Ascend C 2.0新特性详解,支撑大模型融合算子高效开发
发表于 2024/06/13
01 前言
近日,昇腾算子编程语言Ascend C发布2.0版本,新增支持通算融合MC²特性,使能大模型场景下通信和计算并行,提高整网运行性能;提供更丰富的API覆盖当前主流的融合算子开发场景,提升开发效率;同时通过算子上板调试等调试能力的增强,可将典型算子功能调试耗时降低至小时级。
Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。全新升级的Ascend C 2.0版本将进一步贴近用户大模型场景的开发诉求,带来更易用的开发体验和更强大的算子执行性能。
02 提供更丰富的API,算子编程效率提升
目前,Ascend C 2.0已提供130+基础API和60+高阶API,极大地丰富了Ascend C的编程易用性。Ascend C基础API作为算子开发体系的基石,为昇腾AI处理器的矩阵计算、矢量计算、内存管理等能力提供了开放接口,让开发者可以更灵活的对计算过程进行处理;同时,面对更复杂、多变的计算场景,Ascend C提供Matmul、SoftMax等高阶API,将常用算法逻辑进行封装,可减少重复开发,极大提高开发者的开发效率。
Ascend C开放API举例如下。

使用Matmul高阶API,开发者可以四步完成一个矩阵乘计算操作,免去了复杂的tiling算法设计和数据切分搬运,可以高效的完成矩阵乘计算,同时大幅降低了融合算子的开发难度,支撑大模型融合算子高效开发。
// 1、创建Matmul对象
typedef MatmulType<Tposition::GM, CubeFormat::ND, half> aType;
typedef MatmulType<TPosition::GM, CubeFormat::ND, half> bType;
typedef MatmulType<TPosition::GM, CubeFormat::ND, float> cType;
typedef MatmulType<TPosition::GM,CubeFormat::ND, float> biasType;
Matmul<aType,bType,cType,biasType>
mm.Init(&tiling, &tpipe); // 初始化
// 2、设置左矩阵A、右矩阵B、Bias
mm.SetTensorA(gm_a); // 设置左矩阵A
mm.SetTensorB(gm_b); // 设置右矩阵B
mm.SetBias(gm_bias); // 设置Bias
