均匀量化
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的FP32数据或16比特的FP16数据,将FP32/FP16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行基于精度的自动量化或量化感知训练或手工调优。
均匀量化支持量化的层以及约束如下,量化示例请参见获取更多样例。
量化方式 |
支持的层类型 |
约束 |
备注 |
|---|---|---|---|
均匀量化 |
MatMul |
transpose_a=False, transpose_b=False,adjoint_a=False,adjoint_b=False |
- |
BatchMatMul/BatchMatMulV2 |
adj_x=False |
||
Conv2D |
- |
weight的输入来源不含有placeholder等可动态变化的节点,且weight的节点类型只能是const。 |
|
Conv3D |
dilation_d为1,dilation_h/dilation_w >= 1 |
||
DepthwiseConv2dNative |
- |
||
Conv2DBackpropInput |
dilation为1 |
||
AvgPool |
- |
- |
|
MaxPool |
只做tensor量化 |
- |
|
Add |
只做tensor量化 |
- |
接口调用流程
均匀量化接口调用流程如图1所示。
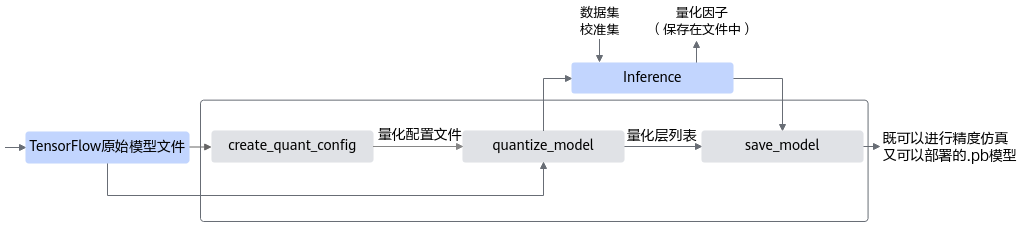
- 用户首先构造TensorFlow的原始模型,然后使用create_quant_config接口生成量化配置文件。
- 根据TensorFlow模型和量化配置文件,即可调用quantize_model接口对原始TensorFlow模型进行优化,修改后的模型中插入数据量化、权重量化等相关算子,用于计算量化相关参数。
- 用户使用2输出的修改后的模型,借助AMCT提供的数据集和校准集,在TensorFlow环境中进行inference,可以得到量化因子。
其中数据集用于在TensorFlow环境中对模型进行推理时,测试量化数据的精度;校准集用来产生量化因子,保证精度。
- 最后用户可以调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型,该模型既可在TensorFlow环境中进行精度仿真又可以在昇腾AI处理器部署。
调用示例
本章节详细给出训练后量化的模板代码解析说明,通过解读该代码,用户可以详细了解AMCT的工作流程以及原理,方便用户基于已有模板代码进行修改,以便适配其他网络模型的量化。
用户可以参见mobilenet_v2获取本章节的sample示例代码。训练后量化主要包括如下几个步骤:
- 准备训练好的模型和数据集。
- 在原始TensorFlow环境中验证模型精度以及环境是否正常。
- 编写训练后量化脚本调用AMCTAPI。
- 执行训练后量化脚本。
- 在原始TensorFlow环境中验证量化后仿真模型精度。
如下流程详细演示如何编写脚本调用AMCTAPI进行模型量化。

- 如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
- 如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
- 导入AMCT包,设置日志级别。
1 2
import amct_tensorflow as amct amct.set_logging_level(print_level='info', save_level='info')
- (可选,由用户补充处理)在TensorFlow原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在TensorFlow环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
1user_do_inference(ori_model, test_data, test_iterations)
- (由用户补充处理)根据模型user_model.pb,准备好图结构tf.Graph。
1ori_graph = user_load_graph()
- 调用AMCT,量化模型。
- 生成量化配置。
1 2 3 4 5 6 7
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, graph=ori_graph, skip_layers=skip_layers, batch_num=batch_num)
- 修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
1 2 3 4
record_file = './tmp/record.txt' amct.quantize_model(graph=ori_graph, config_file=config_file, record_file=record_file)
使用AMCT调用quantize_model接口对用户的原始TensorFlow模型进行图修改时,由于插入了searchN层导致尾层输出节点发生改变的场景,可以参见TensorFlow网络模型由于AMCT导致输出节点改变,如何通过修改量化脚本进行后续的量化动作进行处理。如果量化过程存在空tensor输入报错信息,请参见使用训练后量化进行量化时,量化过程存在空tensor输入报错信息进行处理。
- (由用户补充处理)使用修改后的图在校准集上做模型推理,找到量化因子。
- 校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
- 前向推理的次数为batch_num,如果次数不够,后续过程会失败。
1user_do_inference(ori_graph, calibration_data, batch_num)
若校准时提示“Invalid argument: You must feed a value for placeholder tensor **”,请参见校准时提示“Invalid argument: You must feed a value for placeholder tensor **”进行处理。
若校准过程中如果提示“xxx calculate scale failed”错误信息,请参见IFMR数据量化时,存在"inf或NaN值"或"xxx calculate scale failed",量化过程报错。
- 保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
1 2 3 4 5
quant_model_path = './results/user_model' amct.save_model(pb_model='user_model.pb', outputs=['user_model_outputs0', 'user_model_outputs1'], record_file=record_file, save_path=quant_model_path)
保存模型时提示“RuntimeError: cannot find shift_bit of layer ** in record_file”,则请参见保存模型时提示“RuntimeError: record_file is empty, no layers to be quantized”进行处理。
- 生成量化配置。
- (可选,由用户补充处理)使用量化后模型user_model_quantized.pb和测试集(test_data),在TensorFlow环境下推理,测试量化后的仿真模型精度。使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
1 2
quant_model = './results/user_model_quantized.pb' user_do_inference(quant_model, test_data, test_iterations)