MrgSort
函数功能
将已经排好序的最多4条队列,合并排列成1条队列,结果按照score域由大到小排序,排布方式如下:
Atlas A2训练系列产品/Atlas 800I A2推理产品采用方式一
Atlas推理系列产品AI Core采用方式二
- 排布方式一:
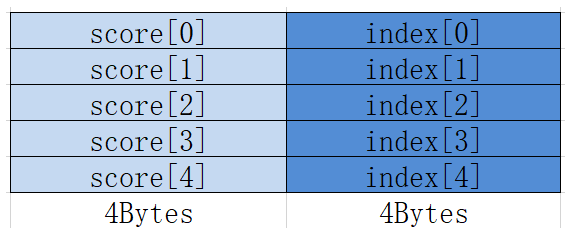
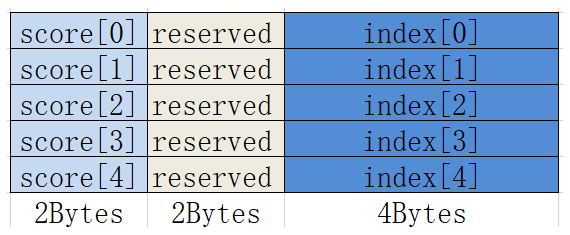
- 排布方式二:Region Proposal排布
输入输出数据均为Region Proposal,具体请参见Sort中的排布方式二。
函数原型
1 2 |
template <typename T, bool isExhaustedSuspension = false> __aicore__ inline void MrgSort(const LocalTensor<T> &dstLocal, const MrgSortSrcList<T> &sortList, const uint16_t elementCountList[4], uint32_t sortedNum[4], uint16_t validBit, const int32_t repeatTimes) |
参数说明
|
接口 |
功能 |
|---|---|
|
T |
操作数的数据类型。 |
|
isExhaustedSuspension |
某条队列耗尽(即该队列已经全部排序到目的操作数)后,是否需要停止合并。类型为bool,参数取值如下:
默认值为false。 |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dstLocal |
输出 |
目的操作数,存储经过排序后的数据。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
sortList |
输入 |
源操作数,支持2-4个队列,并且每个队列都已经排好序,类型为MrgSortSrcList结构体,具体请参考表3。MrgSortSrcList中传入要合并的队列。 template <typename T>
struct MrgSortSrcList {
LocalTensor<T> src1;
LocalTensor<T> src2;
LocalTensor<T> src3; // 当要合并的队列个数小于3,可以为空tensor
LocalTensor<T> src4; // 当要合并的队列个数小于4,可以为空tensor
};
Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
elementCountList |
输入 |
四个源队列的长度(8Bytes结构的数目),类型为长度为4的uint16_t数据类型的数组,理论上每个元素取值范围[0, 4095],但不能超出UB的存储空间。 |
|
sortedNum |
输出 |
耗尽模式下(即isExhaustedSuspension为true时),停止合并时每个队列已排序的元素个数。 |
|
validBit |
输入 |
有效队列个数,取值如下:
|
|
repeatTimes |
输入 |
迭代次数,每一次源操作数和目的操作数跳过四个队列总长度。取值范围:repeatTimes∈[1,255]。
repeatTimes参数生效是有条件的,需要同时满足以下四个条件:
|
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
src1 |
输入 |
源操作数,第一个已经排好序的队列。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 数据类型与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
src2 |
输入 |
源操作数,第二个已经排好序的队列。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 数据类型与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
src3 |
输入 |
源操作数,第三个已经排好序的队列。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 数据类型与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
src4 |
输入 |
源操作数,第四个已经排好序的队列。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 数据类型与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
约束说明
- 当存在score[i]与score[j]相同时,如果i>j,则score[j]将首先被选出来,排在前面,即index的顺序与输入顺序一致。
- 每次迭代内的数据会进行排序,不同迭代间的数据不会进行排序。
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
- 处理128个half类型数据。
Atlas A2训练系列产品/Atlas 800I A2推理产品
#include "kernel_operator.h" template <typename T> class FullSort { public: __aicore__ inline FullSort() {} __aicore__ inline void Init(__gm__ uint8_t *srcValueGm, __gm__ uint8_t *srcIndexGm, __gm__ uint8_t *dstValueGm, __gm__ uint8_t *dstIndexGm) { concatRepeatTimes = elementCount / 16; inBufferSize = elementCount * sizeof(uint32_t); outBufferSize = elementCount * sizeof(uint32_t); calcBufferSize = elementCount * 8; tmpBufferSize = elementCount * 8; sortedLocalSize = elementCount * 4; sortRepeatTimes = elementCount / 32; extractRepeatTimes = elementCount / 32; sortTmpLocalSize = elementCount * 4; valueGlobal.SetGlobalBuffer((__gm__ T *)srcValueGm); indexGlobal.SetGlobalBuffer((__gm__ uint32_t *)srcIndexGm); dstValueGlobal.SetGlobalBuffer((__gm__ T *)dstValueGm); dstIndexGlobal.SetGlobalBuffer((__gm__ uint32_t *)dstIndexGm); pipe.InitBuffer(queIn, 2, inBufferSize); pipe.InitBuffer(queOut, 2, outBufferSize); pipe.InitBuffer(queCalc, 1, calcBufferSize * sizeof(T)); pipe.InitBuffer(queTmp, 2, tmpBufferSize * sizeof(T)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<T> valueLocal = queIn.AllocTensor<T>(); AscendC::DataCopy(valueLocal, valueGlobal, elementCount); queIn.EnQue(valueLocal); AscendC::LocalTensor<uint32_t> indexLocal = queIn.AllocTensor<uint32_t>(); AscendC::DataCopy(indexLocal, indexGlobal, elementCount); queIn.EnQue(indexLocal); } __aicore__ inline void Compute() { AscendC::LocalTensor<T> valueLocal = queIn.DeQue<T>(); AscendC::LocalTensor<uint32_t> indexLocal = queIn.DeQue<uint32_t>(); AscendC::LocalTensor<T> sortedLocal = queCalc.AllocTensor<T>(); AscendC::LocalTensor<T> concatTmpLocal = queTmp.AllocTensor<T>(); AscendC::LocalTensor<T> sortTmpLocal = queTmp.AllocTensor<T>(); AscendC::LocalTensor<T> dstValueLocal = queOut.AllocTensor<T>(); AscendC::LocalTensor<uint32_t> dstIndexLocal = queOut.AllocTensor<uint32_t>(); AscendC::LocalTensor<T> concatLocal; AscendC::Concat(concatLocal, valueLocal, concatTmpLocal, concatRepeatTimes); AscendC::Sort<T, false>(sortedLocal, concatLocal, indexLocal, sortTmpLocal, sortRepeatTimes); uint32_t singleMergeTmpElementCount = elementCount / 4; uint32_t baseOffset = AscendC::GetSortOffset<T>(singleMergeTmpElementCount); AscendC::MrgSortSrcList sortList = AscendC::MrgSortSrcList(sortedLocal[0], sortedLocal[baseOffset], sortedLocal[2 * baseOffset], sortedLocal[3 * baseOffset]); uint16_t singleDataSize = elementCount / 4; const uint16_t elementCountList[4] = {singleDataSize, singleDataSize, singleDataSize, singleDataSize}; uint32_t sortedNum[4]; AscendC::MrgSort<T, false>(sortTmpLocal, sortList, elementCountList, sortedNum, 0b1111, 1); AscendC::Extract(dstValueLocal, dstIndexLocal, sortTmpLocal, extractRepeatTimes); queTmp.FreeTensor(concatTmpLocal); queTmp.FreeTensor(sortTmpLocal); queIn.FreeTensor(valueLocal); queIn.FreeTensor(indexLocal); queCalc.FreeTensor(sortedLocal); queOut.EnQue(dstValueLocal); queOut.EnQue(dstIndexLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<T> dstValueLocal = queOut.DeQue<T>(); AscendC::LocalTensor<uint32_t> dstIndexLocal = queOut.DeQue<uint32_t>(); AscendC::DataCopy(dstValueGlobal, dstValueLocal, elementCount); AscendC::DataCopy(dstIndexGlobal, dstIndexLocal, elementCount); queOut.FreeTensor(dstValueLocal); queOut.FreeTensor(dstIndexLocal); } private: AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 2> queIn; AscendC::TQue<AscendC::QuePosition::VECOUT, 2> queOut; AscendC::TQue<AscendC::QuePosition::VECIN, 2> queTmp; AscendC::TQue<AscendC::QuePosition::VECIN, 1> queCalc; AscendC::GlobalTensor<T> valueGlobal; AscendC::GlobalTensor<uint32_t> indexGlobal; AscendC::GlobalTensor<T> dstValueGlobal; AscendC::GlobalTensor<uint32_t> dstIndexGlobal; uint32_t elementCount = 128; uint32_t concatRepeatTimes; uint32_t inBufferSize; uint32_t outBufferSize; uint32_t calcBufferSize; uint32_t tmpBufferSize; uint32_t sortedLocalSize; uint32_t sortTmpLocalSize; uint32_t sortRepeatTimes; uint32_t extractRepeatTimes; }; extern "C" __global__ __aicore__ void sort_operator(__gm__ uint8_t *src0Gm, __gm__ uint8_t *src1Gm, __gm__ uint8_t *dst0Gm, __gm__ uint8_t *dst1Gm) { FullSort<half> op; op.Init(src0Gm, src1Gm, dst0Gm, dst1Gm); op.Process(); }示例结果 输入数据(srcValueGm): 128个float类型数据 [31 30 29 ... 2 1 0 63 62 61 ... 34 33 32 95 94 93 ... 66 65 64 127 126 125 ... 98 97 96] 输入数据(srcIndexGm): [31 30 29 ... 2 1 0 63 62 61 ... 34 33 32 95 94 93 ... 66 65 64 127 126 125 ... 98 97 96] 输出数据(dstValueGm): [127 126 125 ... 2 1 0] 输出数据(dstIndexGm): [127 126 125 ... 2 1 0]
- 处理64个half类型数据。
Atlas推理系列产品AI Core
#include "kernel_operator.h" template <typename T> class FullSort { public: __aicore__ inline FullSort() {} __aicore__ inline void Init(__gm__ uint8_t *srcValueGm, __gm__ uint8_t *srcIndexGm, __gm__ uint8_t *dstValueGm, __gm__ uint8_t *dstIndexGm) { concatRepeatTimes = elementCount / 16; inBufferSize = elementCount * sizeof(uint32_t); outBufferSize = elementCount * sizeof(uint32_t); calcBufferSize = elementCount * 8; tmpBufferSize = elementCount * 8; sortedLocalSize = elementCount * 8 * sizeof(T); sortRepeatTimes = elementCount / 16; extractRepeatTimes = elementCount / 16; sortTmpLocalSize = elementCount * 8 * sizeof(T); valueGlobal.SetGlobalBuffer((__gm__ T *)srcValueGm); indexGlobal.SetGlobalBuffer((__gm__ uint32_t *)srcIndexGm); dstValueGlobal.SetGlobalBuffer((__gm__ T *)dstValueGm); dstIndexGlobal.SetGlobalBuffer((__gm__ uint32_t *)dstIndexGm); pipe.InitBuffer(queIn, 2, inBufferSize); pipe.InitBuffer(queOut, 2, outBufferSize); pipe.InitBuffer(queCalc, 1, calcBufferSize * sizeof(T)); pipe.InitBuffer(queTmp, 2, tmpBufferSize * sizeof(T)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<T> valueLocal = queIn.AllocTensor<T>(); AscendC::DataCopy(valueLocal, valueGlobal, elementCount); queIn.EnQue(valueLocal); AscendC::LocalTensor<uint32_t> indexLocal = queIn.AllocTensor<uint32_t>(); AscendC::DataCopy(indexLocal, indexGlobal, elementCount); queIn.EnQue(indexLocal); } __aicore__ inline void Compute() { AscendC::LocalTensor<T> valueLocal = queIn.DeQue<T>(); AscendC::LocalTensor<uint32_t> indexLocal = queIn.DeQue<uint32_t>(); AscendC::LocalTensor<T> sortedLocal = queCalc.AllocTensor<T>(); AscendC::LocalTensor<T> concatTmpLocal = queTmp.AllocTensor<T>(); AscendC::LocalTensor<T> sortTmpLocal = queTmp.AllocTensor<T>(); AscendC::LocalTensor<T> dstValueLocal = queOut.AllocTensor<T>(); AscendC::LocalTensor<uint32_t> dstIndexLocal = queOut.AllocTensor<uint32_t>(); AscendC::LocalTensor<T> concatLocal; AscendC::Concat(concatLocal, valueLocal, concatTmpLocal, concatRepeatTimes); AscendC::Sort<T, false>(sortedLocal, concatLocal, indexLocal, sortTmpLocal, sortRepeatTimes); uint32_t singleMergeTmpElementCount = elementCount / 4; uint32_t baseOffset = AscendC::GetSortOffset<T>(singleMergeTmpElementCount); AscendC::MrgSortSrcList sortList = AscendC::MrgSortSrcList(sortedLocal[0], sortedLocal[baseOffset], sortedLocal[2 * baseOffset], sortedLocal[3 * baseOffset]); uint16_t singleDataSize = elementCount / 4; const uint16_t elementCountList[4] = {singleDataSize, singleDataSize, singleDataSize, singleDataSize}; uint32_t sortedNum[4]; AscendC::MrgSort<T, false>(sortTmpLocal, sortList, elementCountList, sortedNum, 0b1111, 1); AscendC::Extract(dstValueLocal, dstIndexLocal, sortTmpLocal, extractRepeatTimes); queTmp.FreeTensor(concatTmpLocal); queTmp.FreeTensor(sortTmpLocal); queIn.FreeTensor(valueLocal); queIn.FreeTensor(indexLocal); queCalc.FreeTensor(sortedLocal); queOut.EnQue(dstValueLocal); queOut.EnQue(dstIndexLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<T> dstValueLocal = queOut.DeQue<T>(); AscendC::LocalTensor<uint32_t> dstIndexLocal = queOut.DeQue<uint32_t>(); AscendC::DataCopy(dstValueGlobal, dstValueLocal, elementCount); AscendC::DataCopy(dstIndexGlobal, dstIndexLocal, elementCount); queOut.FreeTensor(dstValueLocal); queOut.FreeTensor(dstIndexLocal); } private: AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 2> queIn; AscendC::TQue<AscendC::QuePosition::VECOUT, 2> queOut; AscendC::TQue<AscendC::QuePosition::VECIN, 2> queTmp; AscendC::TQue<AscendC::QuePosition::VECIN, 1> queCalc; AscendC::GlobalTensor<T> valueGlobal; AscendC::GlobalTensor<uint32_t> indexGlobal; AscendC::GlobalTensor<T> dstValueGlobal; AscendC::GlobalTensor<uint32_t> dstIndexGlobal; uint32_t elementCount = 64; uint32_t concatRepeatTimes; uint32_t inBufferSize; uint32_t outBufferSize; uint32_t calcBufferSize; uint32_t tmpBufferSize; uint32_t sortedLocalSize; uint32_t sortTmpLocalSize; uint32_t sortRepeatTimes; uint32_t extractRepeatTimes; }; extern "C" __global__ __aicore__ void sort_operator(__gm__ uint8_t *src0Gm, __gm__ uint8_t *src1Gm, __gm__ uint8_t *dst0Gm, __gm__ uint8_t *dst1Gm) { FullSort<half> op; op.Init(src0Gm, src1Gm, dst0Gm, dst1Gm); op.Process(); }示例结果 输入数据(srcValueGm): 128个float类型数据 [15 14 13 ... 2 1 0 31 30 29 ... 18 17 16 47 46 45 ... 34 33 32 63 62 61 ... 50 49 48] 输入数据(srcIndexGm): [15 14 13 ... 2 1 0 31 30 29 ... 18 17 16 47 46 45 ... 34 33 32 63 62 61 ... 50 49 48] 输出数据(dstValueGm): [63 62 61 ... 2 1 0] 输出数据(dstIndexGm): [63 62 61 ... 2 1 0]