Mmad
功能说明
完成矩阵乘加操作。
函数原型
- 不支持传入biasLocal
template <typename DstT, typename Src0T, typename Src1T> void Mmad(const LocalTensor<DstT>& dstLocal, const LocalTensor<Src0T>& fmLocal, const LocalTensor<Src1T>& filterLocal, const MmadParams& mmadParams)
- 支持传入biasLocal
template <typename DstT, typename Src0T, typename Src1T, typename BiasT> __aicore__ inline void Mmad(const LocalTensor<DstT>& dstLocal, const LocalTensor<Src0T>& fmLocal, const LocalTensor<Src1T>& filterLocal, const LocalTensor<BiasT>& biasLocal, const MmadParams& mmadParams)
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
dstLocal |
输出 |
目的操作数,结果矩阵,类型为LocalTensor,支持的TPosition为CO1。 |
fmLocal |
输入 |
源操作数,左矩阵a,类型为LocalTensor,支持的TPosition为A2。 |
filterLocal |
输入 |
源操作数,右矩阵b,类型为LocalTensor,支持的TPosition为B2。 |
biasLocal |
输入 |
源操作数,bias矩阵,类型为LocalTensor,支持的TPosition为C2、CO1。 |
mmadParams |
输入 |
矩阵乘相关参数,类型为MmadParams,结构体具体定义为: struct MmadParams
{
uint16_t m;
uint16_t n;
uint16_t k;
bool isBias;
int32_t fmOffset;
bool enSsparse;
bool enWinogradA;
bool enWinogradB;
uint8_t unitFlag;
bool cmatrixInitVal;
bool cmatrixSource;
}; 参数说明请参考表2。 |
参数名称 |
含义 |
|---|---|
m |
左矩阵Height,取值范围:m∈[0, 4095] 。默认值为0。 |
n |
右矩阵Width,取值范围:n∈[0, 4095] 。默认值为0。 |
k |
左矩阵Width、右矩阵Height,取值范围:k∈[0, 4095] 。默认值为0。 |
fmOffset |
预留参数,用户无需关心,使用默认值0即可。 |
enSsparse |
预留参数,用户无需关心,使用默认值false即可。 |
enWinogradA |
预留参数,用户无需关心,使用默认值false即可。 |
enWinogradB |
预留参数,用户无需关心,使用默认值false即可。 |
unitFlag |
预留参数,用户无需关心,使用默认值0即可。 |
cmatrixInitVal |
配置C矩阵初始值是否为0。默认值true。
|
cmatrixSource |
配置C矩阵初始值是否来源于C2(存放Bias的硬件缓存区)。默认值为false。
Atlas 训练系列产品,仅支持配置为false。 Atlas推理系列产品AI Core,仅支持配置为false。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持配置为true/false。 注意:带biasLocal输入的接口配置该参数无效,会根据biasLocal输入的位置来判断C矩阵初始值是否来源于CO1还是C2。 |
isBias |
该参数废弃,新开发内容不要使用该参数。如果需要累加初始矩阵,请使用带biasLocal的接口来实现;也可以通过cmatrixInitVal和cmatrixSource参数配置C矩阵的初始值来源来实现。推荐使用带biasLocal的接口,相比于配置cmatrixInitVal和cmatrixSource参数更加简单方便。 配置是否需要累加初始矩阵,默认值为false,取值说明如下:
|
左矩阵fmLocal type |
