DataCacheCleanAndInvalid
功能说明
在AI Core内部,Scalar单元和DMA单元都可能对Global Memory进行访问。
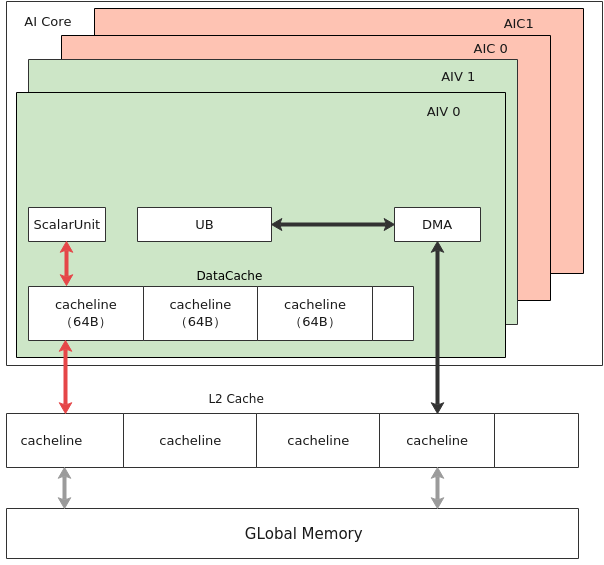
如上图所示:
- DMA搬运单元读写Global Memory,数据通过DataCopy等接口在UB等Local Memory和Global Memory间交互,没有Cache一致性问题;
- Scalar单元访问Global Memory,首先会访问的每个核内的Data Cache,因此存在Data Cache与Global Memory的Cache一致性问题。
该接口用来刷新Cache,保证Cache的一致性,使用场景如下:
- 读取Global Memory的数据,但该数据可能在外部被其余核修改,此时需要使用DataCacheCleanAndInvalid接口,将DataCache置为无效,直接访问Global Memory,获取最新数据;
- 用户通过Scalar单元写Global Memory的数据,希望立刻写出,也需要使用DataCacheCleanAndInvalid接口。
函数原型
针对Atlas A2训练系列产品:
template <typename T, CacheLine entireType, DcciDst dcciDst>
__aicore__ inline void DataCacheCleanAndInvalid(const GlobalTensor<T>& dstTensor);
template <typename T, CacheLine entireType, DcciDst dcciDst>
__aicore__ inline void DataCacheCleanAndInvalid(const LocalTensor<T>& dstTensor);
针对Atlas推理系列产品AI Core:
template <typename T, CacheLine entireType>
__aicore__ inline void DataCacheCleanAndInvalid(const GlobalTensor<T>& dstTensor);
参数说明
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstTensor |
输入 |
需要刷新Cache的Tensor。 |
entireType |
输入 |
指令操作的模式: SINGLE_CACHE_LINE:只刷新传入地址所在的cacheLine,注意如果该地址非64B对齐,只会操作传入地址到64B对齐的部分。 ENTIRE_DATA_CACHE:此时传入的地址无效,核内会刷新整个Data Cache,但是耗时较大,性能敏感的场景慎用。 |
dcciDst |
输入 |
表示使用该接口来保证Data Cache与哪一种存储保持一致性,类型为DcciDst枚举类。 CACHELINE_ALL:与CACHELINE_OUT效果一致; CACHELINE_UB:预留参数,当前不涉及; CACHELINE_OUT:表示通过该接口来保证Data Cache与Global Memory的一致性; CACHELINE_ATOMIC:预留参数,当前不涉及。 |
返回值
无
支持的型号
Atlas A2训练系列产品
Atlas推理系列产品AI Core
约束说明
无
调用示例
// 场景1:SINGLE_CACHE_LINE 模式,假设mmAddr_为0x20(非64B对齐)
GlobalTensor<uint64_t> global;
global.SetGlobalBuffer((__gm__ uint64_t*)mmAddr_ + GetBlockIdx() * 1024);
for( int i = 0; i < 8; i++) {
global.SetValue(i, GetBlockIdx());
}
// 由于首地址非64B对齐,调用DataCacheCleanAndInvalid指令后,只会立刻刷新前4个数
DataCacheCleanAndInvalid<uint64_t, CacheLine::SINGLE_CACHE_LINE, DcciDst::CACHELINE_OUT>(global);
// 场景2:SINGLE_CACHE_LINE 模式,假设mmAddr_为0x20(非64B对齐)
GlobalTensor<uint64_t> global;
global.SetGlobalBuffer((__gm__ uint64_t*)mmAddr_ + GetBlockIdx() * 1024);
for( int i = 0; i < 8; i++) {
global.SetValue(i, GetBlockIdx());
}
// 由于首地址非64B对齐,调用2条DataCacheCleanAndInvalid指令,刷新所有的8个数
DataCacheCleanAndInvalid<uint64_t, CacheLine::SINGLE_CACHE_LINE, DcciDst::CACHELINE_OUT>(global);
DataCacheCleanAndInvalid<uint64_t, CacheLine::SINGLE_CACHE_LINE, DcciDst::CACHELINE_OUT>(global[4]);
// 场景3:SINGLE_CACHE_LINE 模式,假设mmAddr_为0x20(非64B对齐)
GlobalTensor<uint64_t> global;
global.SetGlobalBuffer((__gm__ uint64_t*)mmAddr_);
for( int i = 0; i < 8; i++) {
global.SetValue(i, GetBlockIdx());
}
// 由于首地址非64B对齐,且算子中多核同时在操作同一个地址
// 调用DataCacheCleanAndInvalid指令后,只会立刻刷新前4个数
// 且由于多核的时间不一致,最终结果存在随机性,后执行的核会覆盖前面核的结果
DataCacheCleanAndInvalid<uint64_t, CacheLine::SINGLE_CACHE_LINE, DcciDst::CACHELINE_OUT>(global);
// 场景4:ENTIRE_DATA_CACHE 模式,假设mmAddr_为0x20(非64B对齐)
GlobalTensor<uint64_t> global;
global.SetGlobalBuffer((__gm__ uint64_t*)mmAddr_ + GetBlockIdx() * 1024);
for( int i = 0; i < 8; i++) {
global.SetValue(i, GetBlockIdx());
}
// 刷新整个Data Cache,性能较差
DataCacheCleanAndInvalid<uint64_t, CacheLine::ENTIRE_DATA_CACHE, DcciDst::CACHELINE_OUT>(global);