Pybind调用
Pybind调用介绍
通过PyTorch框架进行模型的训练、推理时,会调用很多算子进行计算,其中的调用方式与kernel编译流程有关。对于自定义算子工程,需要使用PyTorch Ascend Adapter中的OP-Plugin算子插件对功能进行扩展,让torch可以直接调用自定义算子包中的算子,详细内容可以参考PyTorch框架;对于KernelLaunch开放式算子编程的方式,通过适配Pybind调用,可以实现PyTorch框架调用算子kernel程序。
Pybind是一个用于将C++代码与Python解释器集成的库,实现原理是通过将C++代码编译成动态链接库(DLL)或共享对象(SO)文件,使用Pybind提供的API将算子核函数与Python解释器进行绑定。在Python解释器中使用绑定的C++函数、类和变量,从而实现Python与C++代码的交互。在Kernel直调中使用时,就是将Pybind模块与算子核函数进行绑定,将其封装成Python模块,从而实现两者交互。
Pybind调用方式中,使用的主要接口有:
- c10_npu::getCurrentNPUStream:获取当前npu流,返回值类型NPUStream,使用方式请参考LINK。
- ACLRT_LAUNCH_KERNEL:同Kernel Launch方式中ACLRT_LAUNCH_KERNEL接口。
算子样例工程请通过如下链接获取:
环境准备
基于环境准备,还需要安装以下依赖:
- 安装pytorch (这里以2.1.0版本为例)
// aarch64环境上安装 pip3 install torch==2.1.0
// x86环境上安装 pip3 install torch==2.1.0+cpu --index-url https://download.pytorch.org/whl/cpu
- 安装torch-npu (以Pytorch2.1.0、python3.9、CANN版本8.0.RC1.alpha002为例)
git clone https://gitee.com/ascend/pytorch.git -b v6.0.rc1.alpha002-pytorch2.1.0 cd pytorch/ bash ci/build.sh --python=3.9 pip3 install dist/*.whl
- 安装pybind11
pip3 install pybind11
工程目录
您可以单击矢量算子样例,获取核函数开发和运行验证的完整样例。样例目录结构如下所示:
├── CppExtensions │ ├── add_custom_test.py // Python调用脚本 │ ├── add_custom.cpp // 算子实现 │ ├── CMakeLists.txt // 编译工程文件 │ ├── pybind11.cpp // pybind11函数封装 │ └── run.sh // 编译运行算子的脚本
基于该算子工程,开发者进行算子开发的步骤如下:
- 完成算子kernel侧实现。
- 编写算子调用应用程序和定义pybind模块pybind11.cpp。
- 编写Python调用脚本add_custom_test.py,包括生成输入数据和真值数据,调用封装的模块以及验证结果。
- 根据实际需要修改编译运行算子的脚本run.sh并执行该脚本,完成算子的编译运行和结果验证。
算子kernel侧实现
请参考矢量编程和工程目录中的算子kernel实现完成Ascend C算子实现文件的编写。
算子调用应用程序和定义pybind模块
下面代码以add_custom算子为例,介绍算子核函数调用的应用程序pybind11.cpp如何编写。您在实现自己的应用程序时,需要关注由于算子核函数不同带来的修改,包括算子核函数名,入参出参的不同等,相关API的调用方式直接复用即可。
- 按需包含头文件。需要注意的是,需要包含对应的核函数调用接口声明所在的头文件alcrtlaunch_{kernel_name}.h(该头文件为工程框架自动生成),kernel_name为算子核函数的名称。
#include <pybind11/pybind11.h> #include <torch/extension.h> #include "aclrtlaunch_add_custom.h" #include "torch_npu/csrc/core/npu/NPUStream.h"
- 应用程序框架编写。需要注意的是,本样例的输入x,y的内存是在Python调用脚本add_custom_test.py中分配的。
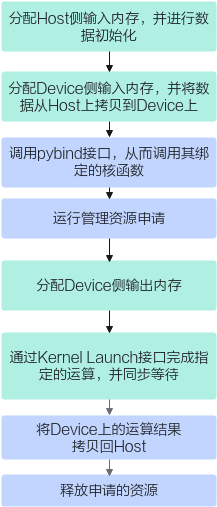
namespace my_add { at::Tensor run_add_custom(const at::Tensor &x, const at::Tensor &y) { } } - NPU侧运行验证。使用ACLRT_LAUNCH_KERNEL接口调用算子核函数完成指定的运算。
