简介
昇腾AI处理器支持多种数据精度,当前支持的有FP16、INT8、INT4。正常情况下,数据精度越高,计算越准确,模型的计算准确度越高;但同时硬件资源消耗也越多,性能也越低。为了平衡性能和准确度,可以选择对模型做混合精度处理,即同一个模型中同时存在多种数据精度(FP16、INT8、INT4)或其中的一部分。
当前量化感知训练支持对不同的层做不同精度的量化处理,INT4量化与INT8量化相比,可以提升性能,但精度损失下降多,需要通过手动回退若干层精度才能达标,而对于某一层,如何选择数据精度(即配置中的dst_type,详情请参见量化感知训练简易配置文件)是比较困难的,手动尝试的配置需要进行重训练,耗费时间多。针对上述问题,引入自动混合精度搜索特性,对于量化感知训练场景下用户手动调优难的问题,给出一组较优解,平衡精度和性能,缩短调优时间:基于训练后量化来获取可量化层对数据精度的敏感度,使用每一层的计算量来估计性能,综合上面两个因素,搜索最佳的混合精度配置,生成一个用于量化感知训练的简易配置文件,可进行后续的量化感知训练。
自动混合精度搜索实现流程如图1所示,由于自动混合精度搜索功能中包括训练后量化和量化感知训练,因此支持的层以及规格为训练后量化和量化感知训练所支持的层以及规格。
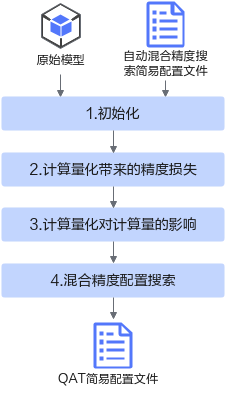
各流程简要说明如下:
- 初始化:初始化动作首先需要解析用户原始模型以及自动混合精度搜索简易配置文件,分析网络中可量化层及其对应的量化算法以及用户目标压缩率配置等,然后进行初始化动作:调用Evaluator模块中的calibration函数(详情请参见2),分别计算INT4、INT8量化位宽下可量化层的量化因子;调用Evaluator模块中的evaluate函数,执行前向推理时,生成每一量化层的dump数据。
典型的压缩率:整网int8量化=4,整网int4量化=16,混合精度配置可以为1~16之间的一个浮点数。
- 根据每层的量化因子和每层的dump数据,计算模型中每一层在特定量化位宽下的量化敏感度,概念解释请参见表1。
- 根据特定量化位宽和输入输出Shape计算模型中每一层的比特复杂度,概念解释请参见表1。
- 混合精度配置搜索:根据量化敏感度和比特复杂度,在满足压缩率的条件下,获取量化敏感度最小的混合精度配置,即量化位宽调整过的量化感知训练简易配置文件(当前仅支持生成量化感知训练简易配置文件)。

父主题: 自动混合精度搜索