Gatherb
功能说明
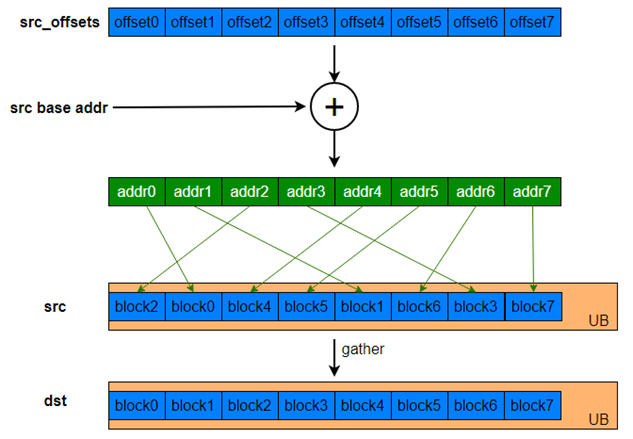
给定一个输入的张量和一个地址偏移张量,Gatherb指令根据偏移地址将输入张量收集到结果张量中。
函数原型
1 2 |
template <typename T> __aicore__ inline void Gatherb(const LocalTensor<T>& dstLocal, const LocalTensor<T>& src0Local, const LocalTensor<uint32_t>& offsetLocal, const uint8_t repeatTimes, const GatherRepeatParams& repeatParams) |
参数说明
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint16_t/uint32_t |
|
src0Local |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 源操作数的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint16_t/uint32_t |
|
offsetLocal |
输入 |
源操作数,类型为LocalTensor。 每个block在源操作数中对应的地址偏移,该偏移量是相对于srcLocal的基地址而言的,每个element值要大于等于0,单位为Bytes。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint32_t |
|
repeatTimes |
输入 |
重复迭代次数,每次迭代完成8个block的数据收集,数据范围:repeatTimes∈(0,255]。 数据类型uint8_t。 |
|
repeatParams |
输入 |
指令迭代参数,类型为GatherRepeatParams,参数说明参考表2。 |
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
注意事项
无
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
#include "kernel_operator.h" class VgatherbCase { public: __aicore__ inline VgatherbCase() {} __aicore__ inline void Init(__gm__ uint8_t *x, __gm__ uint8_t *y, __gm__ uint8_t *offset) { x_gm.SetGlobalBuffer(reinterpret_cast<__gm__ uint16_t *>(x)); y_gm.SetGlobalBuffer(reinterpret_cast<__gm__ uint16_t *>(y)); offset_gm.SetGlobalBuffer(reinterpret_cast<__gm__ uint32_t *>(offset)); uint32_t len = 128; bufferLen = len; tpipe.InitBuffer(vecIn, 2, bufferLen * sizeof(uint16_t)); tpipe.InitBuffer(vecOffset, 2, 16 * sizeof(uint32_t)); tpipe.InitBuffer(vecOut, 2, bufferLen * sizeof(uint16_t)); } __aicore__ inline void CopyIn(uint32_t index) { auto x_buf = vecIn.AllocTensor<uint16_t>(); auto offset_buf = vecOffset.AllocTensor<uint32_t>(); AscendC::DataCopy(x_buf, x_gm[index * bufferLen], bufferLen); AscendC::DataCopy(offset_buf, offset_gm[0], 16); vecIn.EnQue(x_buf); vecOffset.EnQue(offset_buf); } __aicore__ inline void CopyOut(uint32_t index) { auto y_buf = vecOut.DeQue<uint16_t>(); AscendC::DataCopy(y_gm[index * bufferLen], y_buf, bufferLen); vecOut.FreeTensor(y_buf); } __aicore__ inline void Compute() { auto x_buf = vecIn.DeQue<uint16_t>(); auto offset_buf = vecOffset.DeQue<uint32_t>(); auto y_buf = vecOut.AllocTensor<uint16_t>(); AscendC::GatherRepeatParams params{1, 8}; uint8_t repeatTime = bufferLen * sizeof(uint16_t) / 256; AscendC::Gatherb<uint16_t>(y_buf, x_buf, offset_buf, repeatTime, params); vecIn.FreeTensor(x_buf); vecOffset.FreeTensor(offset_buf); vecOut.EnQue(y_buf); } __aicore__ inline void Process() { for (int i = 0; i < 1; i++) { CopyIn(i); Compute(); CopyOut(i); } } private: AscendC::GlobalTensor<uint16_t> x_gm; AscendC::GlobalTensor<uint16_t> y_gm; AscendC::GlobalTensor<uint32_t> offset_gm; AscendC::TPipe tpipe; AscendC::TQue<AscendC::QuePosition::VECIN, 2> vecIn; AscendC::TQue<AscendC::QuePosition::VECIN, 2> vecOffset; AscendC::TQue<AscendC::QuePosition::VECOUT, 2> vecOut; uint32_t bufferLen = 0; }; extern "C" __global__ __aicore__ void vgatherb_core(__gm__ uint8_t *x, __gm__ uint8_t *y, __gm__ uint8_t *offset) { VgatherbCase op; op.Init(x, y, offset); op.Process(); } |
结果示例:
输入数据(offsetLocal): [224 192 160 128 96 64 32 0] 输入数据(srcLocal): [0 1 2 3 4 5 6 7 ... 120 121 122 123 124 125 126 127] 输出数据(dstGlobal):[ 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 ... 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ]
父主题: 矢量计算