Ascend PyTorch Profiler接口采集数据
采集数据目录说明
原始的性能数据落盘目录结构为:
- 调用tensorboard_trace_handler函数时的落盘目录结构:

└── localhost.localdomain_139247_20230628101435_ascend_pt // 解析结果目录,命名格式:{worker_name}_{时间戳}_ascend_pt,默认情况下{worker_name}为{hostname}_{pid} ├── profiler_info.json // 多卡或集群场景命名规则为profiler_info_{Rank_ID}.json,用于记录Profiler相关的元数据 ├── profiler_metadata.json ├── ASCEND_PROFILER_OUTPUT // Ascend PyTorch Profiler接口采集性能数据 │ ├── ascend_pytorch_profiler_{rank_id}.db // export_type=torch_npu.profiler.ExportType.Db时该目录下仅生成.db文件,其他.json和.csv文件不生成,使用MindStudio Insight工具展示 │ ├── analysis.db // 多卡或集群等存在通信的场景下,设置export_type=torch_npu.profiler.ExportType.Db时该目录下仅生成.db文件,其他.json和.csv文件不生成,使用MindStudio Insight工具展示 │ ├── communication.json // 为多卡或集群等存在通信的场景性能分析提供可视化数据基础,配置experimental_config的profiler_level=torch_npu.profiler.ProfilerLevel.Level1或profiler_level=torch_npu.profiler.ProfilerLevel.Level2生成 │ ├── communication_matrix.json // 通信小算子基本信息文件,配置experimental_config的profiler_level=torch_npu.profiler.ProfilerLevel.Level1或profiler_level=torch_npu.profiler.ProfilerLevel.Level2生成 │ ├── data_preprocess.csv // 配置experimental_config profiler_level=torch_npu.profiler.ProfilerLevel.Level2生成 │ ├── kernel_details.csv │ ├── l2_cache.csv // 配置experimental_config的l2_cache=True生成 │ ├── memory_record.csv │ ├── npu_module_mem.csv │ ├── operator_details.csv │ ├── operator_memory.csv │ ├── step_trace_time.csv // 迭代中计算和通信的时间统计 │ ├── op_statistic.csv // AI Core和AI CPU算子调用次数及耗时数据 │ ├── api_statistic.csv // 配置experimental_config的profiler_level=torch_npu.profiler.ProfilerLevel.Level1或profiler_level=torch_npu.profiler.ProfilerLevel.Level2生成 │ └── trace_view.json ├── FRAMEWORK // 框架侧的性能原始数据,无需关注,data_simplification=True时删除此目录 │ ├── torch.memory_usage │ ├── torch.op_mark │ ├── torch.op_range │ ├── torch.python_tracer_func // with_stack=True或with_modules=True时生成 │ └── torch.python_tracer_hash // with_stack=True或with_modules=True时生成 └── PROF_000001_20230628101435646_FKFLNPEPPRRCFCBA // CANN层的性能数据,命名格式:PROF_{数字}_{时间戳}_{字符串},data_simplification=True时,仅保留此目录下的原始性能数据,删除其他数据 ├── analyze // 配置experimental_config的profiler_level=torch_npu.profiler.ProfilerLevel.Level1或profiler_level=torch_npu.profiler.ProfilerLevel.Level2生成 ├── device_* ├── host ├── mindstudio_profiler_log └── mindstudio_profiler_output ├── localhost.localdomain_139247_20230628101435_ascend_pt_op_args // 算子信息统计文件目录,配置experimental_config的record_op_args=True生成Ascend PyTorch Profiler接口将框架侧的数据与CANN Profling的数据关联整合,形成trace、kernel以及memory等性能数据文件。各文件详细说明如下文所示。
FRAMEWORK为框架侧的性能原始数据,无需关注;PROF目录下为CANN Profling采集的性能数据,主要保存在mindstudio_profiler_output目录下,数据介绍请参见性能数据文件参考。
- 调用export_chrome_trace方法时,Ascend PyTorch Profiler接口会将解析的trace数据写入到*.json文件中,其中*为文件名,不存在该文件时在指定路径下自动创建。
trace_view.json

如图1所示,trace数据主要展示如下区域:
- 区域1:上层应用数据,包含上层应用算子的耗时信息。
- 区域2:CANN层数据,主要包含AscendCL、GE和Runtime组件的耗时数据。
- 区域3:底层NPU数据,主要包含Task Scheduler组件耗时数据和迭代轨迹数据以及其他昇腾AI处理器系统数据。
- 区域4:展示trace中各算子、接口的详细信息。单击各个trace事件时展示。
trace_view.json支持使用TensorBoard工具、chrome://tracing/和https://ui.perfetto.dev/打开。
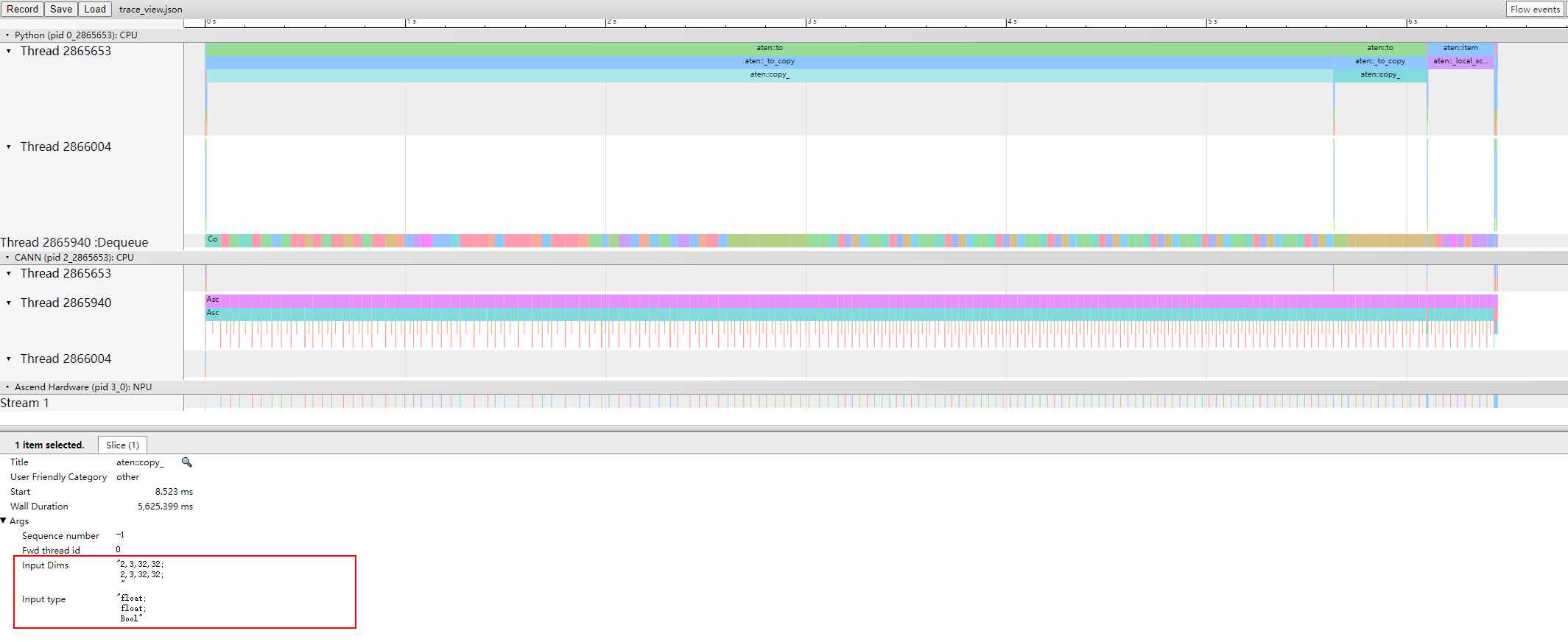
打开record_shapes开关时,trace_view中的上层应用算子会显示Input Dims和Input type信息。