右矩阵filterLocal type |
结果矩阵dstLocal type |
|---|---|---|
uint8_t |
uint8_t |
uint32_t |
int8_t |
int8_t |
int32_t |
uint8_t |
int8_t |
int32_t |
uint8_t |
uint8_t |
int32_t |
half |
half |
half
说明:
该精度类型组合,精度无法达到双千分之一,且后续处理器版本不支持该类型转换,建议直接使用half输入float输出。 |
half |
half |
float |
左矩阵fmLocal type |
右矩阵filterLocal type |
结果矩阵dstLocal type |
|---|---|---|
int8_t |
int8_t |
int32_t |
half |
half |
float |
float |
float |
float |
bf16 |
bf16 |
float |
int4b_t |
int4b_t |
int32_t |
左矩阵fmLocal type |
右矩阵filterLocal type |
biasLocal type |
结果矩阵dstLocal type |
|---|---|---|---|
int8_t |
int8_t |
int32_t |
int32_t |
half |
half |
float |
float |
float |
float |
float |
float |
bf16 |
bf16 |
float |
float |
注意事项
- dstLocal只支持位于CO1,fmLocal只支持位于A2,filterLocal只支持位于B2。
- 操作数地址偏移对齐要求请参见通用约束。
数据格式说明
Mmad 函数对于输入数据的格式要求和输出数据的要求如下图,矩阵 ABC 分别为 A2/B2/CO1 中的数据。下图中每个小方格代表一个 512Byte 的分形矩阵。下图中Z字形的黑色线条代表对应位置数据在昇腾AI处理器上的排列顺序,起始点是左上角,终点是右下角。
矩阵A:每个分形矩阵内部是行主序,分形矩阵之间是行主序。简称小Z大Z格式。其shape为16 x (32B/sizeof(AType))。
矩阵B:每个分形矩阵内部是列主序,分形矩阵之间是行主序。简称小N大Z格式。其shape为 (32B/sizeof(BType)) x 16。
矩阵C:每个分形矩阵内部是行主序,分形矩阵之间是列主序。简称小Z大N格式。其shape为16 x 16。
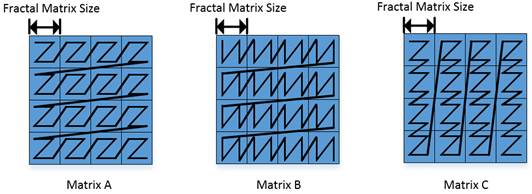
以下是一个简单的例子,假设分形矩阵的大小是2x2,然后矩阵ABC的大小都是4x4
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
对于一个C风格的矩阵来说内部元素的排列顺序应该是0,1,2…15。
矩阵A的排列顺序:0,1,4,5,2,3,6,7,8,9,12,13,10,11,14,15
矩阵B的排列顺序:0,4,1,5,2,6,3,7,8,12,9,13,10,14,11,15
矩阵C的排列顺序:0,1,4,5,8,9,12,13,2,3,6,7,10,11,14,15
以下是一个具体的例子,数据为half类型。
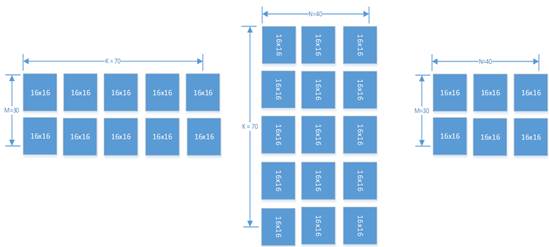
如图,当 M=30,K=70,N=40 的时候,A2 中应该有 2x5 个 16x16 矩阵,B2 中应该有 5x3 个16x16 矩阵,CO1 中应该有 2x3 个 16x16 矩阵。在这种场景下 M、K 和 N 都不是 16 的倍数,A2 中右下角的矩阵实际有效的数据只有 14x6 个,但是也需要占一个 16x16 矩阵的空间,其他无效数据在计算中会被忽略。
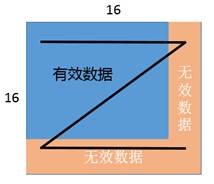
一个 16x16 分形的数据块中,无效数据与有效数据排布的方式示意如下:
支持的型号
调用示例
/*
* Copyright (c) Huawei Technologies Co., Ltd. 2022-2023. All rights reserved.
*
* Function : c = a * b (matrix multiplication)
* This sample is a very basic sample that implements Matmul on Ascend plaform.