// 3、完成矩阵乘操作
while (mm.Iterate()){
mm.GetTensorC(ub_c);
……
}
//mm.IterateAll(gm_c);
// 4、结束矩阵乘操作
mm.End():03 支持通信计算融合,提升整网运行性能
通算融合MC²(Merged Compute and Communication)主要是将通信和计算的操作过程融合,在通信的同时并行执行计算操作,从而将计算总时间从“T通信+T计算”压缩到“max(T通信,T计算)+拖尾开销(max(t1,t2)/通信轮次)”。以allgather+matmul+add场景举例,支持通算融合MC²特性后,GPT-3的整网性能可提升10%。
通信计算串行方案:计算总时间 = T通信+T计算
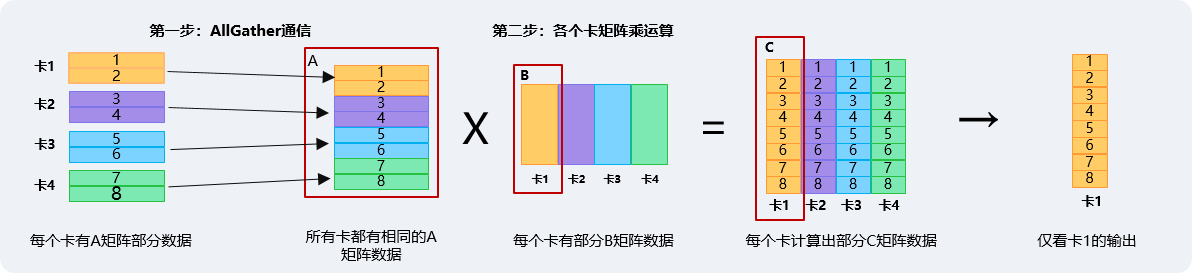
MC²通算融合方案:计算总时间 =max(T通信,T计算)+拖尾开销(max(t1,t2)/通信轮次)
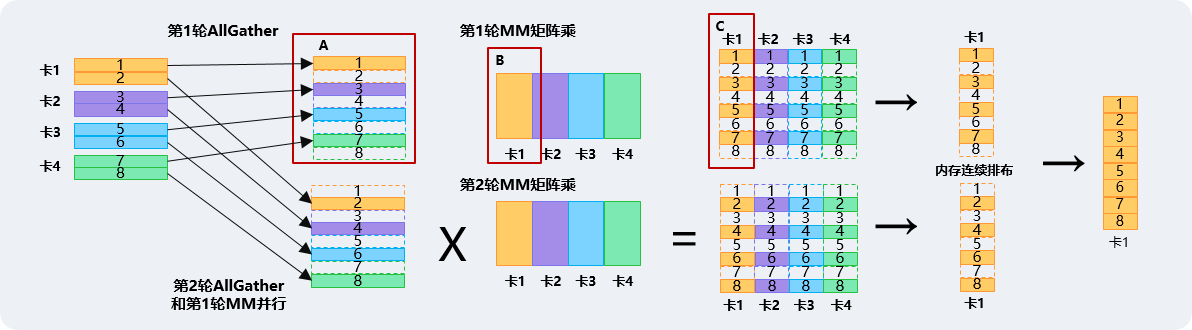
Ascend C支持在算子的Kernel代码中进行通信相关操作,将集合通信和计算进行深度融合,从最底层的算子侧提供通信和计算融合。

以下是通算融合MC²算子的kernel编程伪码:
__global__ __aicore__ void Kernel(GMADDR gmA, gmB, gmC, Tiling* tiling) {
Matmul<…> mm; //完成Matmul 的定义
…
HCCLComm<HCCLDmaMode::SDMA> comm;
comm.Init(tiling->ptrHCCLTiling); //在Host Tiling时填充,初始化通信对象
gmWin = comm.GetCommAddr(); //获得通信域地址,减少Copy
//先通知通信引擎准备数据,并把数据放到win窗口
comm.Prepare<AllGather>(gmWin, gmA, size, DATA_TYPE_FP16);
comm.Commit(); //发起一次通信,让通信先发起,然后本地计算
//计算本地的一片数据做矩阵计算 A*B=C ,此时通信和计算异步并行
mm.SetTensorA(gmA);
mm.SetTensorB(gmB);
mm.IterateAll(gmC + offset);
//gather后数据计算
for(int i=0; i < tiling.tileCnt; i++) { //对A矩阵Gather数据切分成tileCnt份,
