深度解读昇腾CANN内存复用技术,降低网络内存占用
发表于 2024/07/05
1 前言
随着大模型的兴起,神经网络规模不断扩大,对内存资源的消耗也越来越高,如何降低AI算法的内存占用成为AI计算领域降成本提性能的一个重要手段。当前降低AI算法内存占用的主要技术有内存复用(Memory Reuse)、重算(Recompute)、内存交换(Memory Swap)、控制执行序(Topo优化)等,其中内存复用是应用最广泛的内存优化技术,该技术可在不影响网络执行性能的前提下降低内存占用,结合Topo优化可以进一步降低内存占用,且对执行性能影响也较小。
静态shape的神经网络在基于计算图模式执行时,由于具备计算图的全局视角,可以较完整地记录和管理全局内存及生命周期信息,GE(Graph Engine)图引擎基于业界常规的内存优化技术,借助全图视角对内存复用算法进行了更好的寻优处理,同时进行了Topo排序优化降低网络内存理论最小值,从而更有效地降低网络内存占用。
2 内存复用技术
2.1 常规内存复用技术
如下图所示有一个简单的网络,经过Topo排序后每个节点都有一个唯一的ID,每个节点的输出内存都可以用这个ID来表达生命周期。
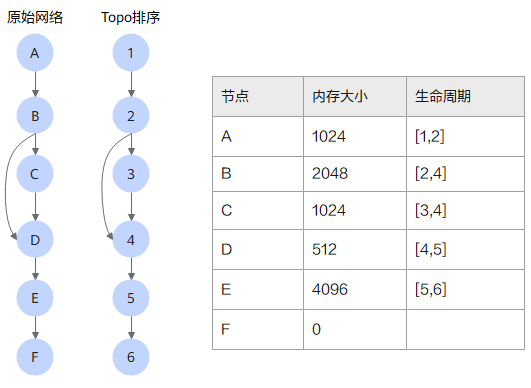
其中“生命周期”是指内存从分配到释放的时间段,用拓扑排序序号来表示,在复用处理过程中,生命周期没有重叠的才能复用。
“内存复用”是指按照生命周期和内存大小,把不冲突的内存重复使用,来降低网络内存占用。内存复用算法主要有Binary block复用和Max block复用两种,两种复用算法原理类似,唯一差别是block的大小规划有差异。这里的“block”是指内存复用时的虚拟内存块,并不是真正的内存。
内存占用的“理论最小值”计算方式为:按照内存使用顺序,在每个节点生命周期开始加上内存大小,生命周期结束减去内存大小,不考虑内存碎片和空洞等浪费问题,理论计算得到的内存占用最小值。如下图所示,内存占用的理论最小值为4608,但是如果不做内存复用,总内存大小为8704。
内存复用处理的主要步骤:
1、 获取内存复用block的Range值
Max block算法取所有内存大小的最大值作为Range,此例为[4096],Binary block算法会按规则生成多个Range,此例为[1024,2048,4096]。
2、Reuse处理
按照拓扑排序进行内存分配和复用,Max block复用算法block大小都一样,只要生命周期满足要求就可以复用,Binary block复用算法block大小不同,要生命周期和block大小同时满足要求才可以复用。