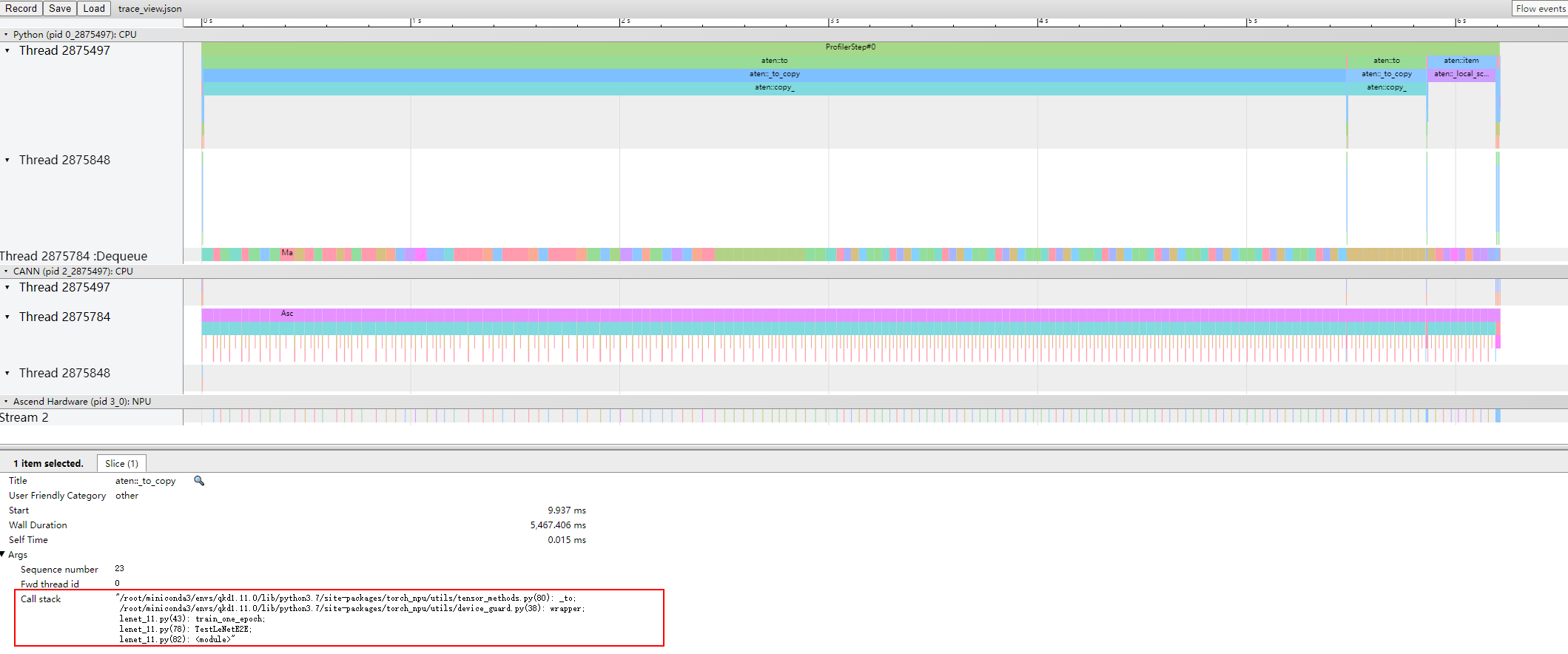
打开with_stack开关时,trace_view中的上层应用算子会显示Call stack信息。
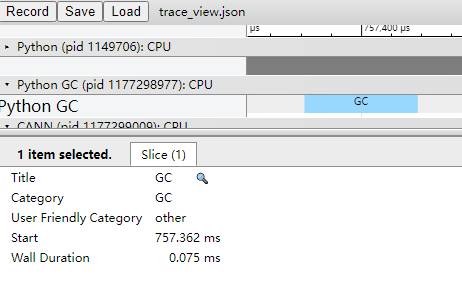
图4采集结果中Python GC层的时间段为本次GC执行的时间。
GC执行时,会阻塞当前进程,需要等待GC完成,若GC时间过长,可以通过调整GC参数(可参考垃圾回收器中的gc.set_threshold)来缓解GC造成的进程阻塞。
kernel_details.csv

kernel_details.csv文件由torch_npu.profiler.ProfilerActivity.NPU开关控制,文件包含在NPU上执行的所有算子的信息,若用户前端调用了schedule进行step打点,则会增加Step Id字段。字段信息如表1所示。
当配置experimental_config的aic_metrics参数时,kernel_details.csv文件将根据experimental_config参数的aic_metrics配置增加对应字段,主要增加内容请参见experimental_config参数说明,文件内相关字段详细介绍请参见op_summary(算子详细信息)。
|
字段名 |
字段解释 |
|---|---|
|
Step Id |
迭代ID。 |
|
Model ID |
模型ID。 |
|
Task ID |
Task任务的ID。 |
|
Stream ID |
该Task所处的Stream ID。 |
|
Name |
算子名。 |
|
Type |
算子类型。 |
|
OP State |
算子的动静态信息,dynamic表示动态算子,static表示静态算子,HCCL算子无该状态显示为N/A,该字段仅在--task-time=l1情况下上报,--task-time=l0时显示为N/A。 |
|
Accelerator Core |
AI加速核类型,包括AI Core、AI CPU等。 |
|
Start Time(us) |
算子执行开始时间,单位us。 |
|
Duration(us) |
当前算子执行耗时,单位us。 |
|
Wait Time(us) |
算子执行等待时间,单位us。 |
|
Block Dim |
运行切分数量,对应任务执行时核数。 |
|
Mix Block Dim |
部分算子同时在AI Core和Vector Core上执行,主加速器的Block Dim在Block Dim字段描述,从加速器的Block Dim在本字段描述。task_time为l0时,不采集该字段,显示为N/A。(Atlas A2训练系列产品/Atlas 800I A2推理产品) |
|
HF32 Eligible |
标识是否使用HF32精度标记,YES表示使用,NO表示未使用。 |
|
Input Shapes |
算子输入Shape。 |
|
Input Data Types |
算子输入数据类型。 |
|
Input Formats |
算子输入数据格式。 |
|
Output Shapes |
算子输出Shape。 |
|
Output Data Types |
算子输出数据类型。 |
|
Output Formats |
算子输出数据格式。 |
memory_record.csv
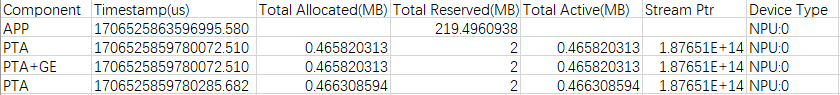
memory_record.csv文件由profile_memory开关控制,文件包含PTA和GE的内存占用记录,主要记录PTA和GE组件录算子级(PTA、GE、PTA+GE)、进程级申请的内存及占用时间。字段信息如表2所示。
