适配插件开发(TensorFlow框架)
简介
您可以参考本章节进行算子适配插件的开发,将第三方框架的算子映射成适配昇腾AI处理器的算子。基于TensorFlow 框架的网络运行时,首先会加载并调用Graph Engine(简称GE)中的插件信息,将原始框架网络中的算子进行解析并映射成适配昇腾AI处理器算子。
下文我们将适配昇腾AI处理器的算子称为CANN算子。
原理介绍
算子插件的实现包含CANN算子类型的注册、原始框架中算子类型的注册以及原始框架中算子属性到CANN算子属性的映射,算子的映射通过Parser模块完成。插件在整网络运行场景下的实现流程如图1所示。
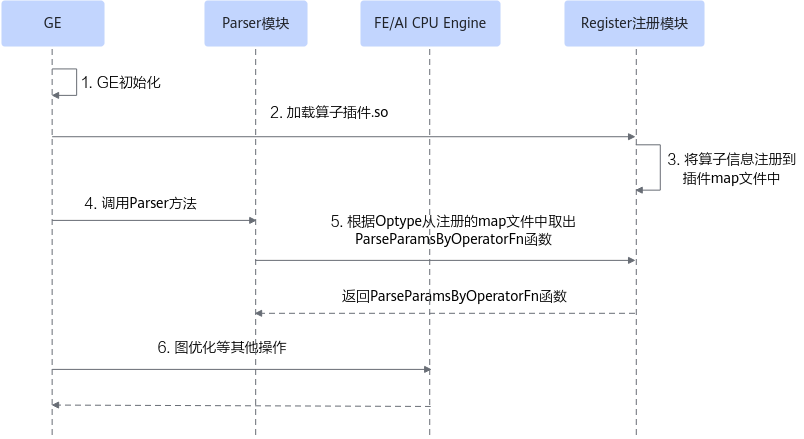
- 首先GE接收到第三方框架的原始网络模型,并进行初始化,网络模型的拓扑图我们简称为图。
- GE从Register注册模块中加载算子插件生成的.so文件,在CANN软件安装后文件存储路径的“opp/built-in/framework/”路径中。
- 读取算子插件.so中的算子相关信息,并将其注册到算子插件的map文件中(所有算子插件的相关信息都会以map的形式存储到一个文件中)。
- GE向Parser模块发送调用Parser方法的请求。
- Parser模块根据算子类型(OpType)从算子插件的map文件中取出对应的Parser函数,并返回实现函数ParseParamsByOperatorFn给Parser模块,Parser模块根据实现函数将第三方网络算子中的属性映射到CANN算子的属性,即算子原型中的属性定义,从而完成第三方网络中算子到CANN算子的映射。
- 后续会进行图准备、图拆分及图优化等一系列操作,最终生成适配昇腾AI处理器的网络模型。
插件实现
GE提供REGISTER_CUSTOM_OP宏,按照指定的算子名称完成算子的注册。
#include "register/register.h"
#include "graph/operator.h"
namespace domi
{
REGISTER_CUSTOM_OP("OpType")
.FrameworkType(TENSORFLOW)
.OriginOpType("OriginOpType")
.ParseParamsByOperatorFn(ParseParamByOpFunc)
.ImplyType(ImplyType::TVM); // TBE算子:ImplyType::TVM;AI CPU算子:ImplyType::AI_CPU
}
- 在代码实现文件顶部使用预编译命令“#include”将插件实现函数相关的头文件包含到插件实现文件中。
register.h存储在CANN软件安装后文件存储路径的“include/register/”目录下,包含该头文件,可使用算子注册相关类,调用算子注册相关的接口。
operator.h(可选),存储在CANN软件安装后文件存储路径的“include/graph/”目录下,包含该头文件,可以使用Operator类相关接口,获取算子输入输出及属性等算子信息。
- REGISTER_CUSTOM_OP:注册自定义算子,OpType为注册到GE中的算子类型,需要与算子原型注册中的OpType保持一致。
- FrameworkType:TENSORFLOW代表原始框架为TensorFlow。
- OriginOpType:算子在原始框架中的类型。
- ParseParamsByOperatorFn:用来注册解析算子属性的函数。
- ImplyType:指定算子的实现方式。ImplyType::TVM表示该算子是TBE算子;ImplyType::AI_CPU表示该算子是AI CPU算子。
下面详细介绍解析函数ParseParamsByOperatorFn,此函数的实现有以下几种场景:
场景 |
实现方法 |
|---|---|
原始TensorFlow算子中属性与CANN算子中属性一一对应,即属性的个数、属性名称与属性含义一致。 |
可直接使用自动映射回调函数AutoMappingByOpFn自动实现映射。 .ParseParamsByOperatorFn(AutoMappingByOpFn) AutoMappingByOpFn函数会将TensorFlow算子中比CANN算子多的属性追加到CANN算子的属性中去。 |
原始TensorFlow算子中属性与CANN算子中属性无法一一对应,则需要重新计算为CANN算子中对应属性赋值。 |
需要在回调函数ParseParamByOpFunc中进行属性解析的实现,详细实现方法可参见•算子属性无法一一对应。 |
对于TensorFlow原始图中不带数据排布格式信息的张量,GE在接收后会将其数据排布格式设置为ND,但对于某些格式敏感算子,ND为不正确的格式,需要在插件的解析函数中进行数据排布格式的设置。 |
需要在回调函数ParseParamByOpFunc中进行数据排布格式的设置,详细的设置方法可参见•格式敏感算子。 |
- 算子属性无法一一对应
