vec_reduce_add
功能说明
对所有输入数据求和。数据采用二叉树方式,两两相加。
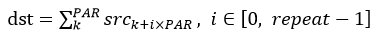
假设源操作数为256个float16的数据[data0,data1,data2...data255],两个repeat可以计算完,计算过程如下。
- [data0,data1,data2...data127]为第一个repeat的源操作数,计算得到result01,具体计算方式为:
- data0和data1相加得到data00,data2和data3相加得到data01,...,data124和data125相加得到data62,data126和data127相加得到data63。
- data00和data01相加得到data000,data02和data03相加得到data001,...,data62和data63相加得到data031。
- 以此类推,计算得到result01。
- [data128,data1,data2...data255]为第二个repeat的源操作数,计算得到result02;
- 将result01与result02相加,得到目的操作数为1个float16的数据[data]。
- result01,result02,result03,result04...多个repeat之间的结果也是两两相加。
- Atlas A2训练系列产品/Atlas 800I A2推理产品,累加方式有所变化,repeat内的源操作数两两相加,每255个范围内的repeat结果按照顺序相加,最后将多个255个repeat结果之和两两相加。假设源操作数为128*256*4个float16数据[data0,data1,...data131072], repeat值为256 *4,则需要(256*4 + 255 - 1)//255=5次算完 计算过程如下。
- [data0, data1,...data127]为第一个repeat源操作数,计算得到result01,repeat内两两相加:
data0 + data1) + (data2 + data3) ... (data126 + data127)计算得到result01
- 然后[data128,data129,...data255]为第二个repeat的源操作数,按照第一步的方式计算得到result02
- 从第一个repeat计算结果result01, 到第255个repeat计算结果result255, 这些result将按顺序相加,((result01 + result02) + result03) + result04 ... + result255, 得到A
- 按照第三步的方式计算result256到result510一共255个repeat结果, 按顺序相加 ((result256 + result257) + result258) + result259 ... + result510, 得到B
- 按照第三步的方式计算result511到result765一共255个repeat结果, 按顺序相加 ((result511 + result512) + result513) + result514 ... + result765, 得到C
- 按照第三步的方式计算result766到result1020一共255个repeat结果, 按顺序相加 ((result766 + result767) + result768) + result769 ... + result1020, 得到D
- 按照第三步的方式计算result1021到result1024一共4个repeat结果, 按顺序相加 ((result1021 + result1022) + result1023) + result1024, 得到E
- 第三步到第七步一共为 255 + 255 + 255 + 255 + 4 = 256 * 4 个repeat, 他们的结果A、B、C、D、E分别两两相加 (A + B) + (C + D) +E 得到目的操作数为1个float16的数据
- [data0, data1,...data127]为第一个repeat源操作数,计算得到result01,repeat内两两相加:
- Atlas 200/500 A2推理产品,累加方式有所变化,先进行repeat之间对应元素顺序累加,再将累加结果进行两两相加
假设源操作数为128*128个float16数据[data0,data1,...data16384], repeat值为128,计算过程如下。
1、repeat01 + repeat03 + repeat05 + repeat07 ... = A 以1个repeat的元素为单位奇数位顺序累加
2、repeat02 + repeat04 + repeat06 + repeat08 ... = B 以1个repeat的元素为单位偶数位顺序累加
3、如果 repeat_times % 2 == 1, 则最后一次repeat元素记为 C
4、D = A + B + C 顺序累加A,B, C得到D,此时D有128个元素
5、对D所有元素做相邻两个元素两两相加得到最终的结果
函数原型
vec_reduce_add(mask, dst, src, work_tensor, repeat_times, src_rep_stride)
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
mask |
输入 |
请参考表1中mask参数描述。 |
dst |
输出 |
目的操作数,tensor起始element。 Tensor的scope为Unified Buffer。 |
src |
输入 |
源操作数,tensor起始element。 Tensor的scope为Unified Buffer。 |
work_tensor |
输入 |
指令执行期间存储中间结果,用于内部计算所需操作空间,需特别注意空间大小,参见各指令注意事项。 |