* In this sample:
* Shape of matrix a is [m, k]: [32, 32]
* Shape of matrix b is [k, n]: [32, 32]
* Shape of matrix c is [m, n]: [32, 32]
*/
#include "kernel_operator.h"
using namespace AscendC;
class KernelMatmul {
public:
__aicore__ inline KernelMatmul()
{
aSize = m * k;
bSize = k * n;
cSize = m * n;
mBlocks = m / 16;
nBlocks = n / 16;
kBlocks = k / 16;
}
__aicore__ inline void Init(GM_ADDR a, GM_ADDR b, GM_ADDR c)
{
aGM.SetGlobalBuffer((__gm__ half*)a);
bGM.SetGlobalBuffer((__gm__ half*)b);
cGM.SetGlobalBuffer((__gm__ float*)c);
pipe.InitBuffer(inQueueA1, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueA2, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueB1, 1, bSize * sizeof(half));
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half) / 2);
pipe.InitBuffer(outQueueCO1, 2, cSize * sizeof(float) / 2);
pipe.InitBuffer(outQueueCO2, 1, cSize * sizeof(float));
}
__aicore__ inline void Process()
{
CopyIn();
SplitA();
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<float> c2Local = outQueueCO2.AllocTensor<float>();
// split matrix b into 2 parts, [32, 16] and [32, 16]
for (int i = 0; i < 2; ++i) {
SplitB(b1Local, i);
Compute(a2Local);
Aggregate(c2Local, i);
}
inQueueB1.FreeTensor(b1Local);
inQueueA2.FreeTensor(a2Local);
outQueueCO2.EnQue<float>(c2Local);
CopyOut();
}
private:
__aicore__ inline void CopyND2NZ(const LocalTensor<half>& dst, const GlobalTensor<half>& src, const uint16_t height,
const uint16_t width)
{
for (int i = 0; i < width / 16; ++i) {
int srcOffset = i * 16;
int dstOffset = i * 16 * height;
DataCopy(dst[dstOffset], src[srcOffset], { height, 1, uint16_t(width / 16 - 1), 0 });
}
}
__aicore__ inline void CopyIn()
{
LocalTensor<half> a1Local = inQueueA1.AllocTensor<half>();
LocalTensor<half> b1Local = inQueueB1.AllocTensor<half>();
CopyND2NZ(a1Local, aGM, m, k);
CopyND2NZ(b1Local, bGM, k, n);
inQueueA1.EnQue(a1Local);
inQueueB1.EnQue(b1Local);
}
__aicore__ inline void SplitA()
{
int srcOffset = 0;
int dstOffset = 0;
LocalTensor<half> a1Local = inQueueA1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>();
// transform nz to zz
for (int i = 0; i < mBlocks; ++i) {
LoadData2DParams loadDataParams;
loadDataParams.repeatTimes = kBlocks;
loadDataParams.srcStride = mBlocks;
loadDataParams.ifTranspose = false;
LoadData(a2Local[dstOffset], a1Local[srcOffset], loadDataParams);
srcOffset += 16 * 16;
dstOffset += k * 16;
}
inQueueA2.EnQue<half>(a2Local);
inQueueA1.FreeTensor(a1Local);
}
__aicore__ inline void SplitB(const LocalTensor<half>& b1Local, const int bSplitIdx)
{
LocalTensor<half> b2Local = inQueueB2.AllocTensor<half>();
// transform nz to zn
LoadData2DParams loadDataParams;
loadDataParams.repeatTimes = kBlocks;
loadDataParams.srcStride = 1;
loadDataParams.ifTranspose = true;
LoadData(b2Local, b1Local[bSplitIdx * bSize / 2], loadDataParams);
inQueueB2.EnQue<half>(b2Local);
}
__aicore__ inline void Compute(const LocalTensor<half>& a2Local)
{
