TransDataTo5HD
功能说明
数据格式转换,一般用于将NCHW格式转换成NC1HWC0格式。特别的,也可以用于二维矩阵数据块的转置。完成转置功能时,相比于Transpose接口,Transpose仅支持16*16大小的矩阵转置;本接口单次repeat内可处理512Byte的数据(16个datablock),根据数据类型不同,支持不同shape的矩阵转置(比如数据类型为half时,单次repeat可完成16*16大小的矩阵转置),同还可以支持多次repeat操作。
单次repeat内转换规则如下:
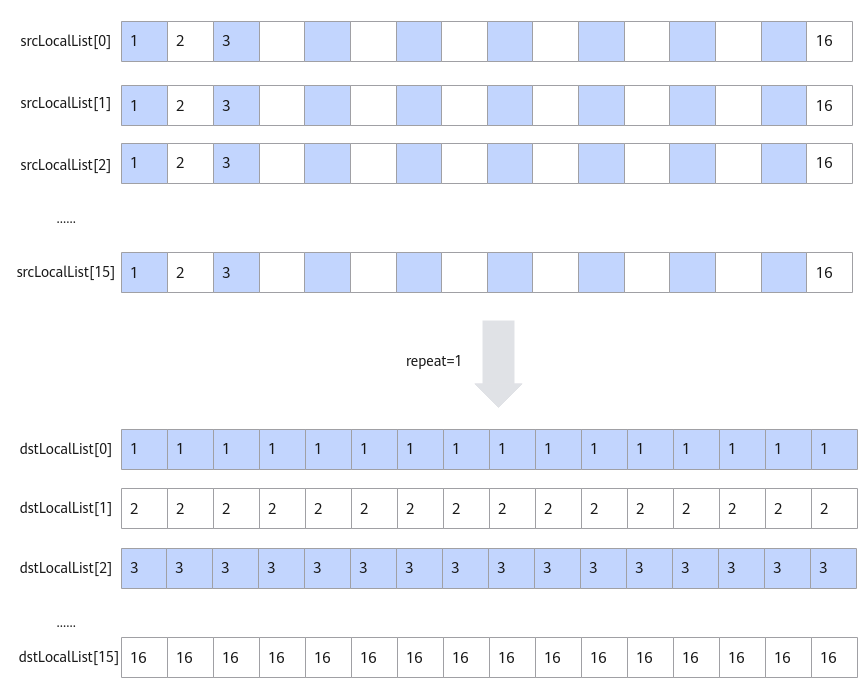
- 当输入数据类型是int16_t/uint16_t/half时,每个datablock中包含16个数,指令内部会循环16次,每次循环都会分别从指定的16个datablock中的对应位置取值,组成一个新的datablock单元放入目的地址中。如下图所示,图中的srcLocalList[0]-srcLocalList[15]代表源操作数的16个datablock。
图1 输入数据类型为int16_t/uint16_t/half时的转换规则
- 当数据类型是float/int32_t/uint32_t时,每个datablock包含8个数,指令内部会循环8次,每次循环都会分别从指定的16个datablock中的对应位置取值,组成2个新的datablock放入目的地址中。如下图所示:
图2 输入数据类型为float/int32_t/uint32_t时的转换规则

- 当数据类型是int8_t/uint8_t时,每个datablock包含32个数,指令内部会循环16次,每次循环都会分别从指定的16个datablock中的对应位置取值,组成半个datablock放入目的地址中, 读取和存放是在datablock的高半部还是低半部由参数srcHighHalf和dstHighHalf决定。如下图所示:
图3 输入数据类型为int8_t/uint8_t时的转换规则

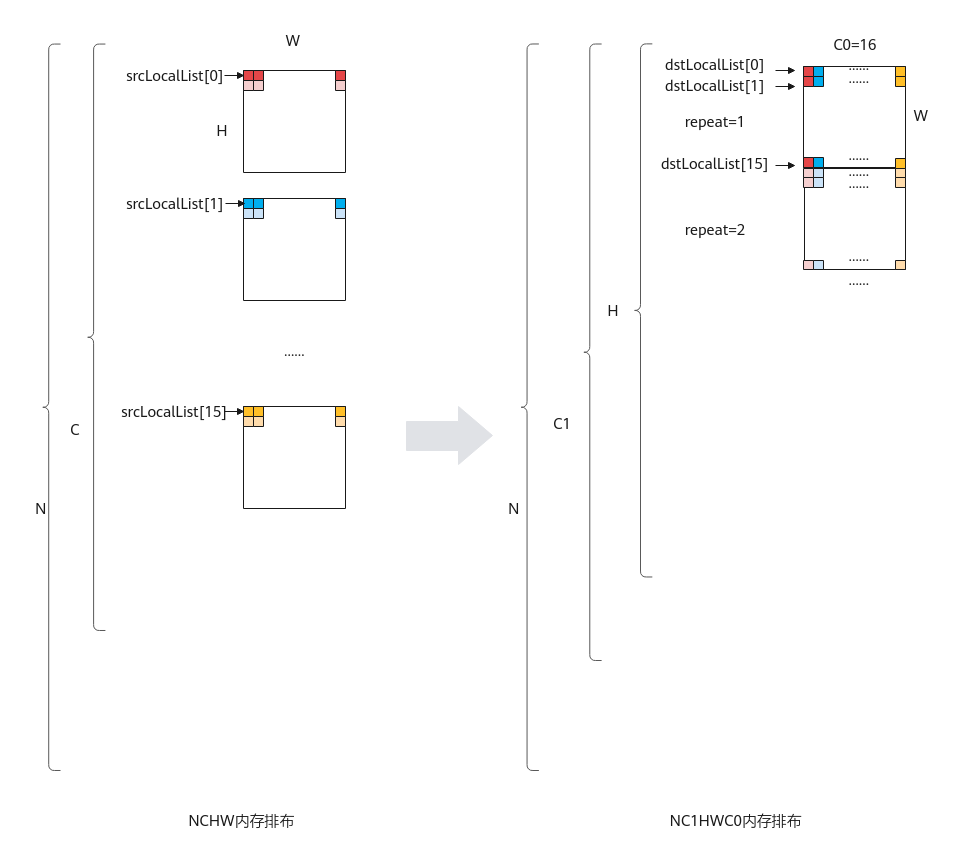
基于以上的转换规则,使用该接口进行NC1HWC0格式转换或者矩阵转置。NC1HWC0格式转换相对复杂,这里给出其具体的转换方法:
NCHW格式转换成NC1HWC0格式时,如果是数据类型是float/int32_t/uint32_t/int16_t/unint16_t/half, 则C0=16;如果数据类型是uint8_t/int8_t,则C0=32。下图以C0=16为例进行介绍:
函数原型
- dstLocalList与srcLocalList类型为LocaTensor的数组
__aicore__ inline void TransDataTo5HD(const LocalTensor<T>& dstLocalList[16], const LocalTensor<T>& srcLocalList[16], const TransDataTo5HDParams& transDataParams);
- dstLocalList与srcLocalList类型为uint64_t的数组,数组元素对应LocaTensor的地址值,该接口性能更优。开发者可以通过LocalTensor的GetPhyAddr接口获取该地址值。
__aicore__ inline void TransDataTo5HD(uint64_t dstLocalList[16], uint64_t srcLocalList[16], const TransDataTo5HDParams& transDataParams);
- dstLocal与srcLocal类型为uint64_t的LocalTensor,连续存储对应LocalTensor的地址值。开发者可以通过LocalTensor的GetPhyAddr接口获取该地址值。
__aicore__ inline void TransDataTo5HD(const LocalTensor<uint64_t>& dstLocal, const LocalTensor<uint64_t>& srcLocal, const TransDataTo5HDParams& transDataParams);
参数说明
参数名 |
描述 |
|---|---|
T |
操作数数据类型。 Atlas 训练系列产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half Atlas推理系列产品AI Core,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float |
参数名称 |
输入/输出 |
含义 |
|---|---|---|
dstLocalList |
输出 |
目的操作数地址序列。 类型为LocalTensor或者LocalTensor的地址值,LocalTensor支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas 训练系列产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half Atlas推理系列产品AI Core,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float |
srcLocalList |
输入 |
源操作数地址序列。 类型为LocalTensor或者LocalTensor的地址值,LocalTensor支持的TPosition为VECIN/VECCALC/VECOUT。LocalTensor的起始地址需要32B对齐。 数据类型须与dstLocalList保持一致。 Atlas 训练系列产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half Atlas推理系列产品AI Core,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int8_t/uint8_t/int16_t/uint16_t/half/int32_t/uint32_t/float |
