Host侧tiling实现
在算子实现章节已经介绍了host侧tiling核心的实现方法,本章节侧重于介绍接入CANN框架时编程模式和API的使用。
大多数情况下,Local Memory的存储,无法完整的容纳算子的输入与输出,需要每次搬运一部分输入进行计算然后搬出,再搬运下一部分输入进行计算,直到得到完整的最终结果,这个数据切分、分块计算的过程称之为Tiling。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序,称之为Tiling实现。
Tiling实现完成后,获取到的Tiling切分算法相关参数,会传递给kernel侧,用于指导并行数据的切分。由于Tiling实现中完成的均为标量计算,AI Core并不擅长,所以我们将其独立出来放在host CPU上执行。
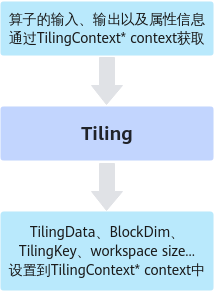
如上图所示,Tiling实现即为根据算子shape等信息来确定切分算法相关参数的过程,这里的算子shape等信息可以理解为是Tiling实现的输入,切分算法相关参数可以理解为是Tiling实现的输出。输入和输出都通过Tiling函数的参数(TilingContext* context上下文结构)来承载。也就是说,开发者可以从上下文结构中获取算子的输入、输出以及属性信息,也就是Tiling实现的输入,经过Tiling计算后,获取到TilingData数据结构(切分算法相关参数)、BlockDim变量、用于选择不同的kernel实现分支的TilingKey、算子workspace的大小,也就是Tiling实现的输出,并将这些输出设置到上下文结构中。
TilingData、BlockDim、TilingKey、workspace这些概念的具体解释如下:
- TilingData:切分算法相关参数,比如每次搬运的块大小,以及总共循环多少次,通过结构体存储,由开发者自行设计。
TilingData结构定义支持单结构定义方法,也支持结构体嵌套:
- 单结构定义方法,以平铺的形式定义:
namespace optiling { BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF(uint32_t, field1); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field2); TILING_DATA_FIELD_DEF(uint32_t, field3); END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 }Tiling实现函数中对tiling结构成员赋值的方式如下:
MyAddTilingData myTiling; myTiling.set_field1(1); myTiling.set_field2(2);
- 支持结构体嵌套:
namespace optiling { TILING_DATA_FIELD_DEF_STRUCT(MyStruct1) // 声明结构1名字 TILING_DATA_FIELD_DEF(uint32_t, field1); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field2); // 结构成员的类型和名字 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyStruct1Op, MyStruct1) // 注册结构体到<op_type>Op TILING_DATA_FIELD_DEF_STRUCT(MyStruct2) // 声明结构2名字 TILING_DATA_FIELD_DEF(uint32_t, field3); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field4); // 结构成员的类型和名字 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyStruct2Op, MyStruct2) // 注册结构体到<op_type>Op BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF(MyStruct1, st1); // 结构成员的引用结构体 TILING_DATA_FIELD_DEF(MyStruct2, st2); // 结构成员的引用结构体 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 }Tiling实现函数中对tiling结构成员赋值的方式如下:
MyAddTilingData myTiling; myTiling.st1.set_field1(1); myTiling.st1.set_field2(2); myTiling.st2.set_field3(3); myTiling.st2.set_field4(4);
- 单结构定义方法,以平铺的形式定义:
- BlockDim:规定了核函数将会在几个核上执行。例如,需要计算8M的数据,每个核上计算1M的数据,BlockDim设置为8,但是为了充分利用硬件资源,一般将BlockDim设置为硬件平台的核数,根据核数进行数据切分。

blockDim是逻辑核的概念,取值范围为[1,65535]。为了充分利用硬件资源,一般设置为物理核的核数或其倍数。对于耦合架构和分离架构,blockDim在运行时的意义和设置规则有一些区别,具体说明如下:
- 耦合架构:由于其Vector、Cube单元是集成在一起的,blockDim用于设置启动多个AICore核实例执行,不区分Vector、Cube。AI Core的核数可以通过GetCoreNumAiv或者GetCoreNumAic获取。
- 分离架构
- 针对仅包含Vector计算的算子,blockDim用于设置启动多少个Vector(AIV)实例执行,比如某款AI处理器上有40个Vector核,建议设置为40。
- 针对仅包含Cube计算的算子,blockDim用于设置启动多少个Cube(AIC)实例执行,比如某款AI处理器上有20个Cube核,建议设置为20。
- 针对Vector/Cube融合计算的算子,启动时,按照AIV和AIC组合启动,blockDim用于设置启动多少个组合执行,比如某款AI处理器上有40个Vector核和20个Cube核,一个组合是2个Vector核和1个Cube核,建议设置为20,此时会启动20个组合,即40个Vector核和20个Cube核。注意:该场景下,设置的blockDim逻辑核的核数不能超过物理核(2个Vector核和1个Cube核组合为1个物理核)的核数。