|
字段名 |
字段解释 |
|---|---|
|
Component |
组件,包含PTA和GE组件,PTA、GE、PTA+GE为算子级,APP为进程级。 |
|
Timestamp(us) |
时间戳,记录内存占用的起始时间,单位us。 |
|
Total Allocated(MB) |
内存分配总额,单位MB。 |
|
Total Reserved(MB) |
内存预留总额,单位MB。 |
|
Total Active(MB) |
PTA中的流所申请的总内存(包括被其他流复用的未释放的内存),单位MB。 |
|
Stream Ptr |
AscendCL流的内存地址,用于标记不同的AscendCL流。 |
|
Device Type |
设备类型和设备ID,仅涉及NPU。 |
operator_memory.csv

operator_memory.csv文件由profile_memory开关控制,文件包含算子的内存占用明细,主要记录算子在NPU上执行所需内存及占用时间,其中内存由PTA和GE申请。字段信息如表3所示。
|
字段名 |
字段解释 |
|---|---|
|
Name |
算子名称。 |
|
Size(KB) |
算子占用内存大小,单位KB。 |
|
Allocation Time(us) |
Tensor内存分配时间,单位us。 |
|
Release Time(us) |
Tensor内存释放时间,单位us。 |
|
Active Release Time(us) |
内存实际归还内存池时间,单位us。 |
|
Duration(us) |
内存占用时间(Release Time-Allocation Time),单位us。 |
|
Active Duration(us) |
内存实际占用时间(Active Release Time-Allocation Time),单位us。 |
|
Allocation Total Allocated(MB) |
算子内存分配时的内存分配总额(Name算子名称为aten开头时为PTA内存,算子名称为cann开头时为GE内存),单位MB。 |
|
Allocation Total Reserved(MB) |
算子内存分配时的内存占用总额(Name算子名称为aten开头时为PTA内存,算子名称为cann开头时为GE内存),单位MB。 |
|
Allocation Total Active(MB) |
算子内存分配时当前流所申请的总内存(包括被其他流复用的未释放的内存),单位MB。 |
|
Release Total Allocated(MB) |
算子内存释放时的内存分配总额(Name算子名称为aten开头时为PTA内存,算子名称为cann开头时为GE内存),单位MB。 |
|
Release Total Reserved(MB) |
算子内存释放时的内存占用总额(Name算子名称为aten开头时为PTA内存,算子名称为cann开头时为GE内存),单位MB。 |
|
Release Total Active(MB) |
算子内存释放时的内存中被其他Stream复用的内存总额(Name算子名称为aten开头时为PTA内存,算子名称为cann开头时为GE内存),单位MB。 |
|
Stream Ptr |
AscendCL流的内存地址,用于标记不同的AscendCL流。 |
|
Device Type |
设备类型和设备ID,仅涉及NPU。 |
npu_module_mem.csv
