DataFlow简介
读者对象
本文档用于指导开发者如何使用DataFlow接口进行计算图的构建、修改、编译和执行。通过本文档您可以达成以下目标:
- 了解构建FlowGraph的方法。
- 掌握运行FlowGraph的方法。
- 了解UDF开发过程及相关接口。
熟悉CANN软件基本架构以及特性、具备Python语言程序开发能力,对机器学习、深度学习有一定了解的人员,可以更好地理解本文档。
DataFlow概述
DataFlow用于描述采用数据队列以数据驱动方式将一个或多个计算处理点(ProcessPoint)组织成完整的计算流。ProcessPoint采用异步方式处理,这是与算子的关键区别。DataFlow通过FlowGraph来承载,ProcessPoint通过FlowNode来承载,各个接口之间的关系如下所示。
图1 DataFlow相关接口之间的关系
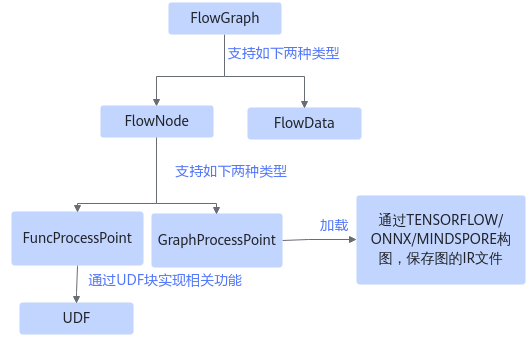
- FlowGraph:DataFlow的Graph,由输入节点FlowData和计算节点FlowNode构成。
- FlowData:FlowGraph的输入节点。
- FlowNode:FlowGraph的计算节点。支持如下两种类型。
- FuncProcessPoint:Func的计算处理点,通过UDF开发(User Define FlowFunction)实现用户自定义功能。
- GraphProcessPoint:Graph的计算处理点,通过IR构图实现用户的计算逻辑。
DataFlow支持用户通过FuncProcessPoint和GraphProcessPoint编写自定义处理函数,通过DataFlow构图以flowModel的方式运行。
DataFlow和IR构图的不同点如下所示。
维度 |
图 |
Dataflow |
|---|---|---|
数据流处理方式 |
|
|
自定义功能开发方式 |
通过开发自定义算子实现。 算子包括算子原型定义、算子代码实现、算子信息库定义、算子适配等过程,需要用户开发的交付件多,使用门槛相对较高。 |
可以通过开发UDF实现,也可以通过开发自定义算子实现。 UDF开发只需要定义用户函数,构建图。用户交付件少,使用门槛低。 |
内存分配方式 |
算子的输入内存、输出内存是已经申请好的。 |
UDF输出内存是用户自定义的,需要用户自己申请。 |
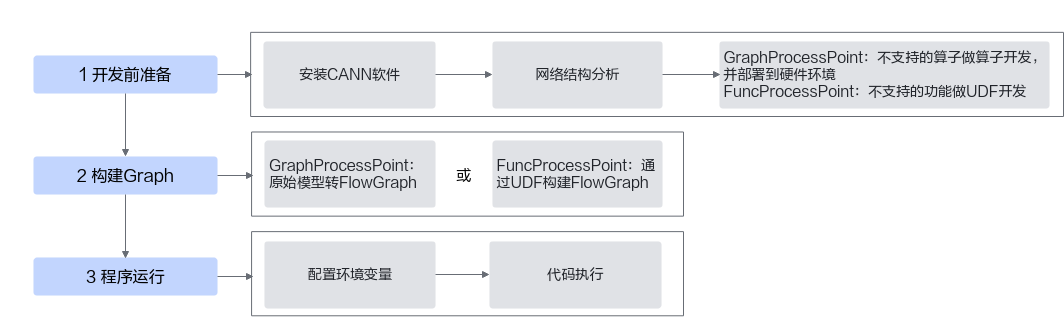
整体开发流程
约束
无论是在host侧还是device侧,FuncProcessPoint和GraphProcessPoint中执行的模型不应该对其输入的数据直接进行修改。在同一份输入数据多个节点使用场景,由于同一份输入只存储一份,某个节点直接进行修改可能会导致其他节点使用该输入数据时产生位置错误。