SVD算子处理大shape时报错“rtStreamSynchronize execute failed”
2023/09/14
245
问题信息
| 问题来源 | 产品大类 | 关键字 |
|---|---|---|
| 官方 | 算子开发 | 无 |
问题现象描述
通过单算子调用发现SVD算子在处理大shape时,执行超时,报错“rtStreamSynchronize execute failed”。
将shape改成[768, 768]后可以正常执行。
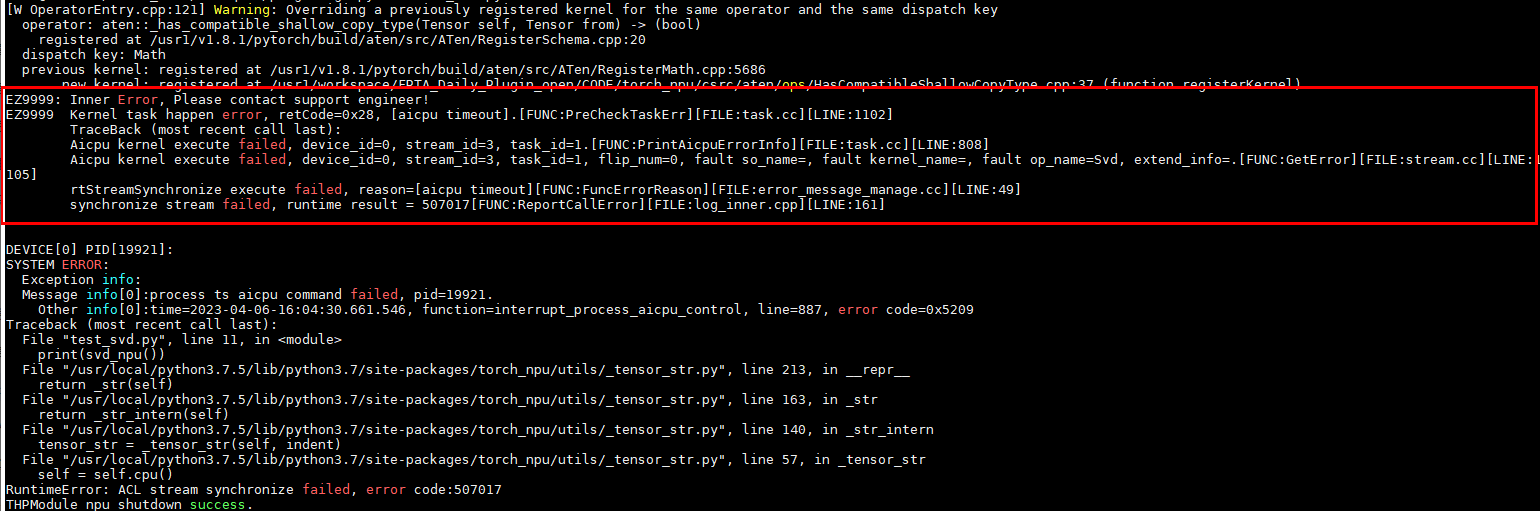
单算子用例脚本如下:
原因分析
- 开通debug日志,查看device日志,发现SVD算子执行超时(2.8s超时)。

- 查看该算子是调用的TF Adapter。

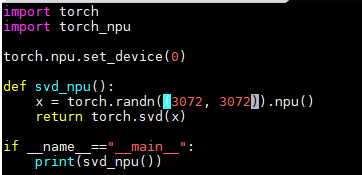
- 查看算子库信息(路径:/usr/local/Ascend/ascend-toolkit/latest/opp/built-in/op_impl/aicpu/aicpu_kernel/config/aicpu_kernel.json)中没有注册该算子,