REGISTER_OP("TopKV2") .Input("input: T") .Input("k: int32") .Output("values: T") .Output("indices: int32") .Attr("sorted: bool = true") .Attr("T: realnumbertype") .SetShapeFn(TopKShapeFn);其映射的CANN算子TopK的定义如下所示:
REG_OP(TopK) .INPUT(x, TensorType::RealNumberType()) .INPUT(k, TensorType({DT_INT32})) .OUTPUT(values, TensorType::RealNumberType()) .OUTPUT(indices, TensorType({DT_INT32})) .ATTR(sorted, Bool, true) .ATTR(largest, Bool, true) .ATTR(dim, Int, -1) .OP_END_FACTORY_REG(TopK)从以上定义中可以看出,CANN算子TopK的属性largest与dim在TensorFlow的TopKV2算子中未定义,所以我们需要在ParseParamsByOperatorFn的回调函数TopKMappingFn中实现对这两个属性的赋值,实现如下所示。
Status TopKMappingFn(const ge::Operator &op_src, ge::Operator& op) { // 使用AutoMappingFn函数实现可以对应的属性的映射 AutoMappingFn(op_src, op) != SUCCESS) { return FAILED; } // 为CANN算子TopK的dim属性赋初始值 int32_t dim = -1; op.SetAttr("dim", dim); // 为CANN算子TopK的largest属性赋初始值 bool largest = true; op.SetAttr("largest", largest); return SUCCESS; } REGISTER_CUSTOM_OP("TopK") .FrameworkType(TENSORFLOW) .OriginOpType("TopKV2") .ParseParamsByOperatorFn(TopKMappingFn) //调用TopKMappingFn函数进行属性解析 .ImplyType(ImplyType::TVM); - 数据排布格式敏感算子
- 对于在TensorFlow原图中有数据排布格式定义的算子,如果CANN算子规格中要求的张量数据排布格式定义与TensorFlow原图中张量的数据排布格式定义一致,则AutoMappingByOpFn函数会自动进行数据排布格式的处理。
- 对于在使用TensorFlow原图中没有数据排布格式定义,或者数据排布格式与CANN中算子规格要求不一致的算子,则需要在回调函数ParseParamByOpFunc中强制设置张量的Format以及OriginalFormat(当前版本Format与OriginalFormat设置为一致即可)。
例如针对Conv2D算子,TensorFlow接口规格以及CANN算子规格中的第二个输入filter支持的数据排布格式都为HWCN,但在TensorFlow原图(使用TensorFlow原生接口构造的图)中,输入filter的数据排布格式会直接继承属性“data_format”的值,所以需要在Parser函数中将filter的数据排布格式设置为期望的HWCN。如下所示:
const int kInputFilter = 1 Status ParseParamsConv2D(const ge::Operator &op_src, ge::Operator& op) { AutoMappingByOpFn(op_src, op); TensorDesc org_tensor_w = op.GetInputDesc(kInputFilter); org_tensor_w.SetOriginFormat(ge::FORMAT_HWCN); org_tensor_w.SetFormat(ge::FORMAT_HWCN); auto ret = op.UpdateInputDesc(kInputFilter, org_tensor_w); if (ret != ge::GRAPH_SUCCESS) { return FAILED; } return SUCCESS; }注意:以上仅为辅助描述此场景的示例,实际AI CPU的数据排布格式仅支持NHWC。
- 动态输入/输出算子
对于存在动态输入/输出的算子,需要在插件的回调函数ParseParamByOpFunc中使用AutoMappingByOpFnDynamic实现TensorFlow算子和CANN算子的匹配。
