aclCompileOpt
typedef enum {
ACL_PRECISION_MODE, // 网络模型的算子精度模式
ACL_AICORE_NUM, // 模型编译时使用的AI Core数量
ACL_AUTO_TUNE_MODE, // 算子的自动调优模式
ACL_OP_SELECT_IMPL_MODE, // 选择算子是高精度实现还是高性能实现
ACL_OPTYPELIST_FOR_IMPLMODE, // 列举算子类型的列表,该列表中的算子使用ACL_OP_SELECT_IMPL_MODE指定的模式
ACL_OP_DEBUG_LEVEL, // TBE算子编译debug功能开关
ACL_DEBUG_DIR, // 保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径,包括算子.o/.json/.cce等文件。
ACL_OP_COMPILER_CACHE_MODE, // 算子编译磁盘缓存模式
ACL_OP_COMPILER_CACHE_DIR, // 算子编译磁盘缓存的目录
ACL_OP_PERFORMANCE_MODE, // 通过该选项设置是否按照算子执行高性能的方式编译算子
ACL_OP_JIT_COMPILE, // 选择是在线编译算子,还是使用已编译的算子二进制文件
ACL_OP_DETERMINISTIC, // 是否开启确定性计算
ACL_CUSTOMIZE_DTYPES, // 模型编译时自定义某个或某些算子的计算精度
ACL_OP_PRECISION_MODE, // 指定算子内部处理时的精度模式,支持指定一个算子或多个算子。
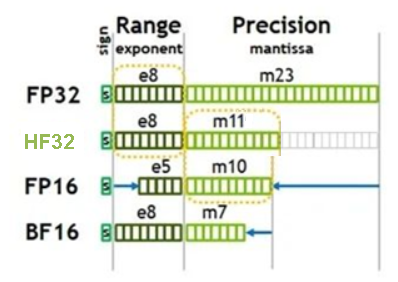
ACL_ALLOW_HF32, // hf32是昇腾推出的专门用于算子内部计算的精度类型,当前版本不支持
ACL_PRECISION_MODE_V2, // 网络模型的算子精度模式,相比ACL_PRECISION_MODE选项,ACL_PRECISION_MODE_V2是新版本中新增的,精度模式更多,同时原有精度模式选项值语义更清晰,便于理解
ACL_OP_DEBUG_OPTION // 当前仅支持配置为oom,表示开启Global Memory访问越界检测
} aclCompileOpt;
父主题: 数据类型及其操作接口