LocalTensor<half> b2Local = inQueueB2.DeQue<half>();
LocalTensor<float> c1Local = outQueueCO1.AllocTensor<float>();
Mmad(c1Local, a2Local, b2Local, { m, uint16_t(n / 2), k, 0, false, true });
outQueueCO1.EnQue<float>(c1Local);
inQueueB2.FreeTensor(b2Local);
}
__aicore__ inline void Aggregate(const LocalTensor<float>& c2Local, const int bSplitIdx)
{
LocalTensor<float> c1Local = outQueueCO1.DeQue<float>();
DataCopyParams dataCopyParams;
dataCopyParams.blockCount = 1;
dataCopyParams.blockLen = 2;
DataCopyEnhancedParams enhancedParams;
enhancedParams.blockMode = BlockMode::BLOCK_MODE_MATRIX;
DataCopy(c2Local[bSplitIdx * cSize / 2], c1Local, dataCopyParams, enhancedParams);
outQueueCO1.FreeTensor(c1Local);
}
__aicore__ inline void CopyOut()
{
LocalTensor<float> c2Local = outQueueCO2.DeQue<float>();
// transform nz to nd
for (int i = 0; i < nBlocks; ++i) {
DataCopy(cGM[i * 16], c2Local[i * m * 16], { m, 2, 0, uint16_t((nBlocks - 1) * 2) });
}
outQueueCO2.FreeTensor(c2Local);
}
private:
TPipe pipe;
TQue<QuePosition::A1, 1> inQueueA1;
TQue<QuePosition::A2, 1> inQueueA2;
TQue<QuePosition::B1, 1> inQueueB1;
TQue<QuePosition::B2, 2> inQueueB2;
// dst queue
TQue<QuePosition::CO1, 2> outQueueCO1;
TQue<QuePosition::CO2, 1> outQueueCO2;
GlobalTensor<half> aGM, bGM;
GlobalTensor<float> cGM;
uint16_t m = 32;
uint16_t n = 32;
uint16_t k = 32;
uint16_t aSize, bSize, cSize, mBlocks, nBlocks, kBlocks;
};
extern "C" __global__ __aicore__ void matmul_custom(GM_ADDR a, GM_ADDR b, GM_ADDR c)
{
KernelMatmul op;
op.Init(a, b, c);
op.Process();
}
#ifndef ASCENDC_CPU_DEBUG
// call of kernel function
void matmul_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* a, uint8_t* b, uint8_t* c)
{
matmul_custom<<<blockDim, l2ctrl, stream>>>(a, b, c);
}
#endif
#include "kernel_operator.h"
using namespace AscendC;
class KernelMatmul {
public:
__aicore__ inline KernelMatmul()
{
aSize = m * k;
bSize = k * n;
cSize = m * n;
}
__aicore__ inline void Init(__gm__ uint8_t *a, __gm__ uint8_t *b, __gm__ uint8_t *bias, __gm__ uint8_t *c)
{
aGM.SetGlobalBuffer((__gm__ half *)a);
bGM.SetGlobalBuffer((__gm__ half *)b);
cGM.SetGlobalBuffer((__gm__ float *)c);
biasGM.SetGlobalBuffer((__gm__ half *)bias);
pipe.InitBuffer(inQueueA1, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueA2, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueB1, 1, bSize * sizeof(half));
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half));
pipe.InitBuffer(outQueueCO1, 1, cSize * sizeof(float));
pipe.InitBuffer(inQueueC1, 1, n * sizeof(half));
pipe.InitBuffer(outQueueC2, 1, n * sizeof(float));
}
__aicore__ inline void Process()
{
CopyIn();
SplitA();
SplitB();
SplitBias();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<half> a1Local = inQueueA1.AllocTensor<half>();
LocalTensor<half> b1Local = inQueueB1.AllocTensor<half>();
LocalTensor<half> bias1Local = inQueueC1.AllocTensor<half>();
