Swish
功能说明
在神经网络中,Swish是一个重要的激活函数。计算公式如下,其中β为常数,PAR表示矢量计算单元一个迭代能够处理的元素个数 :
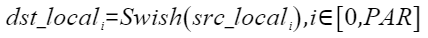
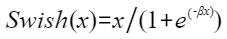
函数原型
1 2 | template <typename T, bool isReuseSource = false> __aicore__ inline void Swish(const LocalTensor<T> &dstLocal, const LocalTensor<T> &srcLocal, uint32_t dataSize, const T &scalarValue) |
参数说明
参数名 |
描述 |
|---|---|
T |
操作数的数据类型。 |
isReuseSource |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas推理系列产品AI Core,支持的数据类型为:half/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float |
srcLocal |
输入 |
源操作数。 源操作数的数据类型需要与目的操作数保持一致。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas推理系列产品AI Core,支持的数据类型为:half/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float |
dataSize |
输入 |
实际计算数据元素个数,dataSize∈[0, min(srcLocal.GetSize(), dstLocal.GetSize())] |
scalarValue |
输入 |
激活函数中的β参数。支持的数据类型为:half/float β参数的数据类型需要与源操作数和目的操作数保持一致。 |
返回值
无
支持的型号
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
约束说明
- 操作数地址偏移对齐要求请参见通用约束。
- 不支持源操作数与目的操作数地址重叠。
- 当前仅支持ND格式的输入,不支持其他格式。
- dataSize需要保证小于或等于srcTensor和dstTensor存储的元素范围。
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #include "kernel_operator.h" template <typename srcType> class KernelSwish { public: __aicore__ inline KernelSwish() {} __aicore__ inline void Init(GM_ADDR srcGm, GM_ADDR dstGm, uint32_t inputSize, srcType scalar) { dataSize = inputSize; scalarValue = scalar; srcGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(srcGm), dataSize); dstGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(dstGm), dataSize); pipe.InitBuffer(inQueueX, 1, dataSize * sizeof(srcType)); pipe.InitBuffer(outQueue, 1, dataSize * sizeof(srcType)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<srcType> srcLocal = inQueueX.AllocTensor<srcType>(); AscendC::DataCopy(srcLocal, srcGlobal, dataSize); inQueueX.EnQue(srcLocal); } __aicore__ inline void Compute() { AscendC::LocalTensor<srcType> dstLocal = outQueue.AllocTensor<srcType>(); AscendC::LocalTensor<srcType> srcLocal = inQueueX.DeQue<srcType>(); Swish(dstLocal, srcLocal, dataSize, scalarValue); outQueue.EnQue<srcType>(dstLocal); inQueueX.FreeTensor(srcLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<srcType> dstLocal = outQueue.DeQue<srcType>(); AscendC::DataCopy(dstGlobal, dstLocal, dataSize); outQueue.FreeTensor(dstLocal); } private: AscendC::GlobalTensor<srcType> srcGlobal; AscendC::GlobalTensor<srcType> dstGlobal; AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue; uint32_t dataSize = 0; srcType scalarValue = 0; }; template <typename dataType> __aicore__ void kernel_Swish_operator(GM_ADDR srcGm, GM_ADDR dstGm, uint32_t dataSize) { KernelSwish<dataType> op; dataType scalarValue = 1.702; op.Init(srcGm, dstGm, dataSize, scalarValue); op.Process(); } |
结果示例如下:
输入数据(srcLocal): [ 0.5312 -3.654 -2.92 3.787 -3.059 3.77 0.571 -0.668 -0.09534 0.5454 -1.801 -1.791 1.563 0.878 3.973 1.799 2.023 1.018 3.082 -3.814 2.254 -3.717 0.4675 -0.4631 -2.47 0.9814 -0.854 3.31 3.256 3.764 1.867 -1.773] 输出数据(dstLocal): [ 0.3784 -0.007263 -0.02016 3.78 -0.01666 3.762 0.414 -0.1622 -0.04382 0.3909 -0.0803 -0.08105 1.461 0.717 3.969 1.719 1.96 0.8647 3.066 -0.00577 2.207 -0.006626 0.3223 -0.1448 -0.03622 0.8257 -0.1617 3.297 3.244 3.756 1.792 -0.0825]
父主题: Swish