- AIC/AIV的核数分别通过GetCoreNumAic和GetCoreNumAiv接口获取。
- TilingKey(可选):TilingKey是一个算子内为了区分不同的实现而将kernel代码进行区分的方法,该方法类似于C++的Template模板机制,可减少不必要的icache miss以及scalar耗时,有助于优化单次调用kernel的性能。不同的kernel实现分支可以通过TilingKey来标识,host侧设置TilingKey后,可以选择对应的分支。例如,一个算子在不同的shape下,有不同的算法逻辑,kernel侧可以通过TilingKey来选择不同的算法逻辑,在host侧Tiling算法也有差异,host/kernel侧通过相同的TilingKey进行关联。
假如有如下kernel代码:
if (condition) { ProcessA(); } else { ProcessB(); }如果函数ProcessA、ProcessB两个函数是个非常大的函数,那么上述代码在编译后会变得更大,而每次kernel运行只会选择1个分支,条件的判断和跳转在代码大到一定程度(16-32K,不同芯片存在差异)后会出现icache miss。通过TilingKey可以对这种情况进行优化,给2个kernel的处理函数设置不同的TilingKey 1和2:
if (TILING_KEY_IS(1)) { ProcessA(); } else if (TILING_KEY_IS(2)) { ProcessB(); }这样device kernel编译时会自动识别到2个TilingKey并编译2个kernel入口函数,将条件判断进行常量折叠。同时需要和host tiling函数配合,判断走ProcessA的场景设置TilingKey为1,走ProcessB的场景设置TilingKey为2:
static ge::graphStatus TilingFunc(gert::TilingContext* context) { // some code if (condition) { context->SetTilingKey(1); } else { context->SetTilingKey(2); } return ge::GRAPH_SUCCESS; } - WorkspaceSize(可选):workspace是设备侧Global Memory上的一块内存。在Tiling函数中可以设置workspace的大小,框架侧会为其在申请对应大小的设备侧Global Memory,在对应的算子kernel侧实现时可以使用这块workspace内存。
workspace内存分为两部分:Ascend C API需要的workspace内存和算子实现使用到的workspace内存(按需)。
- AscendC API需要预留workspace内存
API在计算过程需要一些workspace内存作为缓存,因此算子Tiling函数需要为API预留workspace内存,预留内存大小通过GetLibApiWorkSpaceSize接口获取。
- 算子实现使用到的workspace内存(按需)
整体的workspace内存就是上述两部分之和,在Tiling函数中设置方法如下:
auto workspaceSizes = context->GetWorkspaceSizes(1); // 只使用1块workspace workspaceSizes[0] = sysWorkspaceSize + usrWorkspaceSize;
- AscendC API需要预留workspace内存
Tiling实现基本流程
Tiling实现开发的流程图如下:
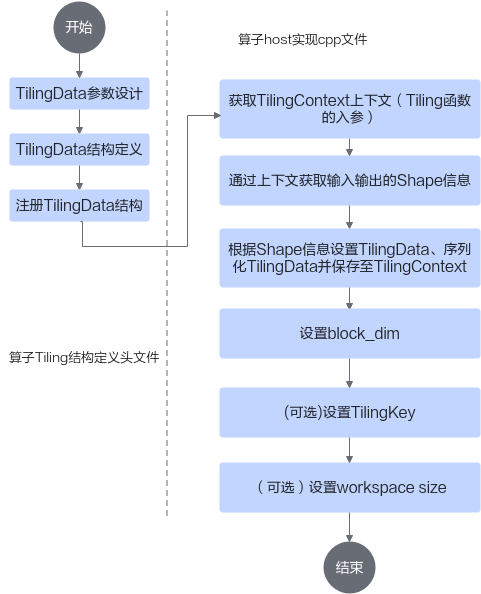
下面将从一个简单的Add算子为例介绍Tiling的实现流程。本样例中待处理数据的Shape大小可以平均分配到每个核上,并且可以对齐到一个data block(32B)的大小。
首先完成算子TilingData结构定义头文件的编写,该文件命名为“算子名称_tiling.h”,位于算子工程的op_host目录下。样例代码如下:
#ifndef ADD_CUSTOM_TILING_H
#define ADD_CUSTOM_TILING_H
#include "register/tilingdata_base.h"
namespace optiling {
BEGIN_TILING_DATA_DEF(TilingData) // 注册一个tiling的类,以tiling的名字作为入参
TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 添加tiling字段,总计算数据量
TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 添加tiling字段,每个核上总计算数据分块个数
END_TILING_DATA_DEF;
// 注册算子tilingdata类到对应的AddCustom算子
REGISTER_TILING_DATA_CLASS(AddCustom, TilingData)
}
#endif // ADD_CUSTOM_TILING_H
具体的编写步骤如下:
- 代码框架编写,需要增加#ifndef...的判断条件,防止头文件的重复包含;需要包含register/tilingdata_base.h头文件,tilingdata_base.h中定义了多个用于tilingdata注册的宏。样例代码如下:
#ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { // tiling结构定义和注册代码 // ... } #endif // ADD_CUSTOM_TILING_H - TilingData参数设计,TilingData参数本质上是和并行数据切分相关的参数,本示例算子使用了2个tiling参数:totalLength、tileNum。totalLength是指需要计算的数据量大小,tileNum是指每个核上总计算数据分块个数。比如,totalLength这个参数传递到kernel侧后,可以通过除以参与计算的核数,得到每个核上的计算量,这样就完成了多核数据的切分。
