模型结构
YOLOv3
- 可接受的模型与YOLOv3具有类似的输出张量。一般有三个输出张量(YOLOv3-Tiny只有两个,配置参数“YOLO_TYPE”需设为“2”),分别是8倍,16倍与32倍降采样后的特征层。
- 每个输出张量的第一维与模型所支持的最大batchsize相同,按照NHWC或NCHW,输出张量形状略有差异,W与H分别等于模型输入宽高除以8,16,32,C等于先验框个数anchorDim=3 * (边框坐标4 + 边框置信度1 + 类别数80) 。
- 配置参数MODEL_TYPE = 0时,采取NHWC,MODEL_TYPE = 1时,采取NCHW。

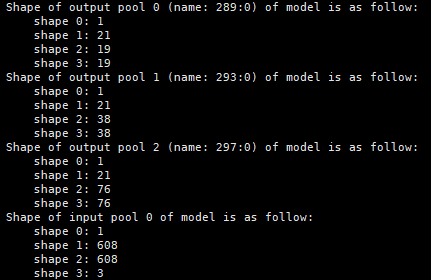
FasterRCNN
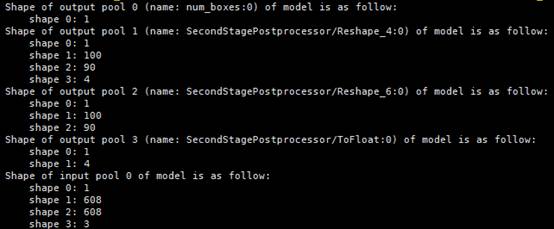
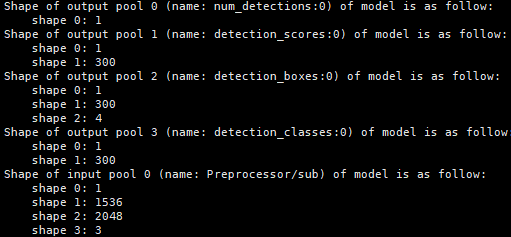
- 支持两种结构的模型,原生FasterRCNN模型,以及对模型中NMS(非最大值抑制)进行裁剪后的模型。
- 配置参数NMS_FINISHED = 0时,采取后者,NMS_FINISHED = 1时采取前者。
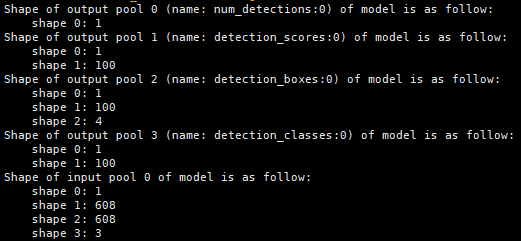
SSD MobileNet v1 FPN
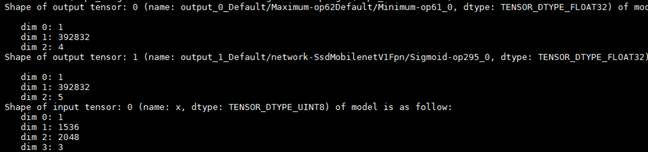
SSD MobileNet v1 FPN与FasterRCNN原生模型类似,有四个输出张量,分别为目标数,置信度,坐标框和类别ID。
SSD-VGG16
SSD-VGG16有两个输出张量,第一个输出张量是目标数,第二个输出张量的为目标框的信息[batch, keep_top_k, 8],其中的“8”表示batchID、label(classID)、score(类别概率)、xmin、ymin、xmax、ymax、null。

CRNN
CRNN的输出张量仅一个,第一维是batchsize,第二维即其所能检测的目标数上限,代表其识别到的每个目标的类别ID(包含占位符)。

ResNet-50
ResNet-50仅需一个输出张量,第一维是batchsize,第二维与类别数一致,为模型特征层softmax之后的结果。第二个输出张量为概率最大的类别对应的类别ID。