if( i != tileCnt-1) { //通知通信引擎,进行下一次通信
comm.Prepare<AllGather>(gmWin+offsetWin, gmA+offsetA, size, DATA_TYPE_FP16);
comm.Commit();
}
comm.Wait(); //等待Gather数据完成
SyncAll(); //多核同步,其他核和发起通信的核同步
mm.SetTensorA(gmWin+offsetWin); //计算接收过来的数据的MM
mm.IterateAll(gmC+offsetC); //计算接收过来的数据的MM
}
}04 调试能力增强,提高问题定位效率
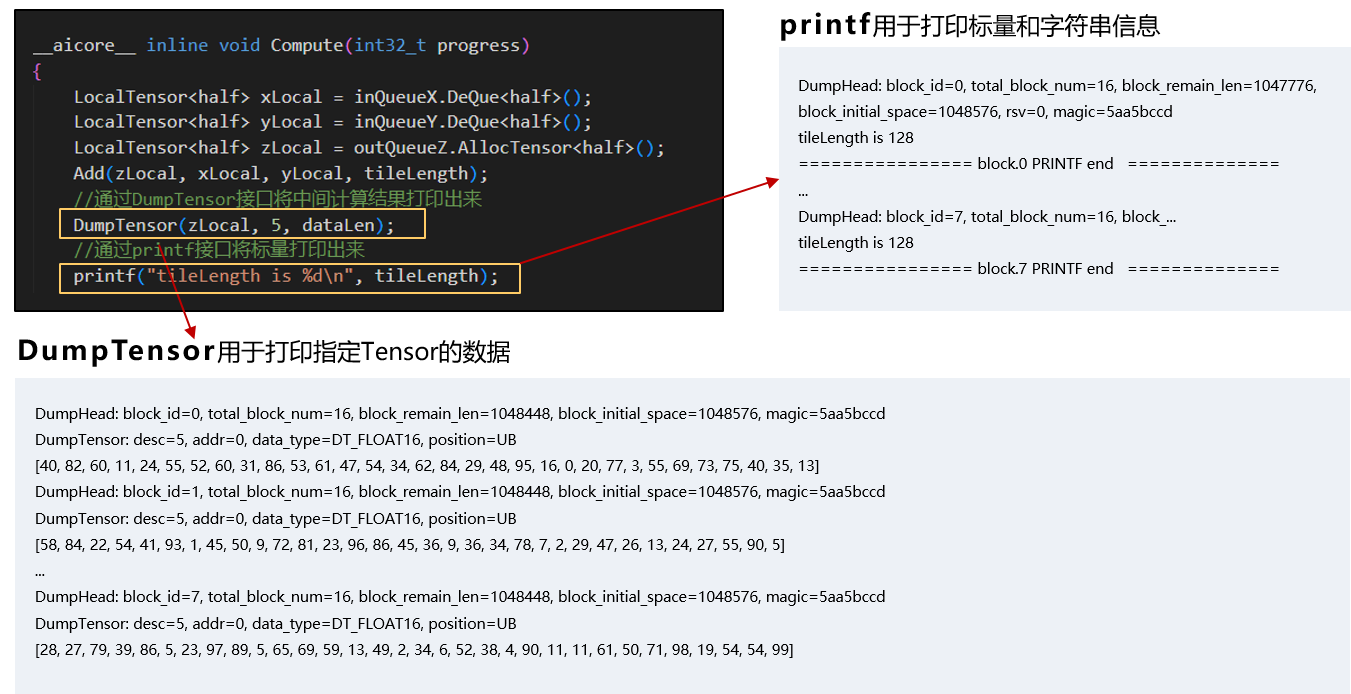
Ascend C提供了丰富的调试调优手段,帮助开发者提高问题定位效率。Ascend C 2.0在支持CPU域和NPU域孪生调试的基础上,丰富了NPU域的多种调试方法,可针对性发现和解决各类算子问题。NPU上板调试可针对单算子核函数进行上板运行调试,快速定位算子精度问题;Tiling调试可以进行Tiling函数验证及结果解析,帮助定位Tiling问题;上板Profiling数据采集可在真实环境统计算子执行耗时,帮助快速进行算子性能调优;同时支持指令级流水性能图,方便开发者查看算子内部流水并行处理情况,从而辅助开发者进行性能调试。
其中,NPU域上板调试功能可支持DumpTensor、printf两种数据打印能力,DumpTensor用于打印指定Tensor的数据, printf主要用于打印标量和字符串信息,辅助开发者了解算子中间计算结果,提升调试效率。
Ascend C作为昇腾专门面向算子开发场景的编程语言,已经在大模型场景下发挥了巨大的作用,目前,基于Ascend C开发的FlashAttention算子相比融合前的小算子取得了5倍以上的性能提升,开发者可直接调用相关算子API接口使能大模型极致性能优化。相信随着Ascend C 2.0的全新升级,基于Ascend C开发融合算子的优势将愈加凸显,助力开发者突破技术壁垒,为大模型创新提供新方向。
目前,基于Ascend C的开发者大赛和活动正在火热进行中。面向企业的“CANN技术行”、面向高校和普通开发者的“CANN训练营”正在源源不断地为昇腾注入开发源动力,鼓励开发者基于Ascend C的基础能力进行原生开发与实践创新,同时“昇腾AI原生创新算子挑战赛(S2赛季)”也将于近日火热开启。了解Ascend C 2.0更多信息,欢迎登录昇腾社区使用体验:https://www.hiascend.com/ascend-c