- TilingData结构定义,通过BEGIN_TILING_DATA_DEF接口定义一个TilingData的类,通过TILING_DATA_FIELD_DEF接口增加TilingData的两个字段totalLength、tileNum,通过END_TILING_DATA_DEF接口结束TilingData定义。相关接口的详细说明请参考TilingData结构定义。
BEGIN_TILING_DATA_DEF(TilingData) // 注册一个tiling的类,以tiling的名字作为入参 TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 添加tiling字段,总计算数据量 TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 添加tiling字段,每个核上总计算数据分块个数 END_TILING_DATA_DEF;
- 注册TilingData结构,通过REGISTER_TILING_DATA_CLASS接口,注册TilingData类,和自定义算子相关联。REGISTER_TILING_DATA_CLASS第一个参数为op_type(算子类型),本样例中传入AddCustom,第二个参数为TilingData的类名。REGISTER_TILING_DATA_CLASS接口介绍请参考TilingData结构注册。
// 注册算子tilingdata类到对应的AddCustom算子 REGISTER_TILING_DATA_CLASS(AddCustom, TilingData)
namespace optiling {
const uint32_t BLOCK_DIM = 8;
const uint32_t TILE_NUM = 8;
static ge::graphStatus TilingFunc(gert::TilingContext *context)
{
TilingData tiling;
uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
context->SetBlockDim(BLOCK_DIM);
tiling.set_totalLength(totalLength);
tiling.set_tileNum(TILE_NUM);
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
size_t *currentWorkspace = context->GetWorkspaceSizes(1);
currentWorkspace[0] = 0;
return ge::GRAPH_SUCCESS;
}
} // namespace optiling
具体步骤如下:
- 获取TilingContext的上下文,即Tiling函数的入参gert::TilingContext* context。
- 设置TilingData。上文3中,定义了TilingData的类,此时可以用TilingData定义一个具体的实例,通过调用TilingData类的set_+field_name接口来设置TilingData的字段值,通过调用TilingData类的SaveToBuffer接口完成TilingData的序列化和保存。
- 通过上下文获取输入输出shape信息。本样例中通过TilingContext的GetInputTensor接口获取输入Tensor,再通过Tensor类的GetShapeSize获取当前Tensor的shape大小。
// 获取输入shape信息 uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
- 设置TilingData。通过调用set_+field_name方法来设置TilingData的字段值。
// 用TilingData定义一个具体的实例 TilingData tiling; // 设置TilingData tiling.set_totalLength(totalLength); tiling.set_tileNum(TILE_NUM);
- 调用TilingData类的SaveToBuffer接口完成序列化并保存至TilingContext上下文。SaveToBuffer的第一个参数为存储Buffer的首地址,第二个参数为Buffer的长度。通过调用GetRawTilingData获取无类型的TilingData的地址,再通过GetData获取数据指针,作为Buffer的首地址;通过调用GetRawTilingData获取无类型的TilingData的地址,再通过GetCapacity获取TilingData的长度,作为Buffer的长度。完成SaveToBuffer操作后需要通过SetDataSize设置TilingData的长度,该长度通过TilingData类的GetDataSize接口获取。
// 序列化并保存 tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
- 通过上下文获取输入输出shape信息。本样例中通过TilingContext的GetInputTensor接口获取输入Tensor,再通过Tensor类的GetShapeSize获取当前Tensor的shape大小。
- 通过SetBlockDim接口设置blockdim。
context->SetBlockDim(BLOCK_DIM);
- (可选)通过SetTilingKey设置TilingKey。
context->SetTilingKey(1);
- (可选)通过GetWorkspaceSizes获取workspace size指针,并设置size大小。此处仅作为举例,设置workspace的大小为0。
size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0;
Tiling参数设计更多样例-属性信息通过TilingData传递
如果算子包含属性信息,该属性信息可以通过TilingData传递到kernel侧,参与kernel侧算子核函数的计算。以ReduceMaxCustom算子为例,该算子用于对输入数据按维度dim返回最大值,并且返回索引。ReduceMaxCustom算子有两个属性,reduceDim和isKeepDim,reduceDim表示按照哪一个维度进行reduce操作;isKeepDim表示是否需要保持输出的维度与输入一样。本样例仅支持对最后一维做reduce操作,输入数据类型为half。