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,连续存储对应LocalTensor的地址值。LocalTensor支持的TPosition为VECIN/VECCALC/VECOUT。LocalTensor的起始地址需要32B对齐。 Atlas推理系列产品AI Core,支持的数据类型为:uint64_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint64_t |
srcLocal |
输入 |
源操作数。 类型为LocalTensor,连续存储对应LocalTensor的地址值。LocalTensor支持的TPosition为VECIN/VECCALC/VECOUT。LocalTensor的起始地址需要32B对齐。 Atlas推理系列产品AI Core,支持的数据类型为:uint64_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint64_t |
transDataParams |
输入 |
控制TransdataTo5HD的数据结构。结构体内包含:读取和写入位置的控制参数,迭代次数,相邻迭代间的地址步长等参数。该数据结构的定义请参考表3。 |
支持的型号
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
注意事项
- 进行NCHW格式到NC1HWC0格式的转换时,一般用法是将srcLocalList/dstLocalList中的每个元素配置为每个HW平面的起点。
- 为了性能更优,int8_t/uint8_t时建议先固定dstHighHalf、srcHighHalf,在HW方向repeat后,再改变dstHighHalf、srcHighHalf。
- 为了节省地址空间,开发者可以定义一个Tensor,供源操作数与目的操作数同时使用(即地址重叠),相关约束如下:
- 对于单次repeat(repeatTimes=1),且源操作数序列与目的操作数序列之间要求100%完全重叠,不支持部分重叠,且每一个block都必须相等。
- 对于多次repeat(repeatTimes>1),若源操作数序列与目的操作数序列之间存在依赖,即第N次迭代的目的操作数是第N+1次的源操作数,这种情况是不支持地址重叠的。
- 操作数地址偏移对齐要求请参见通用约束。
- dstLocal与srcLocal中的地址需要连续存放,详见调用示例。
返回值
无
调用示例
- NCHW格式转换成NC1HWC0格式调用示例,其中输入数据为half类型,输入NCHW格式为(2,32,16,16),目标格式NC1HWC0为(2,2,16,16,16)。
#include "kernel_operator.h" namespace AscendC { class KernelTransDataTo5HD { public: __aicore__ inline KernelTransDataTo5HD() {} __aicore__ inline void Init(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { srcGlobal.SetGlobalBuffer((__gm__ half *)src); dstGlobal.SetGlobalBuffer((__gm__ half *)dstGm); pipe.InitBuffer(inQueueSrc, 1, srcDataSize * sizeof(half)); pipe.InitBuffer(workQueueSrc1, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(workQueueSrc2, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(half)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { LocalTensor<half> srcLocal = inQueueSrc.AllocTensor<half>(); DataCopy(srcLocal, srcGlobal, srcDataSize); inQueueSrc.EnQue(srcLocal); } __aicore__ inline void Compute() { LocalTensor<half> srcLocal = inQueueSrc.DeQue<half>(); LocalTensor<half> dstLocal = outQueueDst.AllocTensor<half>(); TransDataTo5HDParams transDataParams; transDataParams.dstHighHalf = false; transDataParams.srcHighHalf = false; transDataParams.repeatTimes = 16; transDataParams.dstRepStride = 16; transDataParams.srcRepStride = 1; for(int j = 0; j < 4; j++) { // // 入参类型是LocalTensor的调用方式 // LocalTensor<half> dstLocalList[16]; // for (int i = 0; i < 16; i++) { // dstLocalList[i] = dstLocal[j * c0size * height * width + width * i]; // } // LocalTensor<half> srcLocalList[16]; // for (int i = 0; i < 16; i++) { // srcLocalList[i] = srcLocal[j * c0size * height * width + height * width * i]; // } // TransDataTo5HD<half>(dstLocalList, srcLocalList, transDataParams); // 入参类型是LocalTensor地址值的调用方式,推荐使用 uint64_t dstLocalList[16]; for (int i = 0; i < 16; i++) { dstLocalList[i] = (uint64_t)(dstLocal[j * c0size * height * width + width * i].GetPhyAddr()); } uint64_t srcLocalList[16]; for (int i = 0; i < 16; i++) { srcLocalList[i] = (uint64_t)(srcLocal[j * c0size * height * width + height * width * i].GetPhyAddr()); } TransDataTo5HD<half>(dstLocalList, srcLocalList, transDataParams); // // 入参类型是地址LocalTensor的调用方式 // LocalTensor<uint64_t> dst = workQueueSrc1.