Status BoostedTreesBucketizeMapping(const ge::Operator& op_src, ge::Operator& op) { if (AutoMappingByOpFn(op_src, op) != SUCCESS) { return FAILED; } std::string attr_name = "num_features"; std::vector<std::string> dynamic_inputs {"float_values", "bucket_boundaries"}; std::string dynamic_output = "y"; vector<DynamicInputOutputInfo> dynamic_name_attr_value; // input dynamic tensor for (std::string input_name : dynamic_inputs) { DynamicInputOutputInfo name_attr(kInput, input_name.c_str(), input_name.size(), attr_name.c_str(), attr_name.size()); dynamic_name_attr_value.push_back(name_attr); } // output dynamic tensor DynamicInputOutputInfo name_attr(kOutput, dynamic_output.c_str(), dynamic_output.size(), attr_name.c_str(), attr_name.size()); dynamic_name_attr_value.push_back(name_attr); AutoMappingByOpFnDynamic(op_src, op, dynamic_name_attr_value); return SUCCESS; }
多对一映射
前面的插件实现中,我们讲的将TensorFlow网络中算子映射为CANN算子的场景都是一对一映射的场景,在某些场景下,为了提高计算性能,往往需要将TensorFlow网络中的多个小算子融合并映射为CANN的一个大算子,以充分利用硬件资源进行加速。
这种场景下,我们首先需要设计并开发Scope融合规则,然后再实现融合算子适配插件,与普通的一对一映射的算子适配插件实现不同,融合算子适配插件的定义如下所示:
REGISTER_CUSTOM_OP("OpType")
.FrameworkType(TENSORFLOW) // 原始框架为Tensorflow
.OriginOpType("OriginOpType") // 算子在原始框架中的类型,和GenerateFusionResult的SetType的内容保持一致
.FusionParseParamsFn(DecodeBboxV2ParseParams) // 用来注册解析融合算子属性的函数
.ImplyType(ImplyType::TVM); // 指定算子的实现方式,ImplyType::TVM表示该算子是TBE算子
- REGISTER_CUSTOM_OP中注册的OpType为映射的CANN算子类型。
- OriginOpType中注册的为Scope融合规则开发时,设置的融合算子的结果类型。
- FusionParseParamsFn为注册解析融合算子属性的函数,接口定义可参见FusionParseParamsFn(Overload)。
此处不对Scope融合规则开发以及融合算子适配插件的开发做详细说明,详细的开发指导可参见《TensorFlow Parser Scope融合规则开发指南》。
多对多映射
若您需要将TensorFlow网络中的多个算子融合并映射为CANN的多个算子,此种场景下,您无需进行算子适配插件的开发,仅需实现Scope融合规则,并在Scope融合规则开发时,设置融合结果,将其映射为对应的CANN算子即可。详细的开发指导可参见《TensorFlow Parser Scope融合规则开发指南》。
将算子映射为子图(一对多映射)
适配开发过程中可能会遇到如下场景:
- TensorFlow算子没有对应的CANN算子实现,但可以通过多个CANN算子组合实现其功能。
- TensorFlow算子和CANN算子实现上有差异,如TensorFlow算子的属性在CANN算子中是constant输入等。
这些场景下,需要将原TensorFlow框架中的一个算子映射为CANN中的多个算子。在插件实现时,我们先将映射后的CANN算子构造成一个子图,然后再将原TensorFlow框架中的算子映射为构造的子图。以将TensorFlow AddN算子转换为两个CANN Add算子为例,下面介绍其具体实现方法。
将算子映射为子图的场景下,注册代码如下:
REGISTER_CUSTOM_OP("PartitionedCall")
.FrameworkType(TENSORFLOW)
.OriginOpType("AddN")
.ParseParamsFn(ParseParamsAddn)
.ParseOpToGraphFn(ParseOpToGraphAddn)
.ImplyType(ImplyType::TVM);
下面仅介绍和普通注册函数的差异点:
- REGISTER_CUSTOM_OP("PartitionedCall"):注册子图“PartitionedCall”,PartitionedCall”是组合算子的统称。