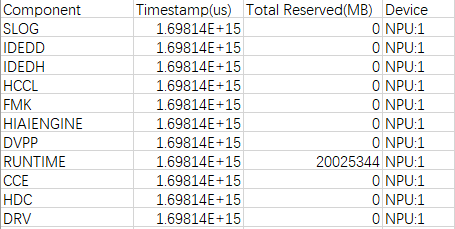
npu_module_mem.csv数据在PyTorch性能数据采集时自动采集,包含组件级的内存占用情况,主要记录组件在NPU上执行时,当前时刻所占用的内存。字段信息如表4所示。
operator_details.csv
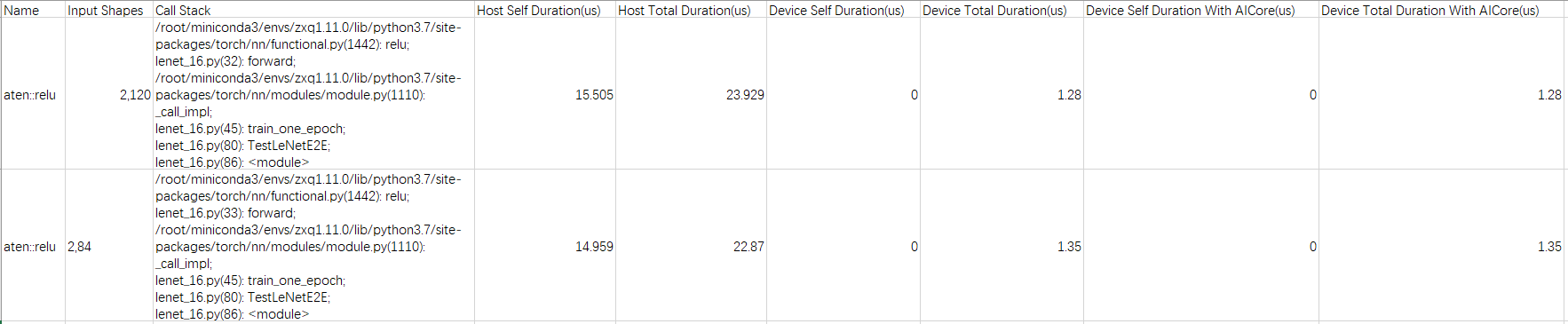
operator_details.csv文件由torch_npu.profiler.ProfilerActivity.CPU开关控制,operator_details.csv文件包含信息如表5所示。
|
字段 |
说明 |
|---|---|
|
Name |
算子名称。 |
|
Input Shapes |
Shape信息。 |
|
Call Stack |
函数调用栈信息。由with_stack字段控制。 |
|
Host Self Duration(us) |
算子在Host侧的耗时(除去内部调用的其他算子),单位us。 |
|
Host Total Duration(us) |
算子在Host侧的耗时,单位us。 |
|
Device Self Duration(us) |
算子在Device侧的耗时(除去内部调用的其他算子),单位us。 |
|
Device Total Duration(us) |
算子在Device侧的耗时,单位us。 |
|
Device Self Duration With AICore(us) |
算子在Device侧执行在AI Core上的耗时(除去内部调用的算子),单位us。 |
|
Device Total Duration With AICore(us) |
算子在Device侧执行在AI Core上的耗时,单位us。 |
step_trace_time.csv

step_trace_time.csv文件由trace_view.json文件数据为基础提取而来,包含信息如表6所示。
|
字段 |
说明 |
|---|---|
|
Step |
迭代数。 |
|
Computing |
NPU上算子的计算总时间。 |
|
Communication(Not Overlapped) |
通信时间,通信总时间减去计算和通信重叠的时间。 |
|
Overlapped |
计算和通信重叠的时间。更多重叠代表计算和通信之间更好的并行性。理想情况下,通信与计算完全重叠。 |
|
Communication |
NPU上算子的通信总时间。 |
|
Free |
迭代总时间减去计算和通信时间。可能包括初始化、数据加载、CPU计算等。 |
|
Communication(Not Overlapped and Exclude Receive) |
通信总时间减去计算和通信重叠以及receive算子的时间。 |
|
Preparing |
迭代开始到首个计算或通信算子运行的时间。 |
data_preprocess.csv
data_preprocess.csv文件记录AI CPU数据,示例和字段说明以aicpu(AI CPU算子详细耗时)为参考,实际结果略有不同,请以实际情况为准。
l2_cache.csv
示例和字段说明以l2_cache(L2 Cache命中率)为参考,实际结果略有不同,请以实际情况为准。
op_statistic.csv
示例和字段说明以op_statistic(算子调用次数及耗时)为参考,实际结果略有不同,请以实际情况为准。
api_statistic.csv
示例和字段说明以api_statistic_*.csv文件说明为参考,实际结果略有不同,请以实际情况为准。