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // dst.SetValue(i, (uint64_t)(dstLocal[j * c0size * height * width + width * i].GetPhyAddr())); // } // LocalTensor<uint64_t> src = workQueueSrc2.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // src.SetValue(i, (uint64_t)(srcLocal[j * c0size * height * width + height * width * i].GetPhyAddr())); // } // TransDataTo5HD<half>(dst, src, transDataParams); // workQueueSrc1.FreeTensor(dst); // workQueueSrc2.FreeTensor(src); } outQueueDst.EnQue<half>(dstLocal); inQueueSrc.FreeTensor(srcLocal); } __aicore__ inline void CopyOut() { LocalTensor<half> dstLocal = outQueueDst.DeQue<half>(); DataCopy(dstGlobal, dstLocal, dstDataSize); outQueueDst.FreeTensor(dstLocal); } private: TPipe pipe; TQue<QuePosition::VECIN, 1> inQueueSrc; TQue<QuePosition::VECIN, 1> workQueueSrc1; TQue<QuePosition::VECIN, 1> workQueueSrc2; TQue<QuePosition::VECOUT, 1> outQueueDst; GlobalTensor<half> srcGlobal, dstGlobal; int srcDataSize = 16384; int dstDataSize = 16384; int width = 16; // H int height = 16; // W int c0size = 16; // C0 }; } // namespace AscendC extern "C" __global__ __aicore__ void vec_transdata5hd_b16_nchw2nc1hwc0(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { AscendC::KernelTransDataTo5HD op; op.Init(src, dstGm); op.Process(); } 输入数据: [[[[ 0. 0. 0. ... 0. 0. 0.] [ 0. 0. 0. ... 0. 0. 0.] [ 0. 0. 0. ... 0. 0. 0.] ... [ 0. 0. 0. ... 0. 0. 0.] [ 0. 0. 0. ... 0. 0. 0.] [ 0. 0. 0. ... 0. 0. 0.]] [[ 1. 1. 1. ... 1. 1. 1.] [ 1. 1. 1. ... 1. 1. 1.] [ 1. 1. 1. ... 1. 1. 1.] ... [ 1. 1. 1. ... 1. 1. 1.] [ 1. 1. 1. ... 1. 1. 1.] [ 1. 1. 1. ... 1. 1. 1.]] [[ 2. 2. 2. ... 2. 2. 2.] [ 2. 2. 2. ... 2. 2. 2.] [ 2. 2. 2. ... 2. 2. 2.] ... [ 2. 2. 2. ... 2. 2. 2.] [ 2. 2. 2. ... 2. 2. 2.] [ 2. 2. 2. ... 2. 2. 2.]] ... [[29. 29. 29. ... 29. 29. 29.] [29. 29. 29. ... 29. 29. 29.] [29. 29. 29. ... 29. 29. 29.] ... [29. 29. 29. ... 29. 29. 29.] [29. 29. 29. ... 29. 29. 29.] [29. 29. 29. ... 29. 29. 29.]] [[30. 30. 30. ... 30. 30. 30.] [30. 30. 30. ... 30. 30. 30.] [30. 30. 30. ... 30. 30. 30.] ... [30. 30. 30. ... 30. 30. 30.] [30. 30. 30. ... 30. 30. 30.] [30. 30. 30. ... 30. 30. 30.]] [[31. 31. 31. ... 31. 31. 31.] [31. 31. 31. ... 31. 31. 31.] [31. 31. 31. ... 31. 31. 31.] ... [31. 31. 31. ... 31. 31. 31.] [31. 31. 31. ... 31. 31. 31.] [31. 31. 31. ... 31. 31. 31.]]] [[[32. 32. 32. ... 32. 32. 32.] [32. 32. 32. ... 32. 32. 32.] [32. 32. 32. ... 32. 32. 32.] ... [32. 32. 32. ... 32. 32. 32.] [32. 