3、Resize处理
复用处理时block大小一般都比实际分配的内存大,resize的作用就是根据复用结果把block大小改成合适的大小并做512字节对齐。
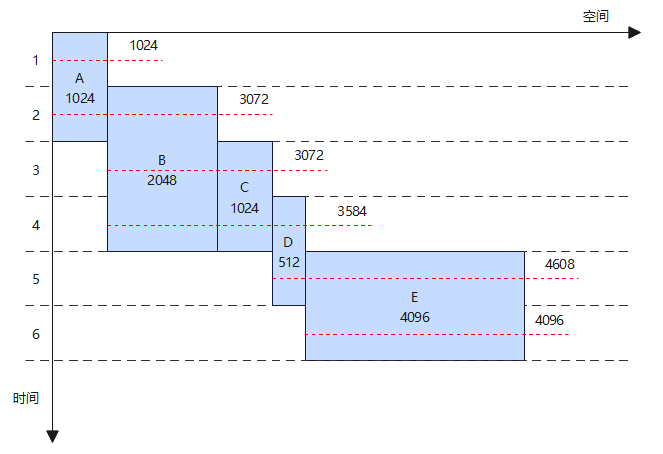
下面以Max block算法为例介绍原始内存复用技术的实现原理,Range为[4096],因此所有block大小都为4096。
Reuse处理:按照网络节点顺序进行内存复用。内存分配时的block大小都是4096,标号为A、C、E的内存可以复用,而标号是B、D的内存由于生命周期存在交叉,无法复用。所以复用后得到3个block。
Resize处理:按照block中实际节点内存大小进行压缩。复用完成后每个block取所有节点的内存最大值作为该block最终内存大小,如block1最大的是E,最终大小为4096,block2只有一个B最终大小为2048,block3为512,最后所有block的大小累加就是复用后的总内存大小。如下图所示,复用后总内存大小为6656。
2.2 GE内存复用优化技术
Max block算法进行内存复用时,要求所有block大小都是block range,即网络节点的内存最大值4096,所以即使实际仅需要较小的内存也要按照最大值进行内存分配,存在一定的内存浪费。Binary block算法虽然对block大小进行了细化,但是要在一定大小范围内的节点才会复用,内存较大和内存较小都无法复用,也会影响内存复用的效果,存在内存浪费的弊端。
因此,GE采用了一种更极致的内存空间复用优化技术。一级复用时只把相同大小的内存复用在一起得到一组block,二级复用时把block按照从大到小排序,顺序取后面一个block,如果生命周期不重叠和当前block进行合并,否则不做处理,以此类推进行多级递归判断,最后把未被合并的block大小进行累加就是最终内存大小,由于大block合并多个小block,因此可以进一步减少内存占用。
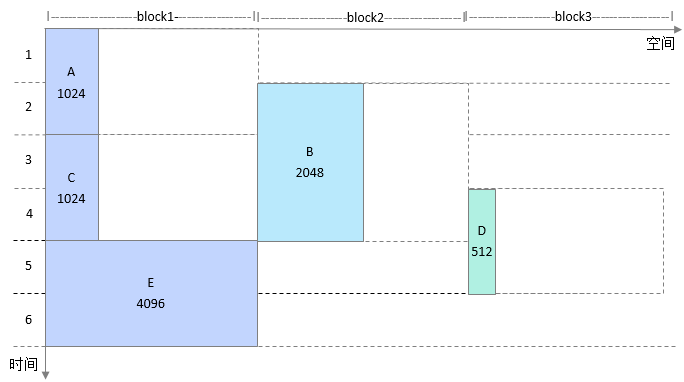
一级复用处理:按照实际大小进行复用,不同大小的block不复用在一起,因此AC可以复用,AE大小不同无法复用,复用后示例如下图所示。
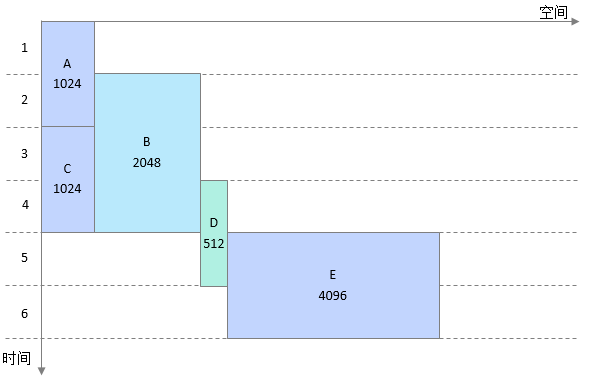
一级复用处理后得到4个block(比原有节点数减少了一个,此例比较简单,实际网络中block的数量可以比节点数减少一个数量级),然后根据网络节点生命周期获取block的生命周期。block生命周期示例如下。
