均匀量化
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的FP32数据或16比特的FP16数据,将FP32/FP16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行基于精度的自动量化或量化感知训练或手工调优。均匀量化支持量化的层以及约束如下,量化示例请参见获取更多样例。
量化方式 |
支持的层类型 |
约束 |
备注 |
|---|---|---|---|
均匀量化 |
torch.nn.Linear |
- |
复用层(共用weight和bias参数)不支持量化。 |
torch.nn.Conv2d |
padding_mode为zeros |
||
torch.nn.Conv3d |
dilation_d为1,dilation_h/dilation_w >= 1 |
||
torch.nn.ConvTranspose2d |
padding_mode为zeros |
||
torch.nn.AvgPool2d |
- |
- |
接口调用流程
均匀量化接口调用流程如图1所示。

蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,工具使用分为如下场景:
- 用户首先构造PyTorch的原始模型,然后使用create_quant_config生成量化配置文件。
- 根据PyTorch模型和量化配置文件,即可调用quantize_model接口对原始PyTorch模型进行优化,优化后的PyTorch模型中包含了量化算法。
- 使用校准集在PyTorch环境下执行前向推理,产生量化因子,并将量化因子输出到文件中。
- 最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在昇腾AI处理器的模型文件。
- 精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
fake_quant模型主要用于验证量化后模型的精度,可以在ONNX Runtime环境下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,以INT8量化为例,Quant层、Conv2d卷积层和DeQuant层之间的数据都是Float32数据类型的,其中Quant层将数据量化到INT8又反量化为Float32,权重也是量化到INT8又反量化为Float32,实际卷积层的计算是基于Float32数据类型的,该模型用于在ONNX Runtime环境验证量化后模型的精度,不能够用于ATC工具转换成om模型。图2 fake_quant模型

- 部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到在昇腾AI处理器。
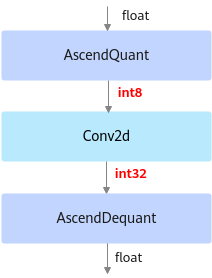
以INT8量化为例,deploy模型由于已经将权重等转换成为了INT8, INT32类型, 因此不能在ONNX Runtime环境上执行推理计算。如下图所示,deploy模型的AscendQuant层将Float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8,INT32数据类型的,输出为INT32数据类型经过AscendDeQuant层转换成Float32数据类型传输给下一个网络层。图3 deploy模型
- 精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
调用示例
调用示例请参见快速入门。
父主题: 手工量化