32. 32. ... 32. 32. 32.] [32. 32. 32. ... 32. 32. 32.]] [[33. 33. 33. ... 33. 33. 33.] [33. 33. 33. ... 33. 33. 33.] [33. 33. 33. ... 33. 33. 33.] ... [33. 33. 33. ... 33. 33. 33.] [33. 33. 33. ... 33. 33. 33.] [33. 33. 33. ... 33. 33. 33.]] [[34. 34. 34. ... 34. 34. 34.] [34. 34. 34. ... 34. 34. 34.] [34. 34. 34. ... 34. 34. 34.] ... [34. 34. 34. ... 34. 34. 34.] [34. 34. 34. ... 34. 34. 34.] [34. 34. 34. ... 34. 34. 34.]] ... [[61. 61. 61. ... 61. 61. 61.] [61. 61. 61. ... 61. 61. 61.] [61. 61. 61. ... 61. 61. 61.] ... [61. 61. 61. ... 61. 61. 61.] [61. 61. 61. ... 61. 61. 61.] [61. 61. 61. ... 61. 61. 61.]] [[62. 62. 62. ... 62. 62. 62.] [62. 62. 62. ... 62. 62. 62.] [62. 62. 62. ... 62. 62. 62.] ... [62. 62. 62. ... 62. 62. 62.] [62. 62. 62. ... 62. 62. 62.] [62. 62. 62. ... 62. 62. 62.]] [[63. 63. 63. ... 63. 63. 63.] [63. 63. 63. ... 63. 63. 63.] [63. 63. 63. ... 63. 63. 63.] ... [63. 63. 63. ... 63. 63. 63.] [63. 63. 63. ... 63. 63. 63.] [63. 63. 63. ... 63. 63. 63.]]]] 输出数据: [[[[[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]] [[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]] [[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]] ... [[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]] [[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]] [[ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] ... [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.] [ 0. 1. 2. ... 13. 14. 15.]]] [[[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]] [[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]] [[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]] ... [[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]] [[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]] [[16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] ... [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.] [16. 17. 18. ... 29. 30. 31.]]]] [[[[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]] [[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]] [[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]] ... [[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]] [[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]] [[32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] ... [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.] [32. 33. 34. ... 45. 46. 47.]]] [[[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]] [[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]] [[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]] ... [[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]] [[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]] [[48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] ... [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.] [48. 49. 50. ... 61. 62. 63.]]]]]
