精度正常
性能优化的基础是算子运行得到正确的计算结果。评判计算结果正确性需要有一定的评判标准,即使用已知的正确的输出和实际结果进行比较。每次优化迭代修改后,需要验证性能优化的新结果是否满足精度评判标准。
下文先介绍几个影响精度正常的方面:
- 正确插入同步,并行计算架构的特点是同步的存在,对于有数据依赖的场景需要正确插入同步。
- 正确计算偏移地址,多核并行计算时,计算数据在内存上的正确偏移对保证计算结果的正确性至关重要。
- 浮点数计算,在涉及浮点计算的情况下,精度正常不能期望数值逐bit一致。因为浮点数的计算本身不满足交换律、结合律,另外不同硬件对浮点数的支持不同,都可能导致精度结果存在差异。
然后介绍编码过程中需要严格遵守的规则(禁止修改kernel函数参数),防止出现不必要的精度问题。
正确插入同步
AI Core内部包括MTE1、MTE2、MTE3、Cube、Vector、Scalar等多条流水线。Ascend C框架默认使能auto sync(自动插入同步)编译选项,编译器可以正常插入同步;Ascend C编程模型也会帮助开发者完成部分流水的同步控制。流水类型的详细介绍、同步类型的分类、编译器自动同步的约束限制、什么时候需要开发者手动插入同步可参考同步控制。
上文描述的都是核内同步的情况。特别的,当算子使用多核同步时(多核同步概念可参考多核同步),逻辑BlockDim必须保证不大于实际运行该算子的AI处理器核数,否则框架会插入异常同步,导致Kernel“卡死”现象。
【反例】
// 存在多核同步逻辑的代码中BlockDim大于CoreNum // 比如在Tiling计算中没有做该校验,假设CoreNum = MAX_AICORE_NUM FlashAttentionScoreApiTiling(tilingData); FlashAttentionScoreGetTensorSize(tilingData); context->SetBlockDim(MAX_AICORE_NUM + 1);
【正例】
FlashAttentionScoreApiTiling(tilingData); FlashAttentionScoreGetTensorSize(tilingData); // 在Kernel中有使用多核同步指令时,Host设置BlockDim需要保证不大于CoreNum context->SetBlockDim(MAX_AICORE_NUM);
正确计算偏移地址
算子使能多核计算时,需要在Tiling的时候确定单核的计算量,Kernel侧根据单核计算量进行地址的偏移。关于正确计算偏移地址的详细介绍可以参考LINK。
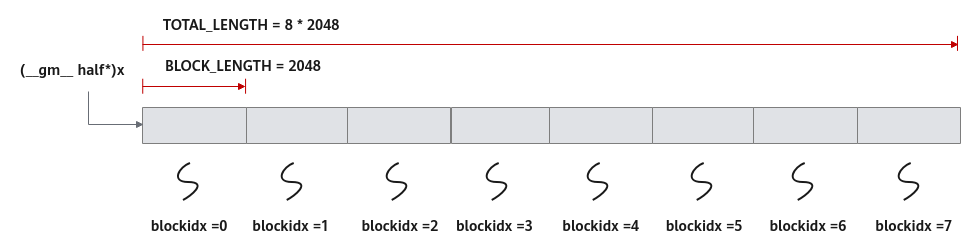
比如如下样例的分配方案:数据整体长度TOTAL_LENGTH为8 * 2048,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048。x + BLOCK_LENGTH * GetBlockIdx()即为单核处理程序中输入x在Global Memory上的内存偏移地址,获取偏移地址后,使用GlobalTensor类的SetGlobalBuffer接口设定该核上Global Memory的起始地址以及长度。具体示意图请参考图1。
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
浮点数计算
- 每个浮点算术运算都涉及一定量的舍入。因此,算术运算的执行顺序很重要。如果A、B和C是浮点值,则(A+B)+C不能保证像数学计算中那样等于A+(B+C)。当并行计算时,您可能会更改操作的顺序,因此并行结果可能与顺序结果不匹配。这种情况带来的精度差异是浮点值计算固有存在的。
- 某些型号的AI处理器指令支持的数据类型有限,当发现某个API支持的数据类型不能满足需求时,应更倾向于先将数据转换到更高的精度进行计算后,再将计算结果转换到目标精度,来防止精度损失。例如,某款AI处理器Vector计算类API不支持bfloat16的计算,需要先使用Cast接口转换成float数据类型,进行计算后再使用Cast接口转换回bfloat16数据类型。
// dst = src0 + src1,bfloat16类型,tmpx临时buffer按照float申请 ... Cast(tmp0Tensor, src0Tensor, RoundMode::CAST_NONE, computeSize); Cast(tmp1Tensor, src1Tensor, RoundMode::CAST_NONE, computeSize); Add(tmp2Tensor, tmp0Tensor, tmp1Tensor, computeSize); Cast(dstTensor, tmp2Tensor, RoundMode::CAST_NONE, computeSize); ...
- 昇腾AI处理器都遵循IEEE 754标准进行二进制浮点表示,除了一些小的例外。这些例外可能会导致与在主机系统上计算的IEEE 754值不同的结果。例如,使用了复合指令的API Axpy,源操作数中每个元素与标量求积后和目的操作数中的对应元素相加,该复合指令将乘加操作组合到单个指令执行,计算结果可能与分别执行这两个操作的单指令得到的结果略有不同。开发者在使用此类API时,需要考虑这种精度差异。
禁止修改kernel函数参数
【描述】禁止修改kernel函数参数,也就是不能对函数参数重新进行赋值和修改。例如:FlashAttentionKernel函数定义如下,其参数query、key、tilingData等为指针类型,该指针本身禁止修改。对于算子输入参数,指针指向的内容不可以修改;作为一个例外,算子输出参数,指针指向的内容可以进行修改。特别要强调一下,为了实现静态编译,无论是对tilingData指针本身,还是对tilingData指针指向的内容均禁止修改。
__aicore__ __global__ void FlashAttentionKernel(__gm__ uint8_t* query, __gm__ uint8_t* key, ..., __gm__ uint8_t* attention,..., __gm__ uint8* tilingData) {
......
}
【反例】
// 对Kernel函数参数重新赋值、对TilingData内容进行修改 query = tmpQueryPtr; key = tmpKeyPtr; tilingData = tmpTilingDataPtr; tillingData[0] = MAX_CORE_NUM;
【正例】
// 输入参数仅进行读操作 inputQueryGMTensor.SetGlobalBuffer(query); // 输出参数attention指针本身是只读,但其指向的内存可以读写 outputAttentionGMTensor.SetGlobalBuffer(attention); ... DataCopy(outputAttentionGMTensor, outputAttentionLocalTensor, 512);