CastDeq
函数功能
当isVecDeq=false时,根据SetDeqScale设置的scale、offset、signMode,对int16_t类型的输入做量化并进行精度转换,得到int8_t/uint8_t类型的数据。当需要返回有符号数时,signMode = true;返回无符号数时,signMode = false。计算公式如下:

当isVecDeq=true时,根据SetDeqScale设置的一段128B的UB上的16组量化参数scale0-scale15、offset0-offset15、signMode0-signMode15,以循环的方式对int16_t类型的输入做量化并进行精度转换,得到int8_t/uint8_t类型的数据。当需要返回有符号数时,signMode = true;返回无符号数时,signMode = false。计算公式如下:
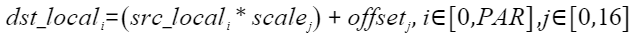
函数原型
- tensor前n个数据计算
1 2
template <typename T1, typename T2, bool isVecDeq = true, bool halfBlock = true> __aicore__ inline void CastDeq(const LocalTensor<T1>& dstLocal, const LocalTensor<T2>& srcLocal, const uint32_t calCount)
- tensor高维切分计算
- mask逐bit模式
1 2
template <typename T1, typename T2, bool isSetMask = true, bool isVecDeq = true, bool halfBlock = true> __aicore__ inline void CastDeq(const LocalTensor<T1>& dstLocal, const LocalTensor<T2>& srcLocal, const uint64_t mask[], uint8_t repeatTimes, const UnaryRepeatParams& repeatParams)
- mask连续模式
1 2
template <typename T1, typename T2, bool isSetMask = true, bool isVecDeq = true, bool halfBlock = true> __aicore__ inline void CastDeq(const LocalTensor<T1>& dstLocal, const LocalTensor<T2>& srcLocal, const int32_t mask, uint8_t repeatTimes, const UnaryRepeatParams& repeatParams)
- mask逐bit模式
参数说明

|
参数名 |
描述 |
|---|---|
|
halfBlock |
用于指示输出元素存放在上半还是下半Block。halfBlock=true时,结果存放在下半Block;halfBlock=false时,结果存放在上半Block,如图图1。 |
|
T1 |
输出Tensor的数据类型,支持int8_t/uint8_t。 和SetDeqScale接口的signMode入参配合使用,当signMode=true时输出数据类型int8_t;signMode=false时输出数据类型uint8_t。 |
|
T2 |
输入Tensor的数据类型,支持int16_t。 |
|
isVecDeq |
和SetDeqScale(const LocalTensor<T>& src)接口配合使用,当SetDeqScale接口传入Tensor时,isVecDeq必须为true。 |
|
isSetMask |
是否在接口内部设置mask。
|
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 LocalTensor的起始地址需要32字节对齐。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int8_t/uint8_t Atlas推理系列产品AI Core,支持的数据类型为:int8_t/uint8_t |
|
srcLocal |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 LocalTensor的起始地址需要32字节对齐。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int16_t Atlas推理系列产品AI Core,支持的数据类型为:int16_t |
|
mask |
输入 |
当源操作数和目的操作数位数不同时,以数据类型的字节较大的为准。例如,源操作数为half类型,目的操作数为int32_t类型,计算mask时以int32_t为准。 |
|
repeatTimes |
输入 |
重复迭代次数。矢量计算单元,每次读取连续的256 Bytes数据进行计算,为完成对输入数据的处理,必须通过多次迭代(repeat)才能完成所有数据的读取与计算。repeatTimes表示迭代的次数。 |
|
repeatParams |
输入 |
控制操作数地址步长的参数。UnaryRepeatParams类型,包含操作数相邻迭代间相同datablock的地址步长,操作数同一迭代内不同datablock的地址步长等参数。 相邻迭代间的地址步长参数说明请参考repeatStride(相邻迭代间相同datablock的地址步长);同一迭代内datablock的地址步长参数说明请参考dataBlockStride(同一迭代内不同datablock的地址步长)。 |
|
calCount |
输入 |
输入数据元素个数。 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
注意事项
- 操作数地址偏移对齐要求请参见通用约束。
- repeatTimes∈[0,255]。
- 每个repeat的并行度取决于数据精度、AI处理器型号,如s16->s8/u8转换每次迭代操作128个源/目的元素。
- 为了节省地址空间,开发者可以定义一个Tensor,供源操作数与目的操作数同时使用(即地址重叠),相关约束如下 :
- 对于单次repeat(repeatTimes=1),且源操作数与目的操作数之间要求100%完全重叠,不支持部分重叠。
- 对于多次repeat(repeatTimes>1),若源操作数与目的操作数之间存在依赖,即第N次迭代的目的操作数是第N+1次的源操作数,这种情况是不支持地址重叠的。
调用示例
如果您需要运行样例代码,请将该代码段拷贝并替换样例模板中Compute函数的部分代码即可。
- 高维切分计算接口样例-mask连续模式
1 2 3 4 5
uint64_t mask = 256 / sizeof(int16_t); // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride, srcBlkStride = 1, no gap between blocks in one repeat // dstRepStride, srcRepStride = 8, no gap between repeats AscendC::CastDeq<uint8_t, int16_t, true, true, true>(dstLocal, srcLocal, mask, 2, { 1, 1, 8, 8 });