- 用于二维矩阵数据块的转置的int8_t(8位比特位)调用示例
#include "kernel_operator.h" namespace AscendC { class KernelTransDataTo5HD { public: __aicore__ inline KernelTransDataTo5HD() {} __aicore__ inline void Init(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { srcGlobal.SetGlobalBuffer((__gm__ int8_t *)src); dstGlobal.SetGlobalBuffer((__gm__ int8_t *)dstGm); pipe.InitBuffer(inQueueSrc, 1, srcDataSize * sizeof(int8_t)); pipe.InitBuffer(workQueueSrc1, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(workQueueSrc2, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(int8_t)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { LocalTensor<int8_t> srcLocal = inQueueSrc.AllocTensor<int8_t>(); DataCopy(srcLocal, srcGlobal, srcDataSize); inQueueSrc.EnQue(srcLocal); } __aicore__ inline void Compute() { LocalTensor<int8_t> srcLocal = inQueueSrc.DeQue<int8_t>(); LocalTensor<int8_t> dstLocal = outQueueDst.AllocTensor<int8_t>(); for(int i = 0;i<dstDataSize; i++){ dstLocal.SetValue(i,0); } TransDataTo5HDParams transDataParams; // 写入dstLocalList的高半位 transDataParams.dstHighHalf = 1; // 从srcLocalList的高半位读取数据 transDataParams.srcHighHalf = 1; transDataParams.repeatTimes = 1; transDataParams.dstRepStride = 0; transDataParams.srcRepStride = 0; // 入参类型是LocalTensor的调用方式 LocalTensor<int8_t> dstLocalList[16]; for (int i = 0; i < 16; i++) { dstLocalList[i] = dstLocal[width * i]; } LocalTensor<int8_t> srcLocalList[16]; for (int i = 0; i < 16; i++) { srcLocalList[i] = srcLocal[width * i]; } TransDataTo5HD(dstLocalList, srcLocalList, transDataParams); // 入参类型是LocalTensor地址值的调用方式 // uint64_t dstLocalList[16]; // for (int i = 0; i < 16; i++) { // dstLocalList[i] = (uint64_t)(dstLocal[width * i].GetPhyAddr()); // } // uint64_t srcLocalList[16]; // for (int i = 0; i < 16; i++) { // srcLocalList[i] = (uint64_t)(srcLocal[width * i].GetPhyAddr()); // } // TransDataTo5HD<int8_t>(dstLocalList, srcLocalList, transDataParams); // 入参类型是地址LocalTensor的调用方式 // LocalTensor<uint64_t> dst = workQueueSrc1.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // dst.SetValue(i, (uint64_t)(dstLocal[width * i].GetPhyAddr())); // } // LocalTensor<uint64_t> src = workQueueSrc2.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // src.SetValue(i, (uint64_t)(srcLocal[width * i].GetPhyAddr())); // } // TransDataTo5HD<int8_t>(dst, src, transDataParams); // workQueueSrc1.FreeTensor(dst); // workQueueSrc2.FreeTensor(src); outQueueDst.EnQue<int8_t>(dstLocal); inQueueSrc.FreeTensor(srcLocal); } __aicore__ inline void CopyOut() { LocalTensor<int8_t> dstLocal = outQueueDst.DeQue<int8_t>(); DataCopy(dstGlobal, dstLocal, dstDataSize); outQueueDst.FreeTensor(dstLocal); } private: TPipe pipe; TQue<QuePosition::VECIN, 1> inQueueSrc; TQue<QuePosition::VECIN, 1> workQueueSrc1; TQue<QuePosition::VECIN, 1> workQueueSrc2; TQue<QuePosition::VECOUT, 1> outQueueDst; GlobalTensor<int8_t> srcGlobal, dstGlobal; int srcDataSize = 512; int dstDataSize = 512; int width = 32; }; } // namespace AscendC extern "C" __global__ __aicore__ void transdata5hd_simple_kernel(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { AscendC::KernelTransDataTo5HD op; op.Init(src, dstGm); op.Process(); } 输入数据: [[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31] [ 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63] [ 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95] [ 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127] [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31] [ 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63] [ 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95] [ 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127] [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31] [ 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63] [ 