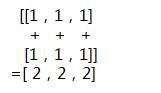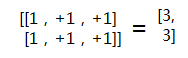深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
一个完整的神经网络若想实现其功能,必须将其拆分为多个基本功能单元,例如卷积(Convolution)、全连接(Fully-connected, FC)等,这些基本功能单元被称为算子(Operator,简称OP)。
对每一个独立的算子,用户需要编写算子描述文件,描述算子的整体逻辑、计算步骤以及相关硬件平台信息等。然后用深度学习编译器对算子描述文件进行编译,生成可在特定硬件平台上运行的二进制文件后,将待处理数据作为输入,运行算子即可得到期望输出。将神经网络所有被拆分后的算子都按照上述过程处理后, 再按照输入输出关系串联起来即可得到整网运行结果。 该过程如下图所示:

下面介绍算子中常用的基本概念。
算子名称(Name)
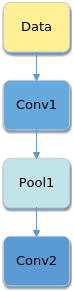
算子的名称,用于标志网络中的某个算子,同一网络中算子的名称需要保持唯一。如下图所示Conv1,Pool1,Conv2都是此网络中的算子名称,其中Conv1与Conv2算子的类型为Convolution,表示分别做一次卷积运算。
算子类型(Type)
网络中每一个算子根据算子类型进行算子实现的匹配,相同类型的算子的实现逻辑相同。在一个网络中同一类型的算子可能存在多个,例如上图中的Conv1算子与Conv2算子的类型都为Convolution。
张量(Tensor)
Tensor是算子计算数据的容器,TensorDesc(Tensor描述符)是对Tensor中数据的描述,TensorDesc数据结构包含如下属性如表1所示。
属性 |
定义 |
|---|---|
名称(name) |
用于对Tensor进行索引,不同Tensor的name需要保持唯一。 |
形状(shape) |
Tensor的形状,比如(10,)或者(1024, 1024)或者(2, 3, 4)等。详细介绍请参见形状(Shape)。 默认值:无 形式:(i1, i2,…in),其中i1到in均为正整数 |
数据类型(dtype) |
功能描述:指定Tensor对象的数据类型。 默认值:无 取值范围:float16, float32, int8, int16, int32, uint8, uint16, bool等。 说明:
不同计算操作支持的数据类型不同,详细请参见接口参考。 |
数据排布格式(format) |
数据的物理排布格式,定义了解读数据的维度。 详细请参见数据排布格式。 |
形状(Shape)
张量的形状,以(D0, D1, … ,Dn-1)的形式表示,D0到Dn是任意的正整数。
如形状(3,4)表示第一维有3个元素,第二维有4个元素,(3,4)表示一个3行4列的矩阵数组。
在形状的小括号中有多少个数字,就代表这个张量是多少维的张量。形状的第一个元素要看张量最外层的中括号中有几个元素,形状的第二个元素要看张量中从左边开始数第二个中括号中有几个元素,依此类推。例如:
张量 |
形状 |
|---|---|
1 |
(0,) |
[1,2,3] |
(3,) |
[[1,2],[3,4]] |
(2, 2) |
[[[1,2],[3,4]], [[5,6],[7,8]]] |
(2, 2, 2) |
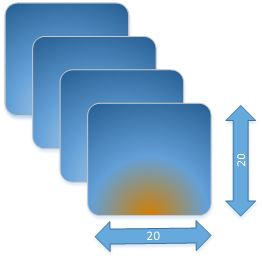
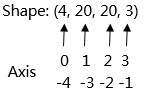
物理含义我们应该怎么理解呢?假设我们有这样一个shape=(4, 20, 20, 3)。
假设有一些照片,每个像素点都由红/绿/蓝3色组成,即shape里面3的含义,照片的宽和高都是20,也就是20*20=400个像素,总共有4张的照片,这就是shape=(4, 20, 20, 3)的物理含义。
如果体现在编程上,可以简单把shape理解为操作Tensor的各层循环,比如我们要对shape=(4, 20, 20, 3)的A tensor进行操作,循环语句如下:
produce A {
for (i, 0, 4) {
for (j, 0, 20) {
for (p, 0, 20) {
for (q, 0, 3) {
A[((((((i*20) + j)*20) + p)*3) + q)] = a_tensor[((((((i*20) + j)*20) + p)*3) + q)]
}
}
}
}
}
轴(axis)
轴是相对Shape来说的,轴代表张量的shape的下标,比如张量a是一个5行6列的二维数组,即shape是(5,6),则axis=0表示是张量中的第一维,即行。axis=1表示是张量中的第二维,即列。
例如张量数据[[[1,2],[3,4]], [[5,6],[7,8]]],Shape为(2,2,2),则轴0代表第一个维度的数据即[[1,2],[3,4]]与[[5,6],[7,8]]这两个矩阵,轴1代表第二个维度的数据即[1,2]、[3,4]、[5,6]、[7,8]这四个数组,轴2代表第三个维度的数据即1,2,3,4,5,6,7,8这八个数。
轴axis可以为负数,此时表示是倒数第axis个维度。
N维Tensor的轴有:0 , 1, 2,……,N-1。
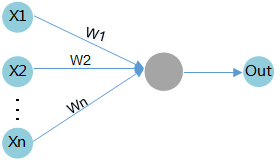
权重(weight)
当输入数据进入计算单元时,会乘以一个权重。例如,如果一个算子有两个输入,则每个输入会分配一个关联权重,一般将认为较重要数据赋予较高的权重,不重要的数据赋予较小的权重,为零的权重则表示特定的特征是无需关注的。
如图5所示,假设输入数据为X1,与其相关联的权重为W1,那么在通过计算单元后,数据变为了X1*W1。
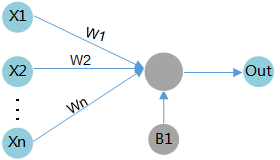
偏差(bias)
偏差是除了权重之外,另一个被应用于输入数据的线性分量。它被加到权重与输入数据相乘的结果中,用于改变权重与输入相乘所得结果的范围。
如图6所示,假设输入数据为X1,与其相关联的权重为W1,偏差为B1,那么在通过计算单元后,数据变为了X1*W1+B1。
广播
TBE支持的广播规则:可以将一个数组的每一个维度扩展为一个固定的shape,需要被扩展的数组的每个维度的大小或者与目标shape相等,或者为1,广播会在元素个数为1的维度上进行。
例如:原数组a的维度为(2, 1, 64),目标shape为(2, 128, 64),则通过广播可以将a的维度扩展为目标shape(2, 128, 64)。
TBE的计算接口加、减、乘、除等不支持自动广播,要求输入的两个Tensor的shape相同,所以操作前,我们需要先计算出目标shape,然后将每个输入Tensor广播到目标shape再进行计算。
例如,Tensor A的shape为(4, 3, 1, 5),Tensor B的shape为(1, 1, 2, 1),执行Tensor A + Tensor B ,具体计算过程如下:



降维-Reduction
降维有很多种算子,例如TensorFlow中的Sum、Min、Max、All、Mean等,Caffe中的Reduction算子,此处以Caffe中的Reduction算子为例进行讲解,Reduction是将多维数组的指定轴及之后的数据做降维操作。
- Reduction的属性
- ReductionOp:常见算子支持的操作类型,包含四种类型。
表3 Reduction算子操作类型 算子类型
说明
SUM
对被reduce的所有轴求和。
ASUM
对被reduce的所有轴求绝对值后求和。
SUMSQ
对被reduce的所有轴求平方后再求和。
MEAN
对被reduce的所有轴求均值。
- axis:Reduction需要指定一个轴,会对此轴及其之后的轴进行reduce操作,取值范围为:[-N,N-1]。
- coeff:标量,对结果缩放,如果值为1,则不进行缩放。
- ReductionOp:常见算子支持的操作类型,包含四种类型。
下面通过示例了解降维操作。