- ParseParamsByOperatorFn(ParseParamsAddn):注册解析自定义算子参数的函数ParseParamsAddn。ParseParamsAddn中完成原始TensorFlow算子到PartitionedCall算子参数的映射,需要设置PartitionCall节点输入、输出个数,并设置其"original_type"属性为原始框架中的算子类型。
- ParseOpToGraphFn(ParseOpToGraphAddn):注册实现算子一对多子图映射的函数ParseOpToGraphAddn。ParseOpToGraphAddn中将PartitionedCall算子映射为子图,子图的构造通过Ascend Graph构图方式完成。关于ParseOpToGraphFn接口的详细介绍请参见ParseOpToGraphFn。Ascend Graph构图的详细介绍请参考《Ascend Graph开发指南》。
// ParseParamsByOperatorFn回调函数示例
Status ParseParamsAddn(const ge::Operator&op_src, ge::Operator&op_dest) {
// 1.设置PartitionCall节点(op_dest)的输入、输出个数和原始节点(op_src)一致
ge::Operator op_ori = const_cast<ge::Operator&>(op_src);
std::string in_name = "args";
std::string in_value = "in_num";
std::string out_name = "output";
std::string out_value = "out_num";
op_ori.SetAttr(in_value, 3);
op_ori.SetAttr(out_value, 1);
DynamicInputOutputInfo in_values(kInput, in_name.c_str(), in_name.size(), in_value.c_str(), in_value.size());
DynamicInputOutputInfo out_values(kOutput, out_name.c_str(), out_name.size(), out_value.c_str(), out_value.size());
AutoMappingByOpFnDynamic(op_ori, op_dest, {in_values, out_values});
// 2.如果有属性需要从原始节点(op_src)继承,可以在此处设置到op_dest中
...
// 3.设置属性"original_type"为原始框架中的算子类型
op_dest.SetAttr("original_type", "AddN");
return SUCCESS;
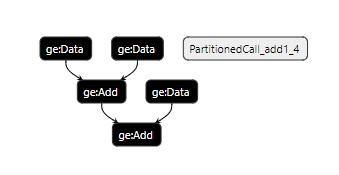
实现将一个AddN算子映射到两个CANN Add算子的回调函数示例如下, 此函数实现了两个CANN Add算子组成的子图的构造。
// ParseOpToGraphFn回调函数示例
static Status ParseOpToGraphAddn(const ge::Operator&op, ge::Graph&graph) {
// Data节点的index属性表示原始节点(op)的第index个输入
auto data_0 = ge::op::Data().set_attr_index(0);
auto data_1 = ge::op::Data().set_attr_index(1);
auto data_2 = ge::op::Data().set_attr_index(2);
// 创建add0算子实例,并设置算子输入为data_0和data_1
auto add0 = ge::op::Add("add0")
.set_input_x1(data_0)
.set_input_x2(data_1);
// 创建add1算子实例,并设置算子输入为data_2和add0
auto add1 = ge::op::Add("add1")
.set_input_x1(data_2)
.set_input_x2(add0);
// 设置图的输入输出
std::vector<ge::Operator> inputs{data_0, data_1, data_2};
// output设置和原始节点(op)保持一致
std::vector<std::pair<ge::Operator, std::vector<size_t>>> output_indexs;
output_indexs.emplace_back(add1, vector<std::size_t>{0});
graph.SetInputs(inputs).SetOutputs(output_indexs);
return SUCCESS;
}
构造的子图如下图所示。