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95] [ 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127] [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31] [ 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63] [ 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95] [ 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127]] 输出数据: // 从输入数据的高半位读取数据,写入输出数据的高半位 [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 48 80 112 16 48 80 112 16 48 80 112 16 48 80 112 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 17 49 81 113 17 49 81 113 17 49 81 113 17 49 81 113 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 50 82 114 18 50 82 114 18 50 82 114 18 50 82 114 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 19 51 83 115 19 51 83 115 19 51 83 115 19 51 83 115 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 20 52 84 116 20 52 84 116 20 52 84 116 20 52 84 116 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 53 85 117 21 53 85 117 21 53 85 117 21 53 85 117 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 22 54 86 118 22 54 86 118 22 54 86 118 22 54 86 118 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 23 55 87 119 23 55 87 119 23 55 87 119 23 55 87 119 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 24 56 88 120 24 56 88 120 24 56 88 120 24 56 88 120 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 25 57 89 121 25 57 89 121 25 57 89 121 25 57 89 121 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 58 90 122 26 58 90 122 26 58 90 122 26 58 90 122 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 27 59 91 123 27 59 91 123 27 59 91 123 27 59 91 123 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 28 60 92 124 28 60 92 124 28 60 92 124 28 60 92 124 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 29 61 93 125 29 61 93 125 29 61 93 125 29 61 93 125 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 30 62 94 126 30 62 94 126 30 62 94 126 30 62 94 126 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 31 63 95 127 31 63 95 127 31 63 95 127 31 63 95 127 ]] - 用于二维矩阵数据块的转置的half(16位比特位)调用示例
#include "kernel_operator.h" namespace AscendC { class KernelTransDataTo5HD { public: __aicore__ inline KernelTransDataTo5HD() {} __aicore__ inline void Init(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { srcGlobal.SetGlobalBuffer((__gm__ half *)src); dstGlobal.SetGlobalBuffer((__gm__ half *)dstGm); pipe.InitBuffer(inQueueSrc, 1, srcDataSize * sizeof(half)); pipe.InitBuffer(workQueueSrc1, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(workQueueSrc2, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(half)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { LocalTensor<half> srcLocal = inQueueSrc.AllocTensor<half>(); DataCopy(srcLocal, srcGlobal, srcDataSize); inQueueSrc.EnQue(srcLocal); } __aicore__ inline void Compute() { LocalTensor<half> srcLocal = inQueueSrc.DeQue<half>(); LocalTensor<half> dstLocal = outQueueDst.AllocTensor<half>(); TransDataTo5HDParams transDataParams; transDataParams.dstHighHalf = false; transDataParams.srcHighHalf = false; transDataParams.repeatTimes = 1; transDataParams.dstRepStride = 0; transDataParams.srcRepStride = 0; // 入参类型是LocalTensor的调用方式 LocalTensor<int8_t> dstLocalList[16]; for (int i = 0; i < 16; i++) { dstLocalList[i] = dstLocal[width * i]; } LocalTensor<int8_t> srcLocalList[16]; for (int i = 0; i < 16; i++) { srcLocalList[i] = srcLocal[width * i]; } TransDataTo5HD(dstLocalList, srcLocalList, transDataParams); // 入参类型是LocalTensor地址值的调用方式 // uint64_t dstLocalList[16]; // for (int i = 0; i < 16; i++) { // dstLocalList[i] = (uint64_t)(dstLocal[width * i].GetPhyAddr()); // } // uint64_t srcLocalList[16]; // for (int i = 0; i < 16; i++) { // srcLocalList[i] = (uint64_t)(srcLocal[width * i].GetPhyAddr()); // } // TransDataTo5HD<half>(dstLocalList, srcLocalList, transDataParams); // 入参类型是地址LocalTensor的调用方式 // LocalTensor<uint64_t> dst = workQueueSrc1.