YOLOv4
YOLOv4与YOLOv3模型类似,有三个输出张量,分别是8倍,16倍与32倍降采样后的特征层。
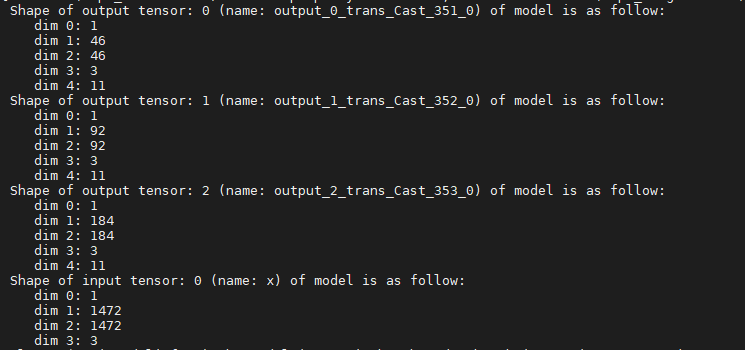
YOLOv5
- YOLOv5有三个输出张量,分别是8倍,16倍与32倍降采样后的特征层。
- 输出张量按照N(C0)HW(C1)的形式排布,W与H分别等于模型输入宽高除以8、16、32,C等于先验框个数anchorDim=3 * (边框坐标4 + 边框置信度1 + 类别数80) 。
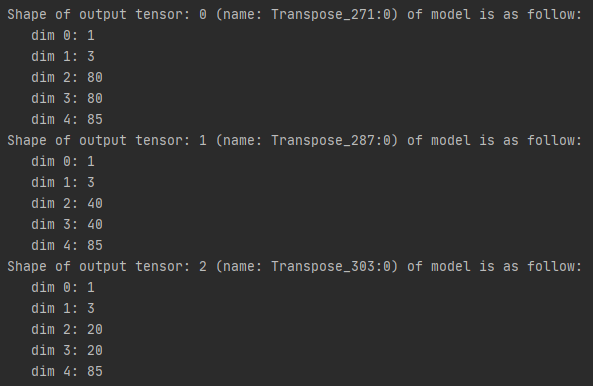
FasterRCNN-Fpn/CascadeRCNN-Fpn
模型有两个输出张量,分别是5 * 100的预测框和置信度(x0, y0, x1, y1,confidence)(其中坐标为左上和右下的检测框的坐标),1 * 100是每个类别的分值。输入为固定size的RGB图片:3 * 1216 * 1216 。
CTPN(TensorFlow)
CTPN(TensorFlow)模型有两个输出张量,分别是38 * 67 * 40的预测小框,相当于38 * 67 * 4的每个像素点生成10个小框,38 * 67 * 20的预测分数,相当于38 * 67 * 2的每个像素点生成10个预测分数。输入为固定size的RGB图片:3 * 608 * 1072 。
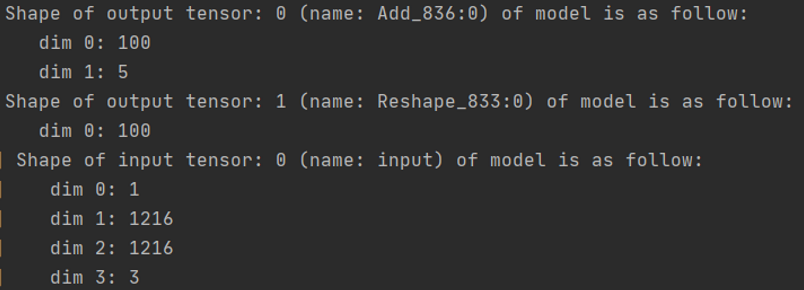
CTPN(MindSpore)
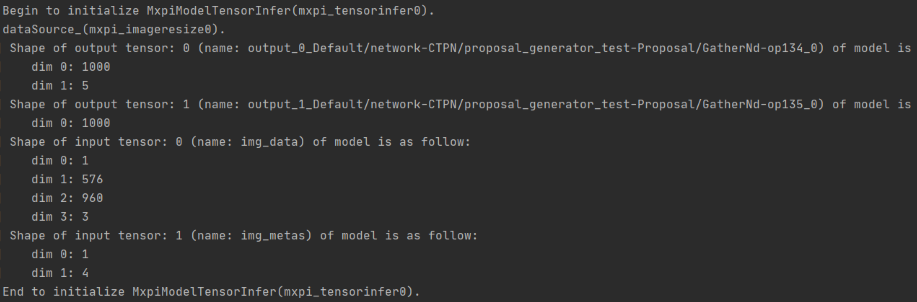
CTPN(MindSpore)模型有两个输出张量,分别是1000个预测小框,5个维度分别是四个坐标和分数, 另一个1000是每个小框的类别,分别为1、0,表示前景还是后景。输入则是固定size的RGB图片:3 * 576 * 960 。
ResNet-18+
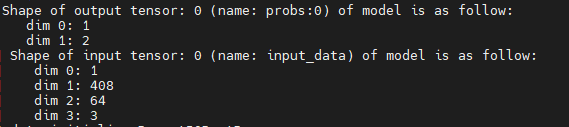
ResNet-18+模型输入是1 * 408 * 64 * 3大小的张量。输出是1 * 2的张量,表示每个样本的分类概率。
BERT-Base(Uncased)
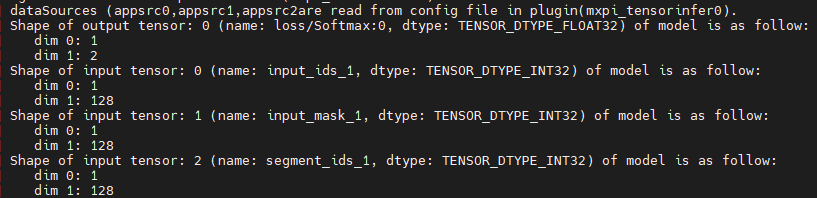
