快速入门
在本章节中,您可以通过一个简单的图片分类应用代码示例了解使用pyACL接口(Python语言接口)开发应用的基本过程以及开发过程中涉及的关键概念。
什么是图片分类应用?
“图片分类应用”顾名思义标识图片所属的分类。
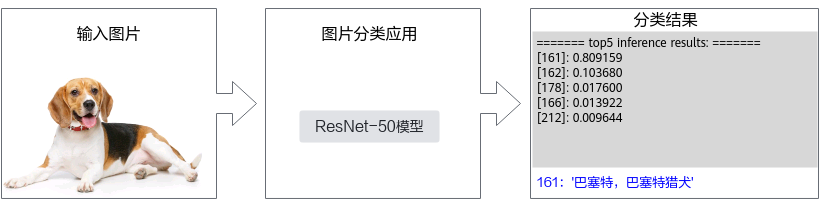
“图片分类应用”是怎么做到这一点的呢?首先,需要有一个能做到图片分类的模型,我们可以直接使用一些训练好的开源模型,也可以基于开源模型的源码进行修改、重新训练,还可以自己基于算法、框架构建适合自己的模型。
本次快速入门样例,我们直接获取已训练好的开源模型,这种方式相对简单,此处我们选择的是ONNX框架的ResNet-50模型。
ResNet-50模型的基本介绍如下:
- 输入数据:RGB格式、224*224分辨率的输入图片。
- 输出数据:图片的类别标签及其对应置信度。

- 置信度是指图片所属某个类别可能性。
- 类别标签和类别的对应关系与训练模型时使用的数据集有关,需要查阅对应数据集的标签及类别的对应关系。
前提条件
- 已在环境上部署昇腾AI软件栈。
- 安装环境,请参见应用开发环境准备。
- 安装必要的Python软件依赖(Pillow、numpy)。
pip3 install pillow numpy
了解基本概念
了解开发过程
pyACL(Python Ascend Computing Language)是一套在AscendCL的基础上使用CPython封装得到的Python API库,使用户可以通过Python进行昇腾AI处理器的运行管理、资源管理等,实现在昇腾CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等能力。
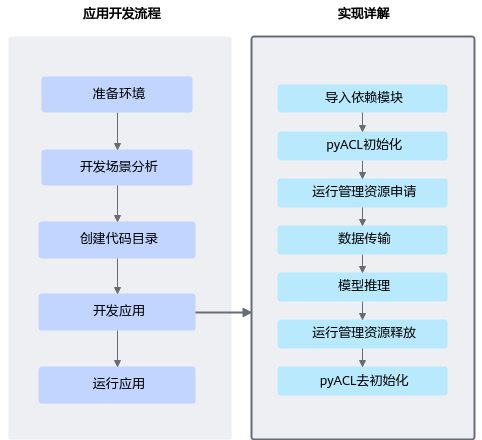
了解了这些大步骤后,下面我们再展开来说明开发应用具体涉及哪些关键功能?各功能又使用哪些pyACL接口,这些pyACL接口怎么串联?
虽然此时您可能不理解所有细节,但这也不影响,通过快速入门旨在先了解整体的代码逻辑,后续再深入学习,了解其它细节。
创建代码目录
请参考以下目录结构,在开发环境中下创建“first_app”代码目录(例如“$HOME”目录)。
first_app
├── data
│ ├── dog1_1024_683.jpg //测试图片1
│ └── dog2_1024_683.jpg //测试图片2
└── model //用于存放ONNX ResNet-50模型文件
└── resnet50.onnx
其中,需准备以下数据与模型。
- 准备测试数据,本次样例需要使用两张动物图片,请从以下链接获取,将下载好的图片上传至“first_app/data”目录。
- 准备模型数据,参考以下命令,将ONNX模型下载至“model”目录下或通过模型获取链接下载到本地后上传到运行环境。
cd $HOME/first_app/model wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/resnet50/resnet50.onnx
- 模型转换,对于开源框架的模型,不能直接在昇腾AI处理器上进行推理,需要使用ATC(Ascend Tensor Compiler)工具将开源框架的网络模型转换为适配昇腾AI处理器的离线模型(*.om文件)。
执行以下命令,将原始模型转换为昇腾AI处理器能识别的*.om模型文件。请注意,执行命令的用户需具有命令中相关路径的可读、可写权限。
atc --model=resnet50.onnx --framework=5 --output=resnet50 --input_shape="actual_input_1:1,3,224,224" --soc_version= <soc_version>
各参数的解释如下,详细约束说明请参见《ATC工具使用指南》。
- --model:ResNet-50网络的模型文件的路径。
- --framework:原始框架类型。5表示ONNX。
- --output:resnet50.om模型文件的路径。请注意,记录保存该om模型文件的路径,后续开发应用时需要使用。
- --input_shape:模型输入数据的shape。
- --soc_version:昇腾AI处理器的版本。
如果无法确定当前设备的soc_version,则在安装NPU驱动包的服务器执行npu-smi info命令进行查询,在查询到的“Name”前增加Ascend信息,例如“Name”对应取值为xxxyy,实际配置的soc_version值为Ascendxxxyy。
开发应用
在“first_app”目录下创建“first_app.py”文件并依次写入以下内容。
- 引入pyACL必要的模块,定义pyACL常量。
import os import acl import numpy as np from PIL import Image ACL_MEM_MALLOC_HUGE_FIRST = 0 ACL_MEMCPY_HOST_TO_DEVICE = 1 ACL_MEMCPY_DEVICE_TO_HOST = 2
- 定义模型对象。网络模型对象中应当包含以下函数。
- 初始化函数。
- 执行推理任务函数。
- 析构函数。
对于后续的使用,用户只需要调用网络模型中的forward函数,传入对应的输入数据即可获得相应的输出。
class net: # def __init__(self, model_path): # 初始化函数,需要在后续步骤中实现。 # def forward(self, inputs): # 执行推理任务,需要在后续步骤中实现。 # def __del__(self): # 析构函数,按照初始化资源的相反顺序释放资源,需要在后续步骤中实现。 - 实现初始化方法,具体涉及以下步骤(请在net类中实现)。
- 调用acl.init接口进行初始化,在使用pyACL开发应用时,需要先初始化pyACL(在完成所有pyACL接口调用后,还需进行去初始化)。初始化时,也可通过JSON配置文件,向初始化接口传入配置参数(例如,传入性能相关的采集信息配置)。
- 通过ID,调用acl.rt.set_device接口指定具体的计算设备(Device)。
- 加载模型。
- 在此处样例选择调用acl.mdl.load_from_file接口加载om模型文件。
- 调用acl.mdl.create_desc接口创建模型描述信息。
- 根据加载成功的模型ID,调用acl.mdl.get_desc接口获取该模型的描述信息。
