EJ0001打屏报错
问题现象
plog日志中,TDT首报错为:[DeviceMsgProcess][tid:1241254] [TsdClient] DeviceMsgProc errcode[EJ0001]
[ERROR] TDT(685010,all_reduce_test):2023-11-29-11:55:41.334.702 [process_mode_manager.cpp:587][DeviceMsgProcess][tid:685010] [TsdClient] DeviceMsgProc errcode[EJ0001] [ERROR] TDT(685010,all_reduce_test):2023-11-29-11:55:41.334.873 [process_mode_manager.cpp:269][WaitRsp][tid:685010] tsd client wait response fail, device response code[1]. unknown device error. [ERROR] TDT(685010,all_reduce_test):2023-11-29-11:55:41.334.893 [process_mode_manager.cpp:123][OpenProcess][tid:685010] Wait open response from device failed. [ERROR] TDT(685010,all_reduce_test):2023-11-29-11:55:41.334.897 [tsd_client.cpp:31][TsdOpen][tid:685010] TsdOpen failed, deviceId[4].
EJ0001错误只能说明拉起device HCCP进程失败,具体失败原因需要根据device报错进一步区分,在debug目录下,使用/usr/local/Ascend/driver/tools/msnpureport -f导出device日志,grep -rn ERROR * | grep HCCP查看HCCP首报错,Device报错有以下两种场景。
- Device报错“Create Server failed, ret(61)”EJ0001报错,通常看到HCCP报错:[ra_adp.c:14c_server_init(1425) : Create Server failed, ret(61)
[ERROR] HCCP(13722,hccp_service.bin):2023-11-29-11:55:41.806.183 [ra_adp.c:1425]tid:13722,ra_hdc_server_init(1425) : Create Server failed, ret(61) [ERROR] HCCP(13722,hccp_service.bin):2023-11-29-11:55:41.806.200 [ra_adp.c:1546]tid:13722,hccp_init(1546) : chip_id[0] ra_hdc_server_init failed, ret[-22] [ERROR] HCCP(13722,hccp_service.bin):2023-11-29-11:55:41.806.265 [main.c:224]tid:13722,main(224) : hccp init error[-22]
- Device报错“certificate is not yet valid”
原因分析与解决方法(Device报错“Create Server failed, ret(61)”)
若Device报错“Create Server failed, ret(61)”,可能有以下两种原因:
- 人为操作问题(偶现),上一次训练未完全退出,就拉起新的训练。
在Host侧执行如下hccn_tool命令:
for i in {0..7}; do hccn_tool -i $i -process -g ; done查看Device侧是否存在hccp进程。
解决办法:
稍等一会(通常停掉训练任务脚本,会进资源销毁释放流程),确认进程完全退出后再拉起训练进程。
- 业务脚本问题(必现),每次拉起训练时,会在一个device上拉起2个及以上的hccp进程。
执行如下命令,导出日志,并确认是否在临近间隔时间,通常是ms级时间间隔内,有两次及以上hccp进程拉起的日志记录。
cd /root/ascend/log/debug/ /usr/local/Ascend/driver/tools/msnpureport -f grep -rn "hccp init" *
如下所示,即可判定是由于业务脚本在一个Device上拉起2个及以上的HCCP进程导致的,需要用户排查业务脚本。
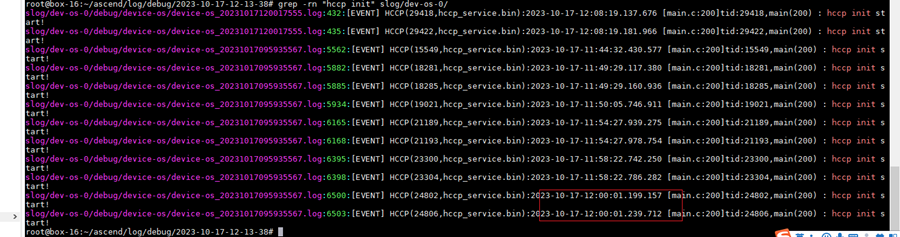
需要注意:该日志等级为EVENT,请确保EVENT日志开关已打开。
日志等级设置参考:
export ASCEND_GLOBAL_LOG_LEVEL=0 # 开启DEBUG export ASCEND_GLOBAL_LOG_LEVEL=1 # 开启INFO export ASCEND_GLOBAL_LOG_LEVEL=2 # 开启WARNING export ASCEND_GLOBAL_LOG_LEVEL=3 # 开启ERROR,默认为ERROR级别
EVENT日志打开命令:
export ASCEND_GLOBAL_EVENT_ENABLE=1 # 1表示开,0表示关
解决方法:

原因分析及解决方法(Device报错“certificate is not yet valid”)
- 原因分析:
若Device报错“certificate is not yet valid”,则原因为:
Host时钟异常,导致系统时间早于TLS证书有效时间,TLS开关打开情况下校验证书失败,拉起训练失败。
如下所示,查询TLS证书看到证书有效起始时间是:2023/09/26
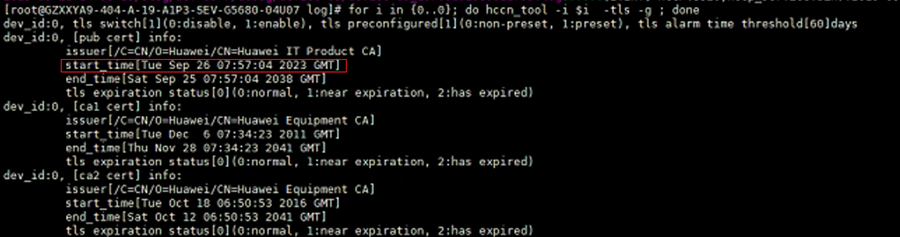
对应HCCP进程拉起时,报错证书无效,校验失败,拉起HCCP失败,看到系统时间是:2019/09/26

- 解决方法:
同步正常时间后,可以恢复。