BERT-Base(Uncased)模型输入有三个张量,shape都是1 * 128。1表示batchsize,128表示句长。
模型输出有一个张量,1 * 2,表示每个分类类别的概率。
DeeplabV3+(TensorFlow)
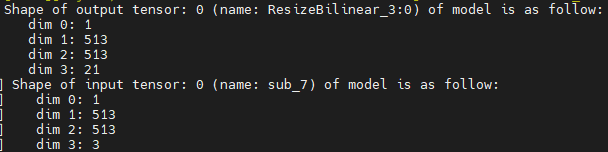
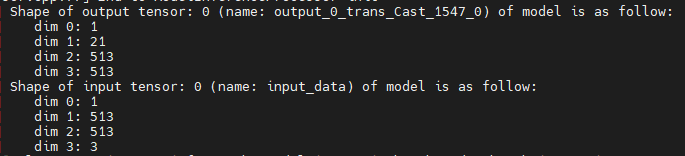
DeeplabV3+(TensorFlow)模型输出有一个张量,是1 * 513 * 513 * 21的NHWC排布方式,物理含义相当于每个像素点的分类概率。原始输入图片是动态shape的RGB图片。模型输入是1 * 513 * 513 * 3的张量。
DeepLabV3(MindSpore)
DeepLabV3(MindSpore)模型输入是NHWC排布的,输出以NCHW排布。
DeepLabV3(Pytorch)
DeepLabV3(Pytorch)模型输入以NHWC排布,输出为NCHW排布。
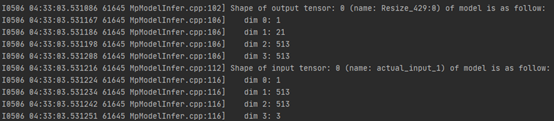
Unet(MindSpore)
Unet(MindSpore)模型输出Tensor为NCHW,其中N为1,C为2,作为mxVision后处理输入。
- 在C通道上进行argmax,得到最大概率值的索引值,生成数值为0和1的二维数组。
- 判断模型输出Tensor的HW是否与输入原图尺寸一致,若一致则直接输出argmax后的二维数组,否则进行最近邻插值到输入图片尺寸。

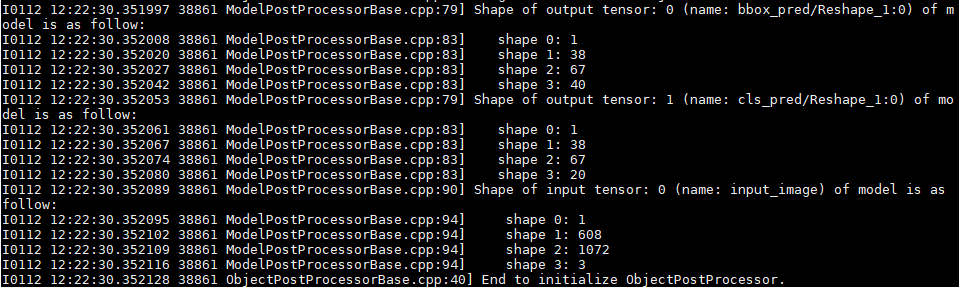
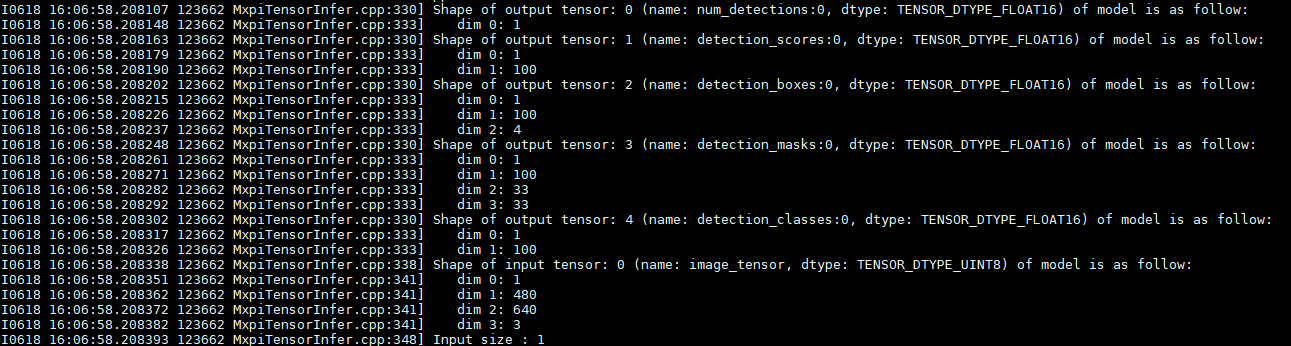
Mask R-CNN(TensorFlow)
Mask R-CNN(TensorFlow)模型输入张量为4维NHWC(1 * 480 * 640 * 3)排布格式。
- N为批数量。
- H为输入图像的高度(480)。
- W为输入图像的宽度(640)。
Mask R-CNN(TensorFlow)模型输出张量有5个(tensor[0]~tensor[4])。
- tensor[0]的维度为1维(1),第一维长度为1,代表模型检测出的目标的个数。
- tensor[1]的维度为2维(1 * 100),第一维长度为1,代表批数量。第二维长度为100,代表前top100个目标的置信度分数。
- tensor[2]的维度为3维为(1 * 100 * 4), 第一维长度为1,代表批数量。第二维长度为100,代表前top100个目标框。第三维长度为4,代表目标框的四个顶点坐标(x0, y0, x1, y1)。
- tensor[3]的维度为4维(1 * 100 * 33 * 33),第一维长度为1,代表批数量。第二维长度为100,代表前top100个目标框。第三维和第四维代表一张33 * 33大小的掩码图。
- tensor[4]的维度为2维(1 * 100), 第一维长度为1,代表批数量。第二维长度为100,代表前top100目标的分类类别。
FaceNet(TensorFlow)
FaceNet(TensorFlow)输入张量的形状为 NHWC (1*160*160*3),数据类型为UINT8。
- N为批数量。
- H代表输入图像的高度160。
- W代表输入图像的宽度160。
- C代表图像的通道数。
输出张量为目标图像对应的特征向量,形状为1 * 512,第一维代表批数量,第二维为特征向量的长度512,数据类型为FLOAT32。

SSD MobileNet v1 FPN(MindSpore)
SSD MobileNet v1 FPN(MindSpore)有2个输出张量,分别为坐标框和置信度。
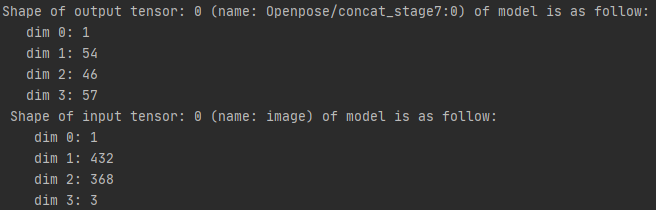
OpenPose
OpenPose输出张量为[batch, outputHeight, outputWidth, channel],“outputHeight”表示输出图像的高,“outputWidth”表示输出图像的宽,“channel”由两部分组成,前1/3为heat mat,后2/3为paf mat。此模型输出为[1, 54, 46, 57]。
Unet++(MindSpore)
Unet++(MindSpore)模型后处理有一个NCHW的输入Tensor,为模型进行argmax操作之后经过aipp处理后输入给后处理模块;有一个NHW的输出Tensor,由于模型已经做了argmax,C通道已经计算在Tensor HW对应的值。