- 高维切分计算接口样例-mask逐bit模式
1 2 3 4 5
uint64_t mask[2] = { UINT64_MAX, UINT64_MAX }; // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride, srcBlkStride = 1, no gap between blocks in one repeat // dstRepStride, srcRepStride = 8, no gap between repeats AscendC::CastDeq<uint8_t, int16_t, true, true, true>(dstLocal, srcLocal, mask, 8, { 1, 1, 8, 8 });
- 前n个数计算接口样例
1AscendC::CastDeq<uint8_t, int16_t, true, true>(dstLocal, srcLocal, 256);
结果示例如下:
输入数据(srcLocal): [20 53 26 12 36 6 20 93 66 30 56 99 59 92 7 37 22 47 98 10 85 29 14 46 17 34 45 17 25 45 82 17 66 94 68 23 67 8 89 8 92 6 10 80 87 20 9 81 70 62 11 58 38 83 32 14 38 47 41 63 94 26 96 89 88 35 86 55 60 82 15 65 92 67 83 23 63 25 85 93 50 91 75 60 80 10 55 20 71 14 67 23 31 63 7 93 69 45 61 23 43 86 11 81 81 36 76 58 53 25 23 51 59 78 82 10 39 40 24 50 68 49 79 40 4 53 22 38 45 17 29 54 9 66 98 47 12 47 47 20 98 0 59 77 1 21 39 70 66 20 68 8 77 77 54 0 3 33 37 37 48 60 83 88 27 70 31 49 75 21 59 3 99 84 92 84 14 44 26 56 72 56 37 52 39 11 2 59 59 65 71 64 10 65 62 48 42 79 69 69 27 99 8 38 36 77 34 34 60 50 52 50 41 31 95 68 27 16 42 64 19 47 0 10 36 36 33 62 98 64 32 81 49 53 27 70 35 9 63 7 10 89 3 39 94 23 89 16 23 60 71 42 46 58 65 90] 输出数据(dstLocal): [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 20 53 26 12 36 6 20 93 66 30 56 99 59 92 7 37 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 22 47 98 10 85 29 14 46 17 34 45 17 25 45 82 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 66 94 68 23 67 8 89 8 92 6 10 80 87 20 9 81 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 70 62 11 58 38 83 32 14 38 47 41 63 94 26 96 89 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 88 35 86 55 60 82 15 65 92 67 83 23 63 25 85 93 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 50 91 75 60 80 10 55 20 71 14 67 23 31 63 7 93 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 69 45 61 23 43 86 11 81 81 36 76 58 53 25 23 51 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 78 82 10 39 40 24 50 68 49 79 40 4 53 22 38 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 17 29 54 9 66 98 47 12 47 47 20 98 0 59 77 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 21 39 70 66 20 68 8 77 77 54 0 3 33 37 37 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 48 60 83 88 27 70 31 49 75 21 59 3 99 84 92 84 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 44 26 56 72 56 37 52 39 11 2 59 59 65 71 64 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 65 62 48 42 79 69 69 27 99 8 38 36 77 34 34 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 60 50 52 50 41 31 95 68 27 16 42 64 19 47 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 36 36 33 62 98 64 32 81 49 53 27 70 35 9 63 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 89 3 39 94 23 89 16 23 60 71 42 46 58 65 90]
样例模板
为了方便您快速运行指令中的参考样例,本章节提供样例模板。
#include "kernel_operator.h"
template <typename srcType, typename dstType>
class KernelCastDeq {
public:
__aicore__ inline KernelCastDeq() {}
__aicore__ inline void Init(GM_ADDR src_gm, GM_ADDR dst_gm, uint32_t inputSize, bool halfBlock, bool isVecDeq)
{