repeat_times |
输入 |
重复迭代次数。 |
src_rep_stride |
输入 |
相邻迭代间,源操作数相同block地址步长。 |
dst、src和work_tensor的数据类型需保持一致。
Atlas 200/300/500 推理产品,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas 训练系列产品,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas推理系列产品AI Core,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas推理系列产品Vector Core,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas A2训练系列产品/Atlas 800I A2推理产品,dst/src支持的数据类型为:Tensor(float16/float32)
Atlas 200/500 A2推理产品,dst/src支持的数据类型为:Tensor(float16/float32)
,dst/src支持的数据类型为:Tensor(float16/float32)
返回值
无
支持的型号
Atlas 200/300/500 推理产品
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas推理系列产品Vector Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
注意事项
- work_tensor空间要求
- Atlas 200/300/500 推理产品,work_tensor空间至少需要repeat_times个elements。例如当repeat_times=120时,work_tensor的size至少为120个elements。
- Atlas 训练系列产品,work_tensor空间至少需要repeat_times个elements。例如当repeat_times=120时,work_tensor的size至少为120个elements。
- Atlas推理系列产品AI Core,work_tensor空间至少需要repeat_times个elements。例如当repeat_times=120时,work_tensor的size至少为120个elements。
- Atlas推理系列产品Vector Core,work_tensor空间至少需要repeat_times个elements。例如当repeat_times=120时,work_tensor的size至少为120个elements。
- Atlas A2训练系列产品/Atlas 800I A2推理产品,work_tensor空间至少需要(repeat_times + 255 - 1) // 255个elements。当repeat_times <=255 时,计算结果直接写入dst,此时work_tensor无效。例如当repeat_times=256时,work_tensor的size至少为2个element
- repeat_times
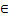 [1, 4095]。支持的数据类型为:Scalar(int32)、立即数(int)、Expr(int32)。
[1, 4095]。支持的数据类型为:Scalar(int32)、立即数(int)、Expr(int32)。 - src_rep_stride
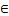 [0,65535],支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。
[0,65535],支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。 - 需要注意的是两两相加的计算过程中,计算结果溢出时根据系统inf/nan控制位决定溢出后处理方式,分为按照最值处理和inf/nan处理两种。当按照最值处理时,float16类型数据相加后大于65504时结果保存为65504。例如源操作数为[60000,60000,-30000,100],首先60000+60000溢出,结果为65504,第二步计算-30000+100=-29900,第四步计算65504-29900=35604。
- src、dst和work_tensor三者互相之间不能存在地址重叠。
- 输入输出Tensor地址要求
- Atlas 200/300/500 推理产品,src、dst和work_tensor三者互相之间不能存在地址重叠。
- Atlas 训练系列产品,src、dst和work_tensor三者互相之间不能存在地址重叠。
- Atlas推理系列产品AI Core,src、dst和work_tensor三者互相之间不能存在地址重叠。
- Atlas推理系列产品Vector Core,src、dst和work_tensor三者互相之间不能存在地址重叠。
- Atlas 200/500 A2推理产品,src、dst和work_tensor三者互相之间不能存在地址重叠。
- Atlas A2训练系列产品/Atlas 800I A2推理产品,src、dst和work_tensor三者互相之间不能存在地址重叠。
- 操作数地址偏移对齐要求请见通用约束。
调用示例
- 示例一