// 运行资源申请,通过c10_npu::getCurrentNPUStream()的函数获取当前NPU上的流 auto acl_stream = c10_npu::getCurrentNPUStream().stream(false); // 分配Device侧输出内存 at::Tensor z = at::empty_like(x); uint32_t blockDim = 8; uint32_t totalLength = 1; for (uint32_t size : x.sizes()) { totalLength *= size; } // 用ACLRT_LAUNCH_KERNEL接口调用核函数完成指定的运算 ACLRT_LAUNCH_KERNEL(add_custom)(blockDim, acl_stream, const_cast<void *>(x.storage().data()), const_cast<void *>(y.storage().data()), const_cast<void *>(z.storage().data()), totalLength); // 将Device上的运算结果拷贝回Host并释放申请的资源 return z;
- 定义Pybind模块,将C++函数封装成Python函数。PYBIND11_MODULE是Pybind11库中的一个宏,用于定义一个Python模块。它接受两个参数,第一个参数是封装后的模块名,第二个参数是一个Pybind11模块对象,用于定义模块中的函数、类、常量等。通过调用m.def()方法,可以将步骤2中函数my_add::run_add_custom()转成Python函数run_add_custom,使其可以在Python代码中被调用。
PYBIND11_MODULE(add_custom, m) { // 模块名add_custom,模块对象m m.doc() = "add_custom pybind11 interfaces"; // optional module docstring m.def("run_add_custom", &my_add::run_add_custom, ""); // 将函数run_add_custom与Pybind模块进行绑定 }
Python调用脚本
import torch
import torch_npu
from torch_npu.testing.testcase import TestCase, run_tests
import sys, os
sys.path.append(os.getcwd())
import add_custom
torch.npu.config.allow_internal_format = False
class TestCustomAdd(TestCase):
def test_add_custom_ops(self):
// 分配Host侧输入内存,并进行数据初始化
length = [8, 2048]
x = torch.rand(length, device='cpu', dtype=torch.float16)
y = torch.rand(length, device='cpu', dtype=torch.float16)
// 分配Device侧输入内存,并将数据从Host上拷贝到Device上
x_npu = x.npu()
y_npu = y.npu()
output = add_custom.run_add_custom(x_npu, y_npu)
cpuout = torch.add(x, y)
self.assertRtolEqual(output, cpuout)
if __name__ == "__main__":
run_tests()
CMake编译配置文件编写
通常情况下不需要开发者修改编译配置文件,但是了解编译配置文件可以帮助开发者更好的理解编译原理,方便有能力的开发者对Cmake进行定制化处理,具体内容请参考CMake编译配置文件编写。
修改并执行一键式编译运行脚本
您可以基于样例工程中提供的一键式编译运行脚本run.sh进行快速编译,在NPU侧执行Ascend C算子。一键式编译运行脚本主要完成以下功能:
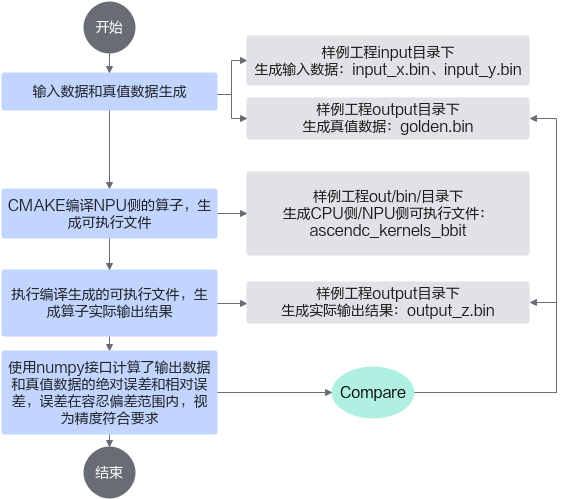

样例中提供的一键式编译运行脚本并不能适用于所有的算子运行验证场景,使用时请根据实际情况进行修改。
- 根据Ascend C算子的算法原理的不同,自行实现输入和真值数据的生成。
完成上述文件的编写后,可以执行一键式编译运行脚本,编译和运行应用程序。
bash run.sh --soc-version=<soc_version> bash run.sh -v <soc_version>
参数名 |
参数简写 |
参数介绍 |
|---|---|---|
--soc-version |
-v |
算子运行的AI处理器型号。
说明:
本样例支持如下产品型号:
AI处理器的型号请通过如下方式获取:
|