aclnnTrunc/aclnnInplaceTrunc
接口原型

- aclnnTrunc和aclnnInplaceTrunc实现相同的功能,其使用区别如下,请根据自身实际场景选择合适的算子。
- aclnnTrunc:需新建一个输出张量对象存储计算结果。
- aclnnInplaceTrunc:无需新建输出张量对象,直接在输入张量的内存中存储计算结果。
- 每个算子分为两段接口,必须先调用“aclnnXxxGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnXxx”接口执行计算。
- aclnnTrunc两段式接口如下:
- 第一段接口:aclnnStatus aclnnTruncGetWorkspaceSize(const aclTensor *self, aclTensor *out, uint64_t *workspaceSize, aclOpExecutor **executor)
- 第二段接口:aclnnStatus aclnnTrunc(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
- aclnnInplaceTrunc两段式接口如下:
- 第一段接口:aclnnStatus aclnnInplaceTruncGetWorkspaceSize(const aclTensor *selfRef, uint64_t *workspaceSize, aclOpExecutor **executor)
- 第二段接口:aclnnStatus aclnnInplaceTrunc(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
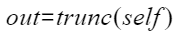
aclnnTruncGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnTruncGetWorkspaceSize(const aclTensor *self, aclTensor *out, uint64_t *workspaceSize, aclOpExecutor **executor)
- 参数说明:
- self:Device侧的aclTensor,数据类型支持FLOAT、FLOAT16,shape维度不大于8,且shape和数据类型要与out一致。支持非连续的Tensor,数据格式支持ND。
- out:Device侧的aclTensor,数据类型支持FLOAT、FLOAT16,shape维度不大于8,且shape和数据类型要与self一致。支持非连续的Tensor,数据格式支持ND。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的self或out是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):
- self和out的数据类型和数据格式不在支持的范围内。
- self和out的shape不一致。
- self和out的数据类型不一致。
- self和out的维度超过8。
aclnnTrunc
- 接口定义:
aclnnStatus aclnnTrunc(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnTruncGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
aclnnInplaceTruncGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnInplaceTruncGetWorkspaceSize(const aclTensor *selfRef, uint64_t *workspaceSize, aclOpExecutor **executor)
- 参数说明:
- selfRef:Device侧的aclTensor,输入/输出张量,数据类型支持FLOAT、FLOAT16,shape维度不大于8。支持非连续的Tensor,数据格式支持ND。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的selfRef是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):
- selfRef的数据类型和数据格式不在支持的范围内。
- selfRef的维度大于8。
aclnnInplaceTrunc
- 接口定义:
aclnnStatus aclnnInplaceTrunc(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnInplaceTruncGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
调用示例
#include <iostream>
#include <vector>
#include "acl/acl.h"
#include "aclnnop/aclnn_trunc.h"
#define CHECK_RET(cond, return_expr) \
do { \
if (!(cond)) { \
return_expr; \
} \
} while (0)
#define LOG_PRINT(message, ...) \
do { \
printf(message, ##__VA_ARGS__); \
} while (0)
int64_t GetShapeSize(const std::vector<int64_t>& shape) {
int64_t shape_size = 1;
for (auto i : shape) {
shape_size *= i;
}
return shape_size;
}
int Init(int32_t deviceId, aclrtContext* context, aclrtStream* stream) {
// 固定写法,AscendCL初始化
auto ret = aclInit(nullptr);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclInit failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetDevice(deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateContext(context, deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetCurrentContext(*context);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetCurrentContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateStream failed. ERROR: %d\n", ret); return ret);
return 0;
}
template <typename T>
int CreateAclTensor(const std::vector<T>& hostData, const std::vector<int64_t>& shape, void** deviceAddr,
aclDataType dataType, aclTensor** tensor) {
auto size = GetShapeSize(shape) * sizeof(T);
// 调用aclrtMalloc申请device侧内存
auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ret);
// 调用aclrtMemcpy将Host侧数据拷贝到device侧内存上
ret = aclrtMemcpy(*deviceAddr, size, hostData.data(), size, ACL_MEMCPY_HOST_TO_DEVICE);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMemcpy failed. ERROR: %d\n", ret); return ret);
// 计算连续tensor的strides
std::vector<int64_t> strides(shape.size(), 1);
for (int64_t i = shape.size() - 2; i >= 0; i--) {
strides[i] = shape[i + 1] * strides[i + 1];
}
// 调用aclCreateTensor接口创建aclTensor
*tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND,
shape.data(), shape.size(), *deviceAddr);
return 0;
}
int main() {
// 1. (固定写法)device/context/stream初始化, 参考AscendCL对外接口列表
// 根据自己的实际device填写deviceId
int32_t deviceId = 0;
aclrtContext context;
aclrtStream stream;
auto ret = Init(deviceId, &context, &stream);
// check根据自己的需要处理
CHECK_RET(ret == 0, LOG_PRINT("Init acl failed. ERROR: %d\n", ret); return ret);
// 2. 构造输入与输出,需要根据API的接口自定义构造
std::vector<int64_t> selfShape = {4, 2};
std::vector<int64_t> outShape = {4, 2};
void* selfDeviceAddr = nullptr;
void* outDeviceAddr = nullptr;
aclTensor* self = nullptr;
aclTensor* out = nullptr;
std::vector<float> selfHostData = {0, 1, 2, 3, 4, 5, 6, 7};
std::vector<float> outHostData = {0, 0, 0, 0, 0, 0, 0, 0};
// 创建self aclTensor
ret = CreateAclTensor(selfHostData, selfShape, &selfDeviceAddr, aclDataType::ACL_FLOAT, &self);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 创建out aclTensor
ret = CreateAclTensor(outHostData, outShape, &outDeviceAddr, aclDataType::ACL_FLOAT, &out);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 3.调用CANN算子库API,需要修改为具体的算子接口
uint64_t workspaceSize = 0;
aclOpExecutor* executor;
// 调用aclnnTrunc第一段接口
ret = aclnnTruncGetWorkspaceSize(self, out, &workspaceSize, &executor);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnTruncGetWorkspaceSize failed. ERROR: %d\n", ret); return ret);
// 根据第一段接口计算出的workspaceSize申请device内存
void* workspaceAddr = nullptr;
if (workspaceSize > 0) {
ret = aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("allocate workspace failed. ERROR: %d\n", ret); return ret;);
}
// 调用aclnnTrunc第二段接口
ret = aclnnTrunc(workspaceAddr, workspaceSize, executor, stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnTrunc failed. ERROR: %d\n", ret); return ret);
// 4. (固定写法)同步等待任务执行结束
ret = aclrtSynchronizeStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSynchronizeStream failed. ERROR: %d\n", ret); return ret);
// 5. 获取输出的值,将device侧内存上的结果拷贝至Host侧,需要根据具体API的接口定义修改
auto size = GetShapeSize(outShape);
std::vector<float> resultData(size, 0);
ret = aclrtMemcpy(resultData.data(), resultData.size() * sizeof(resultData[0]), outDeviceAddr, size * sizeof(float),
ACL_MEMCPY_DEVICE_TO_HOST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("copy result from device to host failed. ERROR: %d\n", ret); return ret);
for (int64_t i = 0; i < size; i++) {
LOG_PRINT("result[%ld] is: %f\n", i, resultData[i]);
}
// 6. 释放aclTensor和aclScalar,需要根据具体API的接口定义修改
aclDestroyTensor(self);
aclDestroyTensor(out);
return 0;
}
父主题: NN类算子接口