from tbe import tik tik_instance = tik.Tik() src_gm = tik_instance.Tensor("float16", (256,), name="src_gm", scope=tik.scope_gm) dst_gm = tik_instance.Tensor("float16", (32,), name="dst_gm", scope=tik.scope_gm) src_ub = tik_instance.Tensor("float16", (256,), name="src_ub", scope=tik.scope_ubuf) dst_ub = tik_instance.Tensor("float16", (32,), name="dst_ub", scope=tik.scope_ubuf) work_tensor_ub = tik_instance.Tensor("float16", (32,), tik.scope_ubuf, "work_tensor_ub") # 拷贝用户输入数据到src ubuf tik_instance.data_move(src_ub, src_gm, 0, 1, 16, 0, 0) # 给dst ubuf赋初始值0,这样输出结果更加直观 tik_instance.vec_dup(32, dst_ub, 0, 1, 1) tik_instance.vec_reduce_add(128, dst_ub, src_ub, work_tensor_ub, 2, 8) # 将计算结果拷贝到目标gm tik_instance.data_move(dst_gm, dst_ub, 0, 1, 2, 0, 0) tik_instance.BuildCCE(kernel_name="vec_reduce_add", inputs=[src_gm], outputs=[dst_gm])结果示例如下:
输入: src_gm=[1,1,1,...,1] 输出结果为: dst_gm=[256,0,0,...,0]
- 示例二
tik_instance = tik.Tik() dtype_size = { "int8": 1, "uint8": 1, "int16": 2, "uint16": 2, "float16": 2, "int32": 4, "uint32": 4, "float32": 4, "int64": 8, } # Tensor 的形状 src_shape = (3, 128) dst_shape = (64,) # 数据量大小 src_elements = 3 * 128 dst_elements = 64 # 数据类型 dtype = "float16" src_gm = tik_instance.Tensor(dtype, src_shape, name="src_gm", scope=tik.scope_gm) dst_gm = tik_instance.Tensor(dtype, dst_shape, name="dst_gm", scope=tik.scope_gm) src_ub = tik_instance.Tensor(dtype, src_shape, name="src_ub", scope=tik.scope_ubuf) dst_ub = tik_instance.Tensor(dtype, dst_shape, name="dst_ub", scope=tik.scope_ubuf) work_tensor_ub = tik_instance.Tensor(dtype, dst_shape, tik.scope_ubuf, "work_tensor_ub") # 拷贝用户输入数据到src ubuf # 搬移的片段数 nburst = 1 # 每次搬运的片段长度,单位32B burst = src_elements * dtype_size[dtype] // 32 // nburst dst_burst = dst_elements * dtype_size[dtype] // 32 // nburst # 前burst尾与后burst头的距离,单位32B dst_stride, src_stride = 0, 0 tik_instance.data_move(src_ub, src_gm, 0, nburst, burst, dst_stride, src_stride) # 给dst ubuf赋初始值0,这样输出结果更加直观, 此处暂不对vec_dup 进行说明,详细内容请参考对应的章节 tik_instance.vec_dup(64, dst_ub, 0, 1, 1) tik_instance.vec_dup(64, work_tensor_ub, 0, 1, 1) # 每个迭代的源操作数, 不同的数据类型其取值范围不同,可参见对应的章节,此示例以每次迭代处理34个数 mask = 34 # 可根据实际情况配置相应的迭代, 此处以6次迭代为例 repeat_times = 6 # 相邻迭代间,操作数头与头之间的步长,单位为block,当前表示第一次迭代的头与第二次迭代头间隔3个block src_rep_stride = 3 tik_instance.vec_reduce_add(mask, dst_ub, src_ub, work_tensor_ub, repeat_times, src_rep_stride) # 当前示例中work_tensor_ub 存储的值是[34. 34. 36. 68. 68. 86. 0. 0. ...],分别为6次迭代的结果 # 将计算结果拷贝到目标gm tik_instance.data_move(dst_gm, dst_ub, 0, nburst, dst_burst, dst_stride, src_stride) tik_instance.BuildCCE(kernel_name="vec_reduce_add", inputs=[src_gm], outputs=[dst_gm]) 示例结果 输入数据(src_gm): [[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3.]] 输出数据(dst_gm): [326. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]