- 创建输入数据集与输出数据集,对应方法在4中实现。
def __init__(self, model_path): # 初始化函数 self.device_id = 0 # step1: 初始化 ret = acl.init() # 指定运算的Device ret = acl.rt.set_device(self.device_id) # step2: 加载模型,本示例为ResNet-50模型 # 加载离线模型文件,返回标识模型的ID self.model_id, ret = acl.mdl.load_from_file(model_path) # 创建空白模型描述信息,获取模型描述信息的指针地址 self.model_desc = acl.mdl.create_desc() # 通过模型的ID,将模型的描述信息填充到model_desc ret = acl.mdl.get_desc(self.model_desc, self.model_id) # step3:创建输入输出数据集 # 创建输入数据集 self.input_dataset, self.input_data = self.prepare_dataset('input') # 创建输出数据集 self.output_dataset, self.output_data = self.prepare_dataset('output') - 实现数据集创建方法(请在net类中实现)。
在调用pyACL接口进行模型推理时,模型推理有输入、输出数据,输入、输出数据需要按照pyACL规定的数据类型存放。相关数据类型如下:
- 使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
模型加载成功后,用户可根据模型的ID,调用该数据类型下的操作接口获取该模型的描述信息,进而从模型的描述信息中获取模型输入/输出的个数、内存大小、维度信息、Format、数据类型等信息。
- 使用aclDataBuffer类型的数据来描述每个输入/输出的内存地址、内存大小。
调用aclDataBuffer类型下的操作接口获取内存地址、内存大小等,便于向内存中存放输入数据、获取输出数据。
- 使用aclmdlDataset类型的数据描述模型的输入/输出数据。
模型可能存在多个输入、多个输出,调用aclmdlDataset类型的操作接口添加多个aclDataBuffer类型的数据。
图3 aclmdlDataset类型与aclDataBuffer类型的关系
def prepare_dataset(self, io_type): # 准备数据集 if io_type == "input": # 获得模型输入的个数 io_num = acl.mdl.get_num_inputs(self.model_desc) acl_mdl_get_size_by_index = acl.mdl.get_input_size_by_index else: # 获得模型输出的个数 io_num = acl.mdl.get_num_outputs(self.model_desc) acl_mdl_get_size_by_index = acl.mdl.get_output_size_by_index # 创建aclmdlDataset类型的数据,描述模型推理的输入。 dataset = acl.mdl.create_dataset() datas = [] for i in range(io_num): # 获取所需的buffer内存大小 buffer_size = acl_mdl_get_size_by_index(self.model_desc, i) # 申请buffer内存 buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST) # 从内存创建buffer数据 data_buffer = acl.create_data_buffer(buffer, buffer_size) # 将buffer数据添加到数据集 _, ret = acl.mdl.add_dataset_buffer(dataset, data_buffer) datas.append({"buffer": buffer, "data": data_buffer, "size": buffer_size}) return dataset, datas - 使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等)。
- 实现同步推理方法(请在net类中实现)。
def forward(self, inputs): # 执行推理任务 # 遍历所有输入,拷贝到对应的buffer内存中 input_num = len(inputs) for i in range(input_num): bytes_data = inputs[i].tobytes() bytes_ptr = acl.util.bytes_to_ptr(bytes_data) # 将图片数据从Host传输到Device。 ret = acl.rt.memcpy(self.input_data[i]["buffer"], # 目标地址 device self.input_data[i]["size"], # 目标地址大小 bytes_ptr, # 源地址 host len(bytes_data), # 源地址大小 ACL_MEMCPY_HOST_TO_DEVICE) # 模式:从host到device # 执行模型推理。 ret = acl.mdl.execute(self.model_id, self.input_dataset, self.output_dataset) # 处理模型推理的输出数据,输出top5置信度的类别编号。 inference_result = [] for i, item in enumerate(self.output_data): buffer_host, ret = acl.rt.malloc_host(self.output_data[i]["size"]) # 将推理输出数据从Device传输到Host。 ret = acl.rt.memcpy(buffer_host, # 目标地址 host self.output_data[i]["size"], # 目标地址大小 self.output_data[i]["buffer"], # 源地址 device self.output_data[i]["size"], # 源地址大小 ACL_MEMCPY_DEVICE_TO_HOST) # 模式:从device到host # 从内存地址获取bytes对象 bytes_out = acl.util.ptr_to_bytes(buffer_host, self.output_data[i]["size"]) # 按照float32格式将数据转为numpy数组 data = np.frombuffer(bytes_out, dtype=np.float32) inference_result.append(data) vals = np.array(inference_result).flatten() # 对结果进行softmax转换 vals = np.exp(vals) vals = vals / np.sum(vals) return vals - 实现析构方法(请在net类中实现)。
