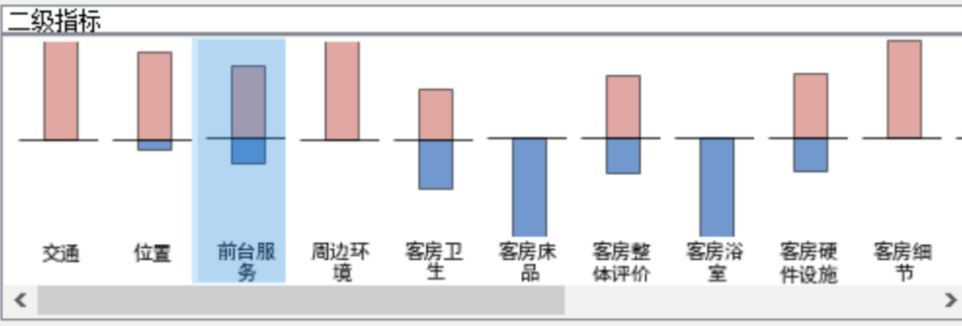
图10 二级指标情感极性表示
图11为点击二级Aspect的某一种类别而展示出来的相应的target具体意见信息。

图11 选定的二级Aspect对应的target意见信息