DataCopy(a1Local, aGM, aSize);
DataCopy(b1Local, bGM, bSize);
DataCopy(bias1Local, biasGM, n);
inQueueA1.EnQue(a1Local);
inQueueB1.EnQue(b1Local);
inQueueC1.EnQue(bias1Local);
}
__aicore__ inline void SplitA()
{
LocalTensor<half> a1Local = inQueueA1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>();
LoadData2DParams loadL0AParams;
loadL0AParams.repeatTimes = 1;
loadL0AParams.srcStride = 1;
LoadData(a2Local, a1Local, loadL0AParams);
inQueueA2.EnQue<half>(a2Local);
inQueueA1.FreeTensor(a1Local);
}
__aicore__ inline void SplitB()
{
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.AllocTensor<half>();
LoadData2DParams loadL0BParams;
loadL0BParams.repeatTimes = 1;
loadL0BParams.srcStride = 1;
loadL0BParams.ifTranspose = true;
LoadData(b2Local, b1Local, loadL0BParams);
inQueueB1.FreeTensor(b1Local);
inQueueB2.EnQue<half>(b2Local);
}
__aicore__ inline void SplitBias()
{
LocalTensor<half> bias1Local = inQueueC1.DeQue<half>();
LocalTensor<float> bias2Local = outQueueC2.AllocTensor<float>();
DataCopy(bias2Local, bias1Local, { 1, (uint16_t)(n * sizeof(float) / 64), 0, 0 });
outQueueC2.EnQue<float>(bias2Local);
inQueueC1.FreeTensor(bias1Local);
}
__aicore__ inline void Compute()
{
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.DeQue<half>();
LocalTensor<float> bias2Local = outQueueC2.DeQue<float>();
LocalTensor<float> c1Local = outQueueCO1.AllocTensor<float>();
MmadParams mmadParams;
mmadParams.m = m;
mmadParams.n = n;
mmadParams.k = k;
mmadParams.cmatrixInitVal = false;
Mmad(c1Local, a2Local, b2Local, bias2Local, mmadParams);
outQueueCO1.EnQue<float>(c1Local);
inQueueA2.FreeTensor(a2Local);
inQueueB2.FreeTensor(b2Local);
outQueueC2.FreeTensor(bias2Local);
}
__aicore__ inline void CopyOut()
{
LocalTensor<float> c1Local = outQueueCO1.DeQue<float>();
FixpipeParamsV220 fixpipeParams;
fixpipeParams.nSize = n;
fixpipeParams.mSize = m;
fixpipeParams.srcStride = m;
fixpipeParams.dstStride = n;
fixpipeParams.ndNum = 1;
fixpipeParams.srcNdStride = 0;
fixpipeParams.dstNdStride = 0;
Fixpipe(cGM, c1Local, fixpipeParams);
outQueueCO1.FreeTensor(c1Local);
}
private:
TPipe pipe;
TQue<QuePosition::A1, 1> inQueueA1;
TQue<QuePosition::A2, 1> inQueueA2;
TQue<QuePosition::B1, 1> inQueueB1;
TQue<QuePosition::B2, 1> inQueueB2;
TQue<QuePosition::CO1, 1> outQueueCO1;
TQue<QuePosition::C1, 1> inQueueC1;
TQue<QuePosition::C2, 1> outQueueC2;
GlobalTensor<half> aGM;
GlobalTensor<half> bGM;
GlobalTensor<float> cGM;
GlobalTensor<half> biasGM;
uint16_t m = 16, k = 16, n = 16;
uint16_t aSize, bSize, cSize;
};
extern "C" __global__ __aicore__ void matmul_custom(GM_ADDR a, GM_ADDR b, GM_ADDR bias, GM_ADDR c)
{
KernelMatmul op;
op.Init(a, b, bias, c);
op.Process();
}
#ifndef ASCENDC_CPU_DEBUG
// call of kernel function
void matmul_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* a, uint8_t* b, uint8_t* bias, uint8_t* c)
{
matmul_custom<<<blockDim, l2ctrl, stream>>>(a, b, bias, c);
}
#endif