但TF的算子库信息(路径:/usr/local/Ascend/ascend-toolkit/latest/opp/built-in/op_impl/aicpu/tf_kernel/config/tf_kernel.json)中有注册。
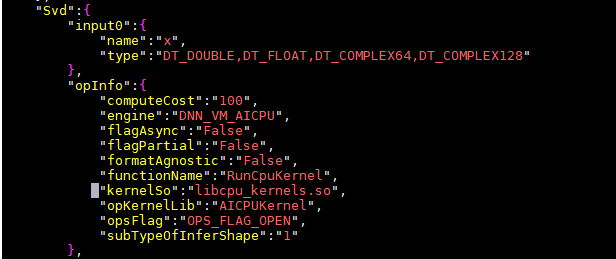
可以确认该算子的实现并没有调用库上的算子实现。
- 该AI CPU算子自研引擎没有注册,它是可以调用TF或者PyTorch引擎的,GE不管上层算子是来自torch api还是TF的api。
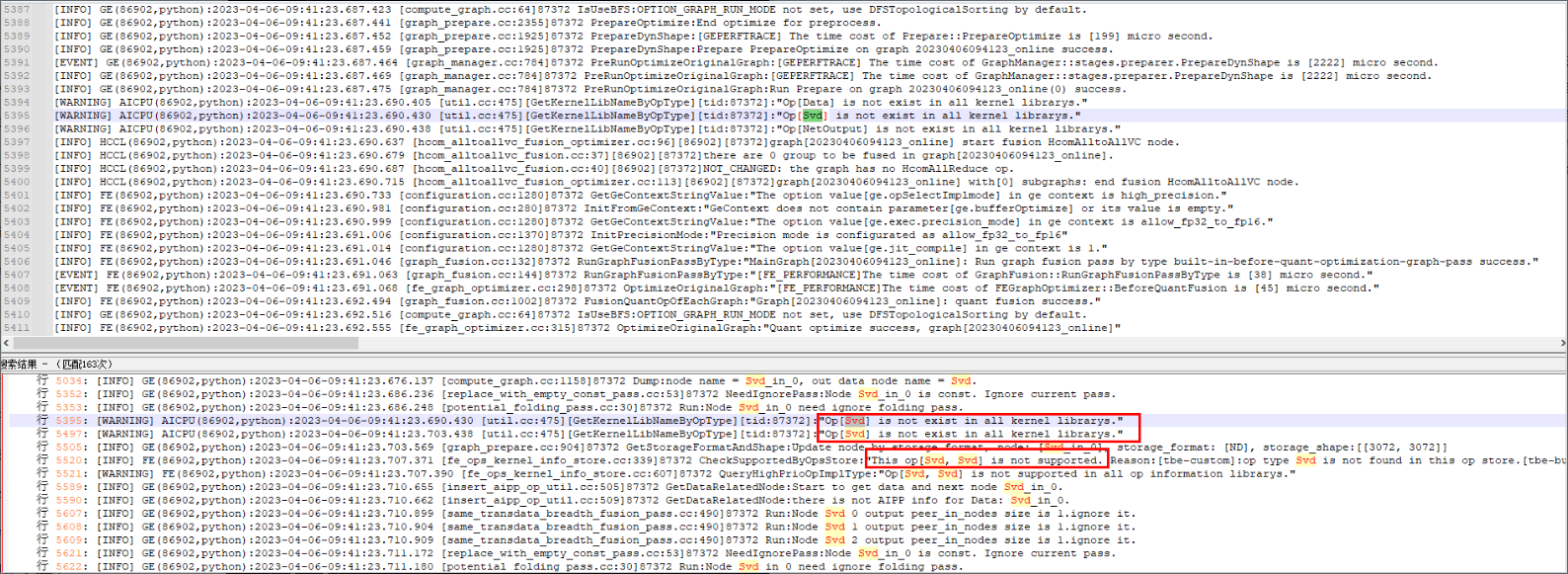
在aicpu_kernel.json中注册该算子,发现该算子没有被编译到libcpu_kernels.so中,只在TFKernel.so中。
解决措施
采用规避方案,将该SVD算子在cpu上执行:x=torch.randn((3072, 3072)).cpu()。
本页内容