'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
double buffer
执行于AI Core上的指令队列主要包括如下几类,即Vector指令队列(V)、Matrix指令队列(M)和存储移动指令队列(MTE2、MTE3)。不同指令队列间的相互独立性和可并行执行性,是double buffer优化机制的基石。
矢量计算CopyIn、CopyOut过程使用存储移动指令队列(MTE2、MTE3),Compute过程使用Vector指令队列(V),意味着CopyIn、CopyOut过程和Compute过程是可以并行的。
如图1所示,考虑一个完整的数据搬运和计算过程,CopyIn过程将数据从Global Memory搬运到Local Memory,Vector计算单元完成计算后,经过CopyOut过程将计算结果搬回Global Memory。
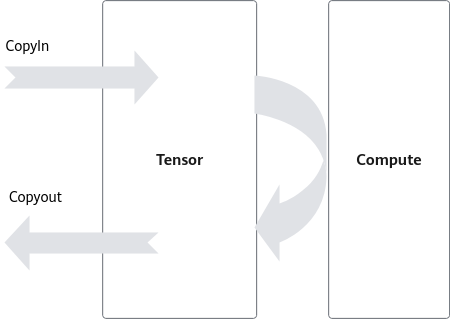
在此过程中,数据搬运与Vector计算串行执行,Vector计算单元无可避免存在资源闲置问题。举例而言,若CopyIn、Compute、CopyOut三阶段分别耗时t,则Vector的时间利用率仅为1/3,等待时间过长,Vector利用率严重不足。
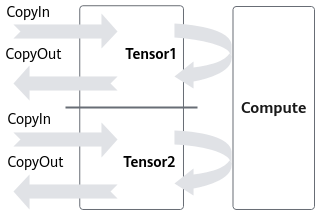
为减少Vector等待时间,double buffer机制将待处理的数据一分为二,比如Tensor1、Tensor2。如图2所示,当Vector对Tensor1中数据进行Compute时,Tensor2可以执行CopyIn的过程;而当Vector切换到计算Tensor2时,Tensor1可以执行CopyOut的过程。由此,数据的进出搬运和Vector计算实现并行执行,Vector闲置问题得以有效缓解。
总体来说,double buffer是基于MTE指令队列与Vector指令队列的独立性和可并行性,通过将数据搬运与Vector计算并行执行以隐藏数据搬运时间并降低Vector指令的等待时间,最终提高Vector单元的利用效率,您可以通过为队列申请内存时设置内存块的个数来实现数据并行,简单代码示例如下:
pipe.InitBuffer(inQueueX, 2, 256);
需要注意:
多数情况下,采用double buffer能有效提升Vector的时间利用率,缩减算子执行时间。然而,double buffer机制缓解Vector闲置问题并不代表它总能带来整体的性能提升。例如:
- 当数据搬运时间较短,而Vector计算时间显著较长时,由于数据搬运在整个计算过程中的时间占比较低,double buffer机制带来的性能收益会偏小。
- 又如,当原始数据较小且Vector可一次性完成所有计算时,强行使用double buffer会降低Vector计算资源的利用率,最终效果可能适得其反。
因此,double buffer的性能收益需综合考虑Vector算力、数据量大小、搬运与计算时间占比等多种因素。
