Tanh
功能说明
按元素做逻辑回归Tanh,计算公式如下,其中PAR表示矢量计算单元一个迭代能够处理的元素个数 :

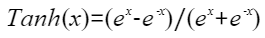
函数原型
- 通过sharedTmpBuffer入参传入临时空间
- 源操作数Tensor全部/部分参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Tanh(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor, const LocalTensor<uint8_t>& sharedTmpBuffer, const uint32_t calCount)
- 源操作数Tensor全部参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Tanh(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor, const LocalTensor<uint8_t>& sharedTmpBuffer)
- 源操作数Tensor全部/部分参与计算
- 接口框架申请临时空间
- 源操作数Tensor全部/部分参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Tanh(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor, const uint32_t calCount)
- 源操作数Tensor全部参与计算
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void Tanh(const LocalTensor<T>& dstTensor, const LocalTensor<T>& srcTensor)
- 源操作数Tensor全部/部分参与计算
参数说明
参数名 |
描述 |
|---|---|
T |
操作数的数据类型。 |
isReuseSource |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstTensor |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
srcTensor |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 源操作数的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
sharedTmpBuffer |
输入 |
临时缓存。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 用于Tanh内部复杂计算时存储中间变量,由开发者提供。 临时空间大小BufferSize的获取方式请参考GetTanhMaxMinTmpSize。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t Atlas推理系列产品AI Core,支持的数据类型为: uint8_t |
calCount |
输入 |
实际计算数据元素个数,且calCount∈[0, srcTensor.GetSize()] |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
约束说明
- 不支持源操作数与目的操作数地址重叠。
- 不支持sharedTmpBuffer与源操作数和目的操作数地址重叠。
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
AscendC::TPipe pipe; AscendC::TQue<AscendC::TPosition::VECCALC, 1> tmpQue; pipe.InitBuffer(tmpQue, 1, bufferSize); // bufferSize 通过Host侧tiling参数获取 AscendC::LocalTensor<uint8_t> sharedTmpBuffer = tmpQue.AllocTensor<uint8_t>(); // 输入shape信息为1024, 算子输入的数据类型为half,实际计算个数为512 AscendC::Tanh(dstLocal, srcLocal, sharedTmpBuffer, 512);
输入数据(srcLocal): [1.762616 7.9542747 ... 7.8306146 6.3167496] 输出数据(dstLocal): [0.9427944 0.9999998 ... 0.9999996 0.9999934]