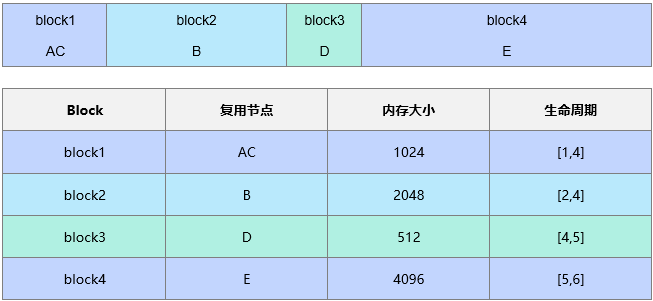
然后把block按照从大到小进行排序,排序后结果如下图所示。
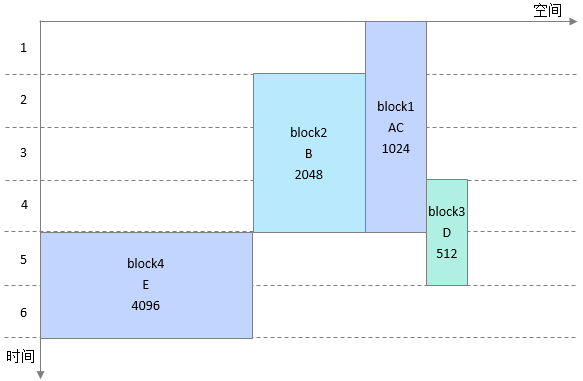
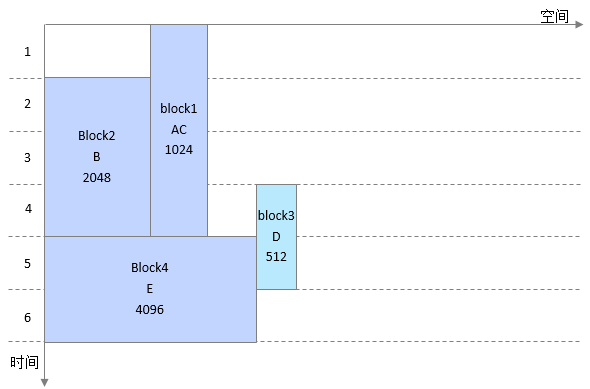
二级复用处理:把排序后的大block和小block依次进行合并处理,一个大block可以合并多个小block。
1、 block4生命周期为[5,6],block2的生命周期为[2,4],生命周期不重叠,可以和block2进行合并,起始地址对齐。
2、 block1生命周期为[1,4],和block4生命周期不重叠,但是和block2重叠,因此摆放在block2的右侧,起始地址为block2的结束地址。
3、 block3生命周期为[4,5],和block4重叠,不能和block4合并,因此只能摆放在block4的右侧。
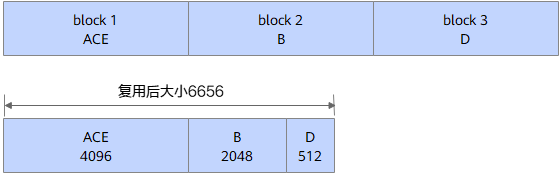
4、 最终得到复用后的内存大小为4608(4096+512),和理论最小值一致,没有任何浪费。
block合并如下所示。
2.3 GE内存复用优化效果
GE的内存复用优化主要有以下优点:
•提高内存复用率,减少内存占用
解决不同大小内存之间的组合复用问题,可以把一块大内存切分成多块小内存进行二次复用,进一步提高内存复用率,减少内存占用。
•降低复用算法耗时
先按节点内存实际大小和生命周期进行一级复用,减少二级复用时的block个数(可以减少一个数量级),有效减少二级复用算法耗时。
从16个实际网络模型的测试结果看,采用GE内存复用优化技术可以更好地降低网络内存,单Stream大部分场景可逼近理论最小值,而处理耗时也较短,如下图所示。
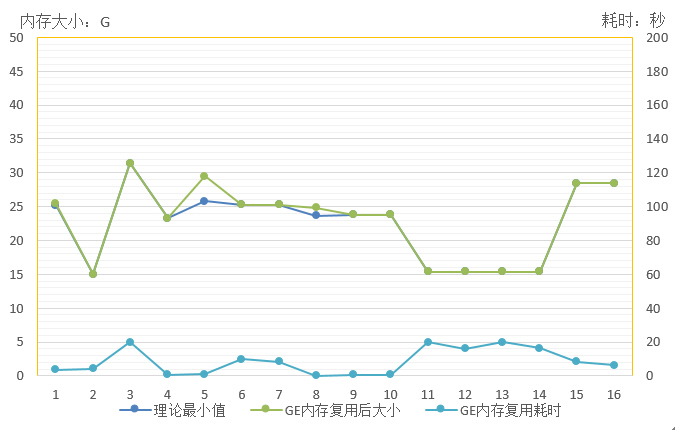
较好的内存复用效果主要得益于GE计算图模式有全局的内存大小和生命周期信息,能够让复用算法进行更好的寻优处理;而单算子模式下,由于算法无法预测内存大小,生命周期也没有全局信息,会导致内存空洞和碎片问题,无法将内存复用做到极致,大部分场景内存占用只能做到理论最小值的1.2倍以内。相同网络图模式内存占用会比单算子模式更少,例如,相同的网络下,若单算子模式需要15.14G,图模式只需要13.8G,内存占用可降低9%左右。
3 Topo优化技术
3.1 常规Topo技术
