启用进程级在线恢复后,报错There is unsafe data in the input tensor,恢复失败
2025/01/26
30
问题信息
| 问题来源 | 产品大类 | 产品子类 | 关键字 |
|---|---|---|---|
| 官方 | 集群调度 | 断点续训 | 进程级在线恢复、There is unsafe data in the input tensor |
问题描述
训练任务在发生故障后启用进程级在线恢复(Step级别重计算恢复)功能,在恢复完成后继续训练,恢复训练后第一个迭代还没完成又报错unsafe data,恢复失败。
原因分析
故障发生时涉及该故障的Tensor会被标记为unsafe data,数据将不再可信,如果该Tensor为全局变量,此时需要对其进行重建修复。被标记为unsafe data的Tensor在计算中被访问时会抛出错误,错误信息:“There is unsafe data in the input tensor.”,此时需结合报错栈定位此时访问的Tensor对象。
解决措施
当定位到该被访问的Tensor对象时,首先判断其对训练过程的影响:
- 场景一:若其与训练迭代无依赖关系,则可在rollback阶段对其重新初始化,将其释放。
- 场景二:若其与训练迭代有依赖关系,且与副本优化器映射关系一致时,则需要在repair阶段对其进行重建并通过点对点通信修复该Tensor的数据。

进程级别重调度及进程级在线恢复通过寻找有效的副本,拼凑出一份完整的优化器状态数据,当训练集群故障较多,通过副本仍然无法拼凑出一个完整副本时,则会无法完成重调度。
此外还应注意在重建或重新初始化之前避免访问该Tensor对象。为预防全局变量中存在被标记为unsafe data的Tensor没有被故障修复框架修复而导致修复失败,建议排查训练框架中所使用的全局Tensor,确保其被故障修复框架跟踪并正确修复。
处理案例
- 针对场景一的处理案例如下。
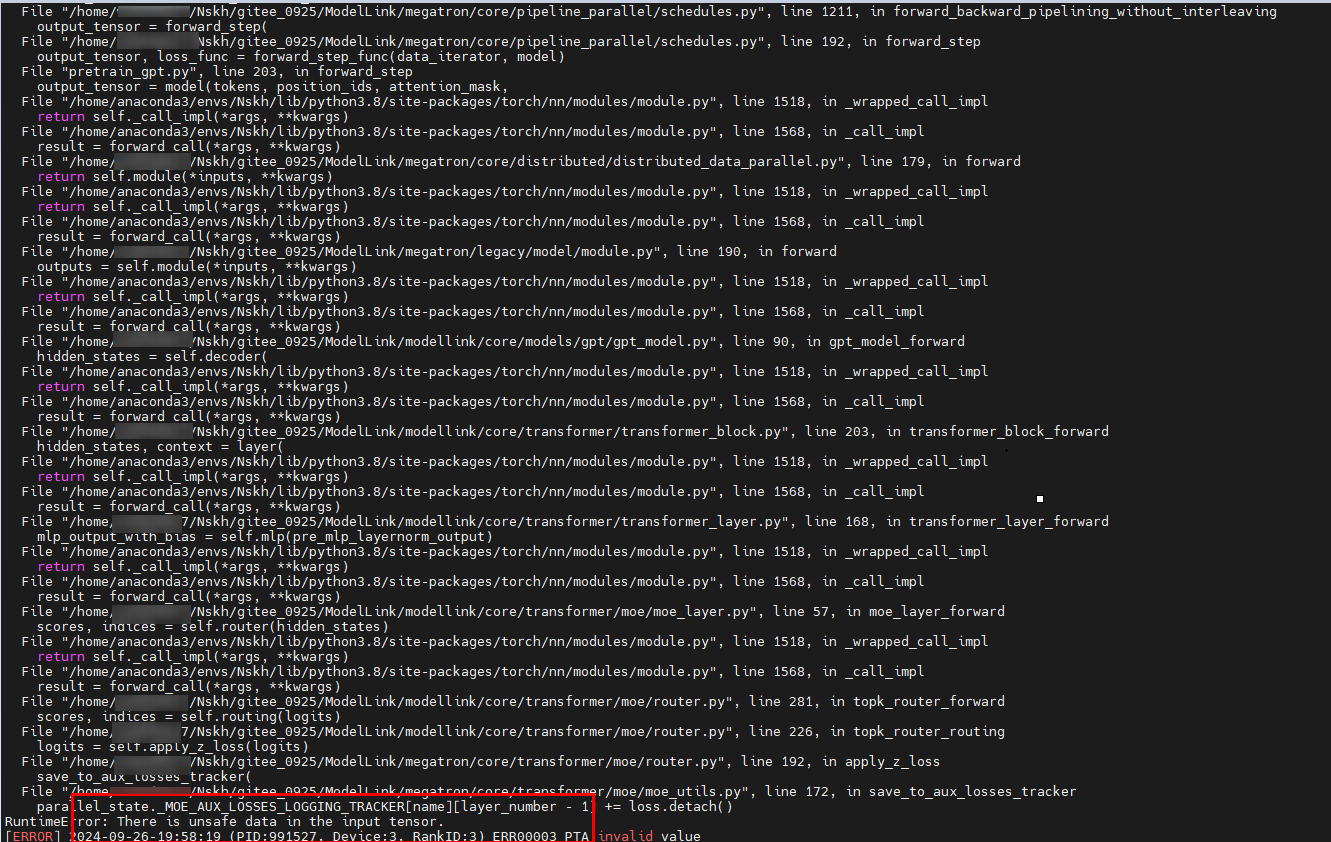
如图1 恢复失败所示,Megatron框架中,当使用TensorBoard记录训练日志等信息,并开启MoE特性时,会在_MOE_AUX_LOSSES_LOGGING_TRACKER中创建一个Tensor记录loss数据,并被TensorBoard访问读取。该全局变量_MOE_AUX_LOSSES_LOGGING_TRACKER中的Tensor发生故障被标记为unsafe data后,再次访问该Tensor会导致报错,根据调用栈可以找到该Tensor所在位置。
根据代码上下文判断,该Tensor仅用于记录loss值,并且在每个迭代结束后将值置为0,因此在rollback阶段对该全局变量重新初始化为空字典,由框架在后续训练中使用,详见mindio_ttp/adaptor/modellink_adaptor.py中feature_rollback函数。
- 针对场景二的处理案例如下。
假设用户自定义的全局变量Tensor名为global_tensor,应该在mindio_ttp/adaptor/modellink_adaptor.py的recv_rank_repair函数尾部增加重建及接收逻辑,故障卡接受副本卡保存的数据:
recv_tensor = torch.empty(size, dtype=type, device="npu")
torch.distributed.recv(recv_tensor, src=src_rank, group=repair_group)
global_tesor.data.copy_(recv_tensor)
并在mindio_ttp/adaptor/modellink_adaptor.py的send_rank_repair函数尾部增加发送逻辑,向故障卡发送该全局Tensor的数据:
torch.distributed.send(global_tensor, dst=dest_rank, group=repair_group)
本页内容