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // dst.SetValue(i, (uint64_t)(dstLocal[width * i].GetPhyAddr())); // } // LocalTensor<uint64_t> src = workQueueSrc2.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // src.SetValue(i, (uint64_t)(srcLocal[width * i].GetPhyAddr())); // } // TransDataTo5HD<half>(dst, src, transDataParams); // workQueueSrc1.FreeTensor(dst); // workQueueSrc2.FreeTensor(src); outQueueDst.EnQue<half>(dstLocal); inQueueSrc.FreeTensor(srcLocal); } __aicore__ inline void CopyOut() { LocalTensor<half> dstLocal = outQueueDst.DeQue<half>(); DataCopy(dstGlobal, dstLocal, dstDataSize); outQueueDst.FreeTensor(dstLocal); } private: TPipe pipe; TQue<QuePosition::VECIN, 1> inQueueSrc; TQue<QuePosition::VECIN, 1> workQueueSrc1; TQue<QuePosition::VECIN, 1> workQueueSrc2; TQue<QuePosition::VECOUT, 1> outQueueDst; GlobalTensor<half> srcGlobal, dstGlobal; int srcDataSize = 256; int dstDataSize = 256; int width = 16; }; } // namespace AscendC extern "C" __global__ __aicore__ void nchwconv_demo_first(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { AscendC::KernelTransDataTo5HD op; op.Init(src, dstGm); op.Process(); } 输入数据(src): [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.] [ 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31.] [ 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47.] [ 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63.] [ 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79.] [ 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95.] [ 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111.] [112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127.] [128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143.] [144. 145. 146. 147. 148. 149. 150. 151. 152. 153. 154. 155. 156. 157. 158. 159.] [160. 161. 162. 163. 164. 165. 166. 167. 168. 169. 170. 171. 172. 173. 174. 175.] [176. 177. 178. 179. 180. 181. 182. 183. 184. 185. 186. 187. 188. 189. 190. 191.] [192. 193. 194. 195. 196. 197. 198. 199. 200. 201. 202. 203. 204. 205. 206. 207.] [208. 209. 210. 211. 212. 213. 214. 215. 216. 217. 218. 219. 220. 221. 222. 223.] [224. 225. 226. 227. 228. 229. 230. 231. 232. 233. 234. 235. 236. 237. 238. 239.] [240. 241. 242. 243. 244. 245. 246. 247. 248. 249. 250. 251. 252. 253. 254. 255.]] 输出数据(dstGm): [[ 0. 16. 32. 48. 64. 80. 96. 112. 128. 144. 160. 176. 192. 208. 224. 240.] [ 1. 17. 33. 49. 65. 81. 97. 113. 129. 145. 161. 177. 193. 209. 225. 241.] [ 2. 18. 34. 50. 66. 82. 98. 114. 130. 146. 162. 178. 194. 210. 226. 242.] [ 3. 19. 35. 51. 67. 83. 99. 115. 131. 147. 163. 179. 195. 211. 227. 243.] [ 4. 20. 36. 52. 68. 84. 100. 116. 132. 148. 164. 180. 196. 212. 228. 244.] [ 5. 21. 37. 53. 69. 85. 101. 117. 133. 149. 165. 181. 197. 213. 229. 245.] [ 6. 22. 38. 54. 70. 86. 102. 118. 134. 150. 166. 182. 198. 214. 230. 246.] [ 7. 23. 39. 55. 71. 87. 103. 119. 135. 151. 167. 183. 199. 215. 231. 247.] [ 8. 24. 40. 56. 72. 88. 104. 120. 136. 152. 168. 184. 200. 216. 232. 248.] [ 9. 25. 41. 57. 73. 89. 105. 121. 137. 153. 169. 185. 201. 217. 233. 249.] [ 10. 26. 42. 58. 74. 90. 106. 122. 138. 154. 170. 186. 202. 218. 234. 250.] [ 11. 27. 43. 59. 75. 91. 107. 123. 139. 155. 171. 187. 203. 219. 235. 251.] [ 12. 28. 44. 60. 76. 92. 108. 124. 140. 156. 172. 188. 204. 220. 236. 252.] [ 13. 29. 45. 61. 77. 93. 109. 125. 141. 157. 173. 189. 205. 221. 237. 253.] [ 14. 30. 46. 62. 78. 94. 110. 126. 142. 158. 174. 190. 206. 222. 238. 254.] [ 15. 31. 47. 63. 79. 95. 111. 127. 143. 159. 175. 191. 207. 223. 239. 255.]]
