多机测试大数据量带宽骤降为0
问题现象
多机大数据量进行性能测试时出现以下情况:
- 带宽骤降为0点几。
- 查看统计数据,重传次数(roce_new_pkt_rty_num)会增长。
- 通过环境变量“HCCL_RDMA_TIMEOUT”缩短重传等待时间后,带宽不会再骤降为0点几,例如:
export HCCL_RDMA_TIMEOUT=10
原因分析
数据转发过程中发生丢包,产生了重传,从而拖慢时间。
解决步骤
解决此问题的根因是找到丢包所在的位置,例如spine交换机 、leaf交换机、 服务器、线缆等,可按照如下顺序排查丢包的地方。
- 丢包在线缆,端口闪断丢包。
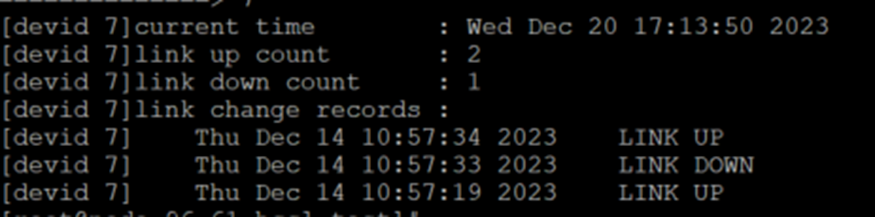
查询端口link记录
for i in $(seq 0 7); do echo "==============> $i"; hccn_tool -i $i -link_stat -g ;done
找到闪断的端口,然后排查硬件闪断原因。
- 丢包在交换机 ——交换机配置原因。
需要排查交换机配置,分别登录spine和leaf交换机检查丢包原因,可能存在如下原因:
- 交换机buffer水线设置不合理,流控方式不对。
- 只配了spine的PFC,没有配leaf交换机PFC,spine反压给leaf ,leaf没有降速,导致丢包。
- ECN和PFC水线配置配合不合理导致丢包,若不是一定要用ECN,建议关掉ECN。
- 丢包在交换机——交换机和服务器配合原因。
交换机和服务器流控参数配置不匹配,流量进错队列丢包。
交换机和服务器的dscp、pfc优先级队列等需要协商一致,原理请参见《Ascend Training Solution 组网指南》中的“拥塞控制与纠错配置策略”章节。
排查交换机配置:
可以在交换机侧看对应的报文dscp对不对,有没有走到对应的队列,命令:
display qos queue statistics interface 10ge 1/0/1
排查服务器流控参配置:
查询 dscp_to_tc for i in $(seq 0 7); do echo "==============> $i"; hccn_tool -i $i -dscp_to_tc -g ;done 查询 PFC for i in $(seq 0 7); do echo "==============> $i"; hccn_tool -i $i -pfc -g;done 设置dscp_to_tc for i in $(seq 0 7); do echo "==============> $i"; hccn_tool -i $i -dscp_to_tc -s dscp 33 tc 2;done 设置PFC for i in $(seq 0 7); do echo "==============> $i";hccn_tool -i $i -pfc -s bitmap 0,0,0,0,1,0,0,0;done
排查流控环境变量:
测试之前要设确保这两个环境变量已经设置,不配置采用默认参数(TC=132 SL=4)
export HCCL_RDMA_TC=132 #数值为dscp左移两位 (乘以4),根据和交换机协商配置 export HCCL_RDMA_SL=4 #数值为PFC的队列,根据和交换机协商配置
- 丢包在服务器(TC buffer被打爆导致丢包)。
原因可能是服务器buffer设置不合理,或者是交换机未响应服务器的PFC,最大使用的buffer达到了TCbuffer最大值,把buffer打爆导致服务器丢包。
说明:默认buffer水线经过多个场景最佳实践一般不需要调整。
- 排查服务器统计是否有tx pfc
for i in $(seq 0 15); do echo "==============> $i"; hccn_tool -i $i -stat -g ;done | grep pfc
- 排查buffer和上下水线,判断使用的最大buffer是否达到了设置的buffer上限
#查询tc buffer配置 for i in $(seq 0 15); do hccn_tool -i $i -tc_cfg -g;done #查询某个TC使用的最大buffer(读清) for i in $(seq 0 15); do hccn_tool -i $i -cur_tc_buf -g tc 1;done #tc根据使用的tc改
- 排查服务器统计是否有tx pfc
父主题: HCCL Test常见问题总结