内存复用优化技术主要解决如何逼近理论最小值的问题(一个网络在确定的Topo排序下都有一个理论最小值),而改变Topo排序可以进一步降低理论最小值的下限。业界常用的Topo排序算法有BFS,DFS,逆DFS,在不同的图结构下也会有较大的差异,常规排序算法没有考虑内存相关因素。
常规Topo技术示例如下。
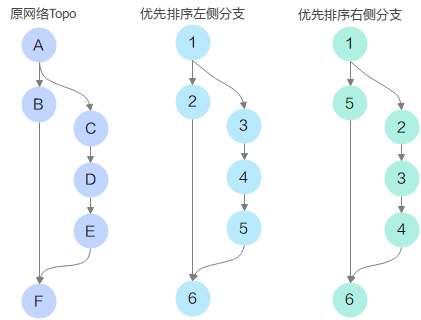
如上网络结果所示,DFS选择左侧分支先排序时,如图10中的“优先排序左侧分支”,会导致B的内存生命周期较长[2,6],无法和C,D内存复用。DFS选择右侧分支先排序时,如图10中的“优先排序右侧分支”,B的内存生命周期是[5,6],可以和C,D内存进行复用,但是又会导致A内存的生命周期变长由[1,3]变为[1,5],因此常规Topo排序算法无法做出针对内存的最优选择,最后复用后内存大小是一个不确定的结果。
3.2 GE Topo优化技术
GE针对Topo技术进行了优化,首先做常规Topo排序,然后对排序结果进行处理,结合内存策略把某些节点的排序重新调整,从而确保调整后内存大小是可以降低的。其中一个优化策略就是把输入是长生命周期的节点向后移动,移动到排序最靠前的一个输出节点前。
长生命周期内存的判断规则:
•固定规则,根据类型判断,如果某节点的输入是Variable、Constant、Const类型,或者不做复用的Data、RefData类型,则此节点可向后移动,因为这些类型的节点内存本身不做复用,所以节点向后排不影响内存生命周期。
•动态规则,根据Topo排序结果进行判断,排序完成后,理论上可以计算出某节点的输入节点内存的最大生命周期,标记为L1,然后寻找本节点的输出内存的最小生命周期,标记为L2,如果L1 > L2,则可以将本节点移动到L2前。
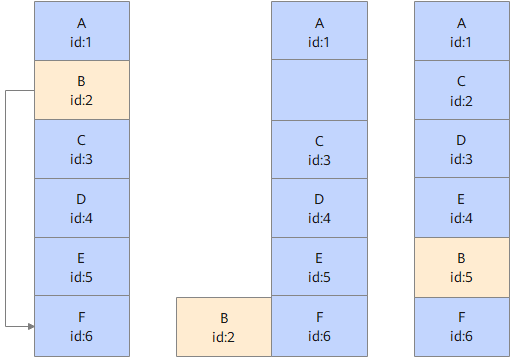
如下图所示,假设节点A是Variable类型,则可以将节点B移动到输出节点F的前面,进行排序优化。
3.3 GE Topo优化效果
做了Topo优化后,降低了网络的内存理论最小值,最后内存复用后的大小会进一步下降,如下是几个网络的实际测试结果。
|
网络 |
优化前内存(G) |
优化后内存(G) |
收益率 |
|
Baichuan-13B |
18.89 |
6.91 |
63.42% |
|
LLaMA-13B |
45.42 |
33.37 |
26.53% |
4 更多介绍
GE内存复用技术的相关介绍就到这里,欢迎大家关注后续技术分享。如需获取更多学习资源请登录昇腾社区。
往期推荐: