基本架构
如下图所示,基于Ascend C开发的算子运行在AI Core上,对于初学者需要对硬件架构有基本认识,下文的编程模型基于硬件架构的抽象进行介绍,了解该内容能够更好的理解编程模型;对于需要完成高性能编程的深度开发者,更需要了解硬件架构相关知识,最佳实践中很多内容都以本章为基础进行介绍。
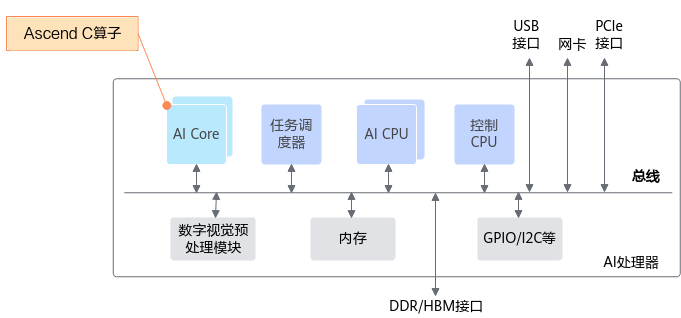
AI Core负责执行标量、向量和张量相关的计算密集型算子,包括三种基础计算单元:Cube(矩阵)计算单元、Vector(向量)计算单元和Scalar(标量)计算单元,同时还包含存储单元(包括硬件存储和用于数据搬运的搬运单元)和控制单元。硬件架构根据Cube计算单元和Vector计算单元是否同核部署分为耦合架构和分离架构两种。如下产品型号对应的处理器架构模式如下:
- Atlas 推理系列产品:耦合架构
- Atlas 训练系列产品:耦合架构
- Atlas A2训练系列产品/Atlas 800I A2推理产品:分离架构
- Atlas 200/500 A2推理产品:耦合架构
耦合架构
耦合架构是指Cube计算单元和Vector计算单元同核部署,架构图如下图所示。下图中列出了计算架构中的存储单元和计算单元,箭头表示数据处理流向,MTE1/MTE2/MTE3代表搬运单元。
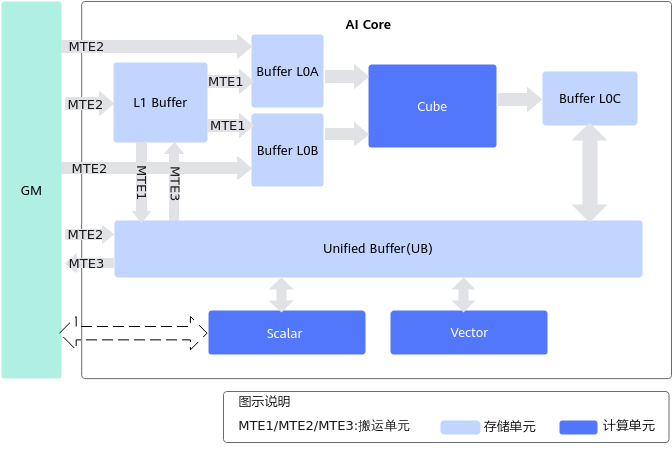
注:图中的虚线箭头表明
- Atlas 训练系列产品:不支持Scalar直接读写GM数据。
- Atlas 推理系列产品:支持Scalar直接读写GM数据。
分离架构
如下图所示,分离架构将AI Core拆成矩阵计算(AI Cube,AIC)和向量计算(AI Vector,AIV)两个独立的核,每个核都有自己的Scalar单元,能独立加载自己的代码段,从而实现矩阵计算与向量计算的解耦,在系统软件的统一调度下互相配合达到计算效率优化的效果。AIV与AIC之间通过Global Memory进行数据传递,比耦合架构增加了两个Buffer:BT Buffer(BiasTable Buffer,存放Bias)和FP Buffer(Fixpipe Buffer,存放量化参数、Relu参数等)。
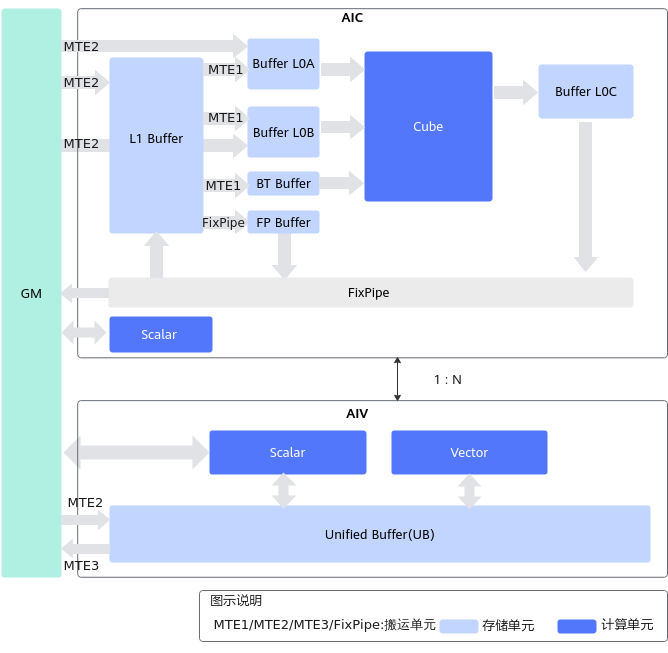
- AIC架构
- 包含5个并行执行单元(搬运单元和计算单元):MTE1,MTE2,MTE3,Cube,Scalar
- 包含7个内存单元:GM(核外),L1,L0A,L0B,L0C,BiasTable Buffer,Fixpipe Buffer
- AIV架构
- 包含4个并行执行单元:MTE2,MTE3,Vector,Scalar
- 包含2个内存单元:GM(核外),UB
- 典型计算数据流
- Vector计算:GM-UB- [Vector]-UB-GM
- Cube计算:
- GM-L1-L0A/L0B-Cube-L0C-FixPipe-GM
- GM-L1-L0A/L0B-Cube-L0C-FixPipe-L1
父主题: 硬件架构