- ReduceMaxCustom算子TilingData的定义如下:这里我们重点关注reduceAxisLen。参数reduceAxisLen表示获取reduceDim轴的长度,这里也就是最后一维的长度。该参数后续会通过TilingData传递到kernel侧参与计算。
#ifndef REDUCE_MAX_CUSTOM_TILING_H #define REDUCE_MAX_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { BEGIN_TILING_DATA_DEF(ReduceMaxTilingData) TILING_DATA_FIELD_DEF(uint32_t, reduceAxisLen); // 添加tiling字段,reduceDim轴的长度 //其他TilingData参数的定义 ... END_TILING_DATA_DEF; // 注册算子tilingdata类到对应的ReduceMaxCustom算子 REGISTER_TILING_DATA_CLASS(ReduceMaxCustom, ReduceMaxTilingData) } #endif // REDUCE_MAX_CUSTOM_TILING_H - ReduceMaxCustom算子的Tiling实现如下。这里我们重点关注属性信息通过TilingData传递的过程:首先通过TilingContext上下文从attr获取reduceDim属性值;然后根据reduceDim属性值获取reduceDim轴的长度并设置到TilingData中。
namespace optiling { static ge::graphStatus TilingFunc(gert::TilingContext* context) { ReduceMaxTilingData tiling; // 从attr获取reduceDim属性值,因为reduceDim是第一个属性,所以GetAttrPointer传入的索引值为0 const gert::RuntimeAttrs* attrs = context->GetAttrs(); const uint32_t* reduceDim = attrs->GetAttrPointer<uint32_t>(0); // 获取reduceDim轴的长度 const gert::StorageShape* xShapePtr = context->GetInputShape(0); const gert::Shape& xShape = xShapePtr->GetStorageShape(); const uint32_t reduceAxisLen = xShape.GetDim(*reduceDim); // 计算TilingData中除了reduceAxisLen之外其他成员变量的值 ... // 将reduceAxisLen设置到tiling结构体中,传递到kernel函数使用 tiling.set_reduceAxisLen(reduceAxisLen); // 设置TilingData中除了reduceAxisLen之外其他成员变量的值 ... // TilingData序列化保存 tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); ... return ge::GRAPH_SUCCESS; }} // namespace optiling
Tiling参数设计更多样例-使用高阶API时配套的Tiling
- 首先进行tiling结构定义:
namespace optiling { BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF_STRUCT(TCubeTiling, cubeTilingData); // 引用高阶API的tiling结构体 TILING_DATA_FIELD_DEF(uint32_t, field); // 结构成员的引用结构体 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 } - 通过高阶API配套的tiling函数对tiling结构初始化:
static ge::graphStatus TilingFunc(gert::TilingContext* context) { int32_t M = 1024; int32_t N = 640; int32_t K = 256; int32_t baseM = 128; int32_t baseN = 128; auto ascendcPlatform = platform_ascendc::PlatformAscendC(context->GetPlatformInfo()); MultiCoreMatmulTiling cubeTiling(ascendcPlatform); cubeTiling.SetDim(2); cubeTiling.SetAType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16); cubeTiling.SetBType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16); cubeTiling.SetCType(TPosition::LCM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT); cubeTiling.SetBiasType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT); cubeTiling.SetShape(M, N, K); cubeTiling.SetOrgShape(M, N, K); cubeTiling.SetFixSplit(baseM, baseN, -1); cubeTiling.SetBias(true); cubeTiling.SetBufferSpace(-1, -1, -1); MyAddTilingData tiling; if (cubeTiling.GetTiling(tiling.cubeTilingData) == -1){ return ge::GRAPH_FAILED; } // some code }