Sub
功能说明
按元素求差,计算公式如下,其中PAR表示矢量计算单元一个迭代能够处理的元素个数:
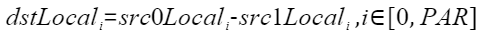
函数原型
- 整个tensor参与计算
1dstLocal = src0Local - src1Local;
- tensor前n个数据计算
1 2
template <typename T> __aicore__ inline void Sub(const LocalTensor<T>& dstLocal, const LocalTensor<T>& src0Local, const LocalTensor<T>& src1Local, const int32_t& calCount)
- tensor高维切分计算
- mask逐bit模式
1 2
template <typename T, bool isSetMask = true> __aicore__ inline void Sub(const LocalTensor<T>& dstLocal, const LocalTensor<T>& src0Local, const LocalTensor<T>& src1Local, uint64_t mask[2], const uint8_t repeatTimes, const BinaryRepeatParams& repeatParams)
- mask连续模式
1 2
template <typename T, bool isSetMask = true> __aicore__ inline void Sub(const LocalTensor<T>& dstLocal, const LocalTensor<T>& src0Local, const LocalTensor<T>& src1Local, uint64_t mask, const uint8_t repeatTimes, const BinaryRepeatParams& repeatParams)
- mask逐bit模式
参数说明
参数名 |
描述 |
|---|---|
T |
操作数数据类型。 |
isSetMask |
是否在接口内部设置mask。
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas 训练系列产品,支持的数据类型为:half/float/int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/int16_t/float/int32_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/int16_t/float/int32_t Atlas 200/500 A2推理产品,支持的数据类型为:half/int16_t/float/int32_t |
src0Local、src1Local |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 两个源操作数的数据类型需要与目的操作数保持一致。 Atlas 训练系列产品,支持的数据类型为:half/float/int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/int16_t/float/int32_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/int16_t/float/int32_t Atlas 200/500 A2推理产品,支持的数据类型为:half/int16_t/float/int32_t |
calCount |
输入 |
输入数据元素个数。 |
mask |
输入 |
|
repeatTimes |
输入 |
重复迭代次数。矢量计算单元,每次读取连续的256 Bytes数据进行计算,为完成对输入数据的处理,必须通过多次迭代(repeat)才能完成所有数据的读取与计算。repeatTimes表示迭代的次数。 |
repeatParams |
输入 |
控制操作数地址步长的参数。BinaryRepeatParams类型,包含操作数相邻迭代间相同datablock的地址步长,操作数同一迭代内不同datablock的地址步长等参数。 相邻迭代间的地址步长参数说明请参考repeatStride(相邻迭代间相同datablock的地址步长);同一迭代内datablock的地址步长参数说明请参考dataBlockStride(同一迭代内不同datablock的地址步长)。 |
返回值
无
支持的型号
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
注意事项
- 使用tensor高维切分计算接口时,节省地址空间,开发者可以定义一个Tensor,供源操作数与目的操作数同时使用(即地址重叠),相关约束如下:
- 对于单次repeat(repeatTimes=1),且源操作数与目的操作数之间要求100%完全重叠,不支持部分重叠。
- 对于多次repeat(repeatTimes>1),操作数与目的操作数之间存在依赖的情况下,即第N次迭代的目的操作数是第N+1次的源操作数,不支持地址重叠的。以下情况是支持地址重叠的:当数据类型为half,int32_t,float时,支持目的操作数与第二个源操作数重叠;src1RepStride/dstRepStride为0;src0与src1之间不能有任何的地址重叠。
- 使用整个tensor参与计算接口符号重载时,运算量为目的LocalTensor的总长度。
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
本样例中只展示Compute流程中的部分代码。如果您需要运行样例代码,请将该代码段拷贝并替换双目指令样例模板更多样例中的Compute函数即可。
- tensor高维切分计算样例-mask连续模式
1 2 3 4 5
uint64_t mask = 128; // repeatTimes = 4, 一次迭代计算128个数, 共计算512个数 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内数据连续读取和写入 // dstRepStride, src0RepStride, src1RepStride = 8, 相邻迭代间数据连续读取和写入 AscendC::Sub(dstLocal, src0Local, src1Local, mask, 4, { 1, 1, 1, 8, 8, 8 });
- tensor高维切分计算样例-mask逐bit模式
1 2 3 4 5
uint64_t mask[2] = { UINT64_MAX, UINT64_MAX }; // repeatTimes = 4, 一次迭代计算128个数, 共计算512个数 // dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内数据连续读取和写入 // dstRepStride, src0RepStride, src1RepStride = 8, 相邻迭代间数据连续读取和写入 AscendC::Sub(dstLocal, src0Local, src1Local, mask, 4, { 1, 1, 1, 8, 8, 8 });
- tensor前n个数据计算样例
1AscendC::Sub(dstLocal, src0Local, src1Local, 512);
- 整个tensor参与计算样例
1dstLocal = src0Local - src1Local;
输入数据(src0Local): [1 2 3 ... 512] 输入数据(src1Local): [513 514 515 ... 1024] 输出数据(dstLocal): [-512 -512 -512 ... -512]