- 用于二维矩阵数据块的转置的int32_t(32bit位)调用示例
#include "kernel_operator.h" namespace AscendC { class KernelTransDataTo5HD { public: __aicore__ inline KernelTransDataTo5HD() {} __aicore__ inline void Init(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { srcGlobal.SetGlobalBuffer((__gm__ int32_t *)src); dstGlobal.SetGlobalBuffer((__gm__ int32_t *)dstGm); pipe.InitBuffer(inQueueSrc, 1, srcDataSize * sizeof(int32_t)); pipe.InitBuffer(workQueueSrc1, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(workQueueSrc2, 1, 16 * sizeof(uint64_t)); pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(int32_t)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { LocalTensor<int32_t> srcLocal = inQueueSrc.AllocTensor<int32_t>(); DataCopy(srcLocal, srcGlobal, srcDataSize); inQueueSrc.EnQue(srcLocal); } __aicore__ inline void Compute() { LocalTensor<int32_t> srcLocal = inQueueSrc.DeQue<int32_t>(); LocalTensor<int32_t> dstLocal = outQueueDst.AllocTensor<int32_t>(); TransDataTo5HDParams transDataParams; transDataParams.dstHighHalf = false; transDataParams.srcHighHalf = false; transDataParams.repeatTimes = 1; transDataParams.dstRepStride = 0; transDataParams.srcRepStride = 0; // 入参类型是LocalTensor的调用方式 LocalTensor<int8_t> dstLocalList[16]; for (int i = 0; i < 16; i++) { dstLocalList[i] = dstLocal[width * i]; } LocalTensor<int8_t> srcLocalList[16]; for (int i = 0; i < 16; i++) { srcLocalList[i] = srcLocal[width * i]; } TransDataTo5HD(dstLocalList, srcLocalList, transDataParams); // 入参类型是LocalTensor地址值的调用方式 // uint64_t dstLocalList[16]; // for (int i = 0; i < 16; i++) { // dstLocalList[i] = (uint64_t)(dstLocal[width * i].GetPhyAddr()); // } // uint64_t srcLocalList[16]; // for (int i = 0; i < 16; i++) { // srcLocalList[i] = (uint64_t)(srcLocal[width * i].GetPhyAddr()); // } // TransDataTo5HD<int32_t>(dstLocalList, srcLocalList, transDataParams); // 入参类型是地址LocalTensor的调用方式 // LocalTensor<uint64_t> dst = workQueueSrc1.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // dst.SetValue(i, (uint64_t)(dstLocal[width * i].GetPhyAddr())); // } // LocalTensor<uint64_t> src = workQueueSrc2.AllocTensor<uint64_t>(); // for (int i = 0; i < 16; i++) { // src.SetValue(i, (uint64_t)(srcLocal[width * i].GetPhyAddr())); // } // TransDataTo5HD<int32_t>(dst, src, transDataParams); // workQueueSrc1.FreeTensor(dst); // workQueueSrc2.FreeTensor(src); outQueueDst.EnQue<int32_t>(dstLocal); inQueueSrc.FreeTensor(srcLocal); } __aicore__ inline void CopyOut() { LocalTensor<int32_t> dstLocal = outQueueDst.DeQue<int32_t>(); DataCopy(dstGlobal, dstLocal, dstDataSize); outQueueDst.FreeTensor(dstLocal); } private: TPipe pipe; TQue<QuePosition::VECIN, 1> inQueueSrc; TQue<QuePosition::VECIN, 1> workQueueSrc1; TQue<QuePosition::VECIN, 1> workQueueSrc2; TQue<QuePosition::VECOUT, 1> outQueueDst; GlobalTensor<int32_t> srcGlobal, dstGlobal; int srcDataSize = 128; int dstDataSize = 128; int width = 8; }; } // namespace AscendC extern "C" __global__ __aicore__ void trans5hd_simple_kernel(__gm__ uint8_t *src, __gm__ uint8_t *dstGm) { AscendC::KernelTransDataTo5HD op; op.Init(src, dstGm); op.Process(); } 输入数据(src): [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127] 输出数据(dstGm): [0 8 16 24 32 40 48 56 64 72 80 88 96 104 112 120 1 9 17 25 33 41 49 57 65 73 81 89 97 105 113 121 2 10 18 26 34 42 50 58 66 74 82 90 98 106 114 122 3 11 19 27 35 43 51 59 67 75 83 91 99 107 115 123 4 12 20 28 36 44 52 60 68 76 84 92 100 108 116 124 5 13 21 29 37 45 53 61 69 77 85 93 101 109 117 125 6 14 22 30 38 46 54 62 70 78 86 94 102 110 118 126 7 15 23 31 39 47 55 63 71 79 87 95 103 111 119 127]