srcSize = inputSize;
dstSize = inputSize * 2;
this->halfBlock = halfBlock;
this->isVecDeq = isVecDeq;
src_global.SetGlobalBuffer(reinterpret_cast<__gm__ srcType*>(src_gm), srcSize);
dst_global.SetGlobalBuffer(reinterpret_cast<__gm__ dstType*>(dst_gm), dstSize);
pipe.InitBuffer(inQueueX, 1, srcSize * sizeof(srcType));
pipe.InitBuffer(outQueue, 1, dstSize * sizeof(dstType));
pipe.InitBuffer(tmpQueue, 1, 128);
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
AscendC::LocalTensor<srcType> srcLocal = inQueueX.AllocTensor<srcType>();
AscendC::DataCopy(srcLocal, src_global, srcSize);
inQueueX.EnQue(srcLocal);
}
__aicore__ inline void Compute()
{
AscendC::LocalTensor<dstType> dstLocal = outQueue.AllocTensor<dstType>();
AscendC::LocalTensor<uint64_t> tmpBuffer = tmpQueue.AllocTensor<uint64_t>();
AscendC::Duplicate(tmpBuffer.ReinterpretCast<int32_t>(), static_cast<int32_t>(0), 32);
AscendC::PipeBarrier<PIPE_V>();
AscendC::Duplicate<int32_t>(dstLocal.template ReinterpretCast<int32_t>(), static_cast<int32_t>(0), dstSize / sizeof(int32_t));
AscendC::PipeBarrier<PIPE_ALL>();
bool signMode = false;
if constexpr (AscendC::IsSameType<dstType, int8_t>::value) {
signMode = true;
}
AscendC::LocalTensor<srcType> srcLocal = inQueueX.DeQue<srcType>();
if (halfBlock) {
if (isVecDeq) {
float vdeqScale[16] = { 1.0 };
int16_t vdeqOffset[16] = { 0 };
bool vdeqSignMode[16] = { signMode };
AscendC::VdeqInfo vdeqInfo(vdeqScale, vdeqOffset, vdeqSignMode);
AscendC::SetDeqScale(tmpBuffer, vdeqInfo);
AscendC::CastDeq<dstType, srcType, true, true>(dstLocal, srcLocal, srcSize);
} else {
float scale = 1.0;
int16_t offset = 0;
AscendC::SetDeqScale(scale, offset, signMode);
AscendC::CastDeq<dstType, srcType, false, true>(dstLocal, srcLocal, srcSize);
}
} else {
if (isVecDeq) {
float vdeqScale[16] = { 1.0 };
int16_t vdeqOffset[16] = { 0 };
bool vdeqSignMode[16] = { signMode };
AscendC::VdeqInfo vdeqInfo(vdeqScale, vdeqOffset, vdeqSignMode);
AscendC::SetDeqScale(tmpBuffer, vdeqInfo);
AscendC::CastDeq<dstType, srcType, true, false>(dstLocal, srcLocal, srcSize);
} else {
float scale = 1.0;
int16_t offset = 0;
AscendC::SetDeqScale(scale, offset, signMode);
AscendC::CastDeq<dstType, srcType, false, false>(dstLocal, srcLocal, srcSize);
}
}
outQueue.EnQue<dstType>(dstLocal);
tmpQueue.FreeTensor(tmpBuffer);
inQueueX.FreeTensor(srcLocal);
}
__aicore__ inline void CopyOut()
{
AscendC::LocalTensor<dstType> dstLocal = outQueue.DeQue<dstType>();
AscendC::DataCopy(dst_global, dstLocal, dstSize);
outQueue.FreeTensor(dstLocal);
}
private:
AscendC::GlobalTensor<srcType> src_global;
AscendC::GlobalTensor<dstType> dst_global;
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> tmpQueue;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue;
bool halfBlock = false;
bool isVecDeq = false;
uint32_t srcSize = 0;
uint32_t dstSize = 0;
};
template <typename srcType, typename dstType>
__aicore__ void kernel_cast_deqscale_operator(GM_ADDR src_gm, GM_ADDR dst_gm, uint32_t dataSize, bool halfBlock, bool isVecDeq)
{
KernelCastDeq<srcType, dstType> op;
op.Init(src_gm, dst_gm, dataSize, halfBlock, isVecDeq);
op.Process();
}