- 销毁数据集资源(buffer数据、buffer内存、输入数据集、输出数据集)。
- 销毁模型描述、卸载模型。
- 释放计算资源。
- 所有pyACL接口调用结束后(或在进程退出前),调用acl.finalize接口进行pyACL进行去初始化。
在推理过程中可能会抛出异常,请将资源释放步骤实现在析构方法中确保资源能够得到正确释放。以下内容仅供参考,实际情况下需要考虑更多情况下的资源释放问题。
def __del__(self): # 析构函数 按照初始化资源的相反顺序释放资源。 # 销毁输入输出数据集 for dataset in [self.input_data, self.output_data]: while dataset: item = dataset.pop() ret = acl.destroy_data_buffer(item["data"]) # 销毁buffer数据 ret = acl.rt.free(item["buffer"]) # 释放buffer内存 ret = acl.mdl.destroy_dataset(self.input_dataset) # 销毁输入数据集 ret = acl.mdl.destroy_dataset(self.output_dataset) # 销毁输出数据集 # 销毁模型描述 ret = acl.mdl.destroy_desc(self.model_desc) # 卸载模型 ret = acl.mdl.unload(self.model_id) # 释放device ret = acl.rt.reset_device(self.device_id) # acl去初始化 ret = acl.finalize() - 实现图像预处理函数。
def transfer_pic(input_path): # 图像预处理 input_path = os.path.abspath(input_path) with Image.open(input_path) as image_file: # 缩放为224*224 img = image_file.resize((224, 224)) # 转换为float32类型ndarray img = np.array(img).astype(np.float32) # 根据imageNet图片的均值和方差对图片像素进行归一化 img -= [123.675, 116.28, 103.53] img /= [58.395, 57.12, 57.375] # RGB通道交换顺序为BGR img = img[:, :, ::-1] # resnet50为色彩通道在前 img = img.transpose((2, 0, 1)) # 返回并添加batch通道 return np.array([img]) - 调用forward函数(具体实现请参见5),执行同步推理并在屏幕中打印top5类别编号及置信度。
def print_top_5(data): top_5 = data.argsort()[::-1][:5] print("======== top5 inference results: =============") for j in top_5: print("[%d]: %f" % (j, data[j])) if __name__ == "__main__": resnet50 = net('./model/resnet50.om') image_paths = ["./data/dog1_1024_683.jpg", "./data/dog2_1024_683.jpg"] for path in image_paths: # 图像预处理,此处仅供参考,用户按照自己需求进行预处理 image = transfer_pic(path) # 将数据按照每个输入的顺序构造list传入,当前示例的ResNet-50模型只有一个输入 result = resnet50.forward([image]) # 输出top_5 print_top_5(result) del resnet50
运行应用
将编写好的“first_app”文件夹及内容上传到运行环境,进入到代码目录下,检查环境变量配置是否正确,然后执行以下命令。
python3 first_app.py
可以得到如下输出,分别为两张测试图片的top5分类信息。
其中[161]: 0.809159表示的是类别标识索引“161”的置信度为“0.809159”。
======== top5 inference results: ============= [161]: 0.809159 [162]: 0.103680 [178]: 0.017600 [166]: 0.013922 [212]: 0.009644 ======== top5 inference results: ============= [267]: 0.728299 [266]: 0.101693 [265]: 0.100117 [151]: 0.004214 [160]: 0.002721
类别标签和类别的对应关系与训练模型时使用的数据集有关,本样例使用的模型是基于imagenet数据集进行训练的,您可以在互联网上查阅对应数据集的标签及类别的对应关系。
当前屏显信息中的类别标识与类别的对应关系如下:
"161": ["basset", "basset hound"]
"162": ["beagle"]
"163": ["bloodhound", "sleuthhound"]
"166": ["Walker hound", "Walker foxhound"]
"167": ["English foxhound"]