基础知识

融合算子
融合算子是指将多个独立的“小算子”融合起来成为一个“大算子”,多个小算子的功能和大算子的功能等价,大算子的性能优于独立的小算子。可以根据具体算法的实现自由融合Vector、Cube算子以达到性能上的收益。
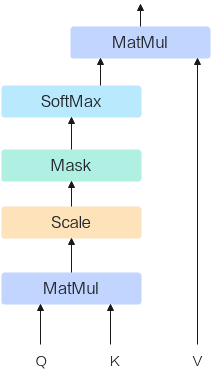
比如对于LLM大模型中最核心的一个融合算子Flash Attention, 其核心实现如下图。图中的MatMul算子(Cube)、Scale算子(Vector)、Mask算子(Vector)、SoftMax算子(Vector)融合为一个大的算子Flash Attention。
图1 Flash Attention核心实现
融合算子使用场景和优势
当对算子的性能要求较高时,可以通过融合算子编程的方式,将矢量算子和矩阵算子进行融合,通过一个算子kernel函数来承载,由此来获得性能上的收益。下图展示了独立矢量算子和矩阵算子、Mix融合算子的执行耗时对比,由此可以看出为什么开发Mix融合算子会带来性能上的收益。
图2 独立矢量算子和矩阵算子、Mix融合算子的执行耗时对比
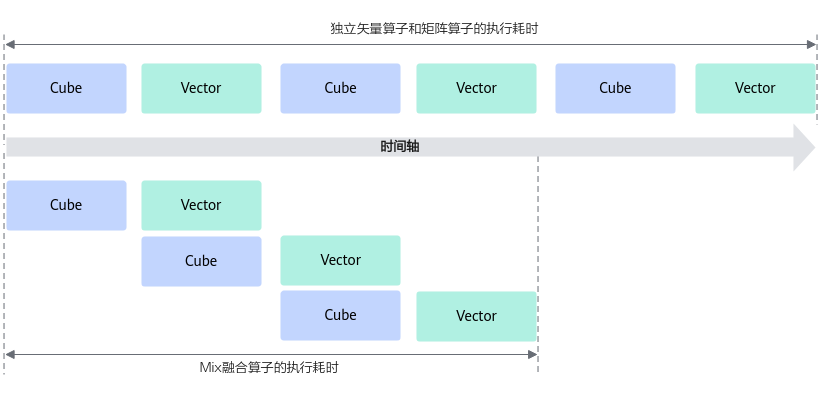
- 独立的矢量算子和矩阵算子实现:矩阵计算后的结果需要搬运到Global Memory上,然后由Global Memory搬运到LocalMemory,再进行矢量算子的计算,计算和搬运都是串行执行:另外多个算子的调度执行,会增加算子的调度耗时。
- 融合算子的实现方法:可以对数据进行切片,再通过流水的设计,使得矢量计算单元和矩阵计算单元实现并行计算;另外相比于不融合的单算子,减少了算子的调度耗时。
除了有效提升算子性能,充分发挥AI处理器的算力,融合算子还有如下优势:
- 减少计算量:融合算子可以将多个算子合并为一个,简化计算过程,减少计算量,提高计算效率。
- 减少内存占用:融合算子可以将多个算子的中间结果合并为一个,从而减少内存占用,提高内存利用率。
- 优化数据流:融合算子可以优化数据流,减少数据在不同算子之间的传输,从而提高数据处理效率。
- 简化代码实现:融合算子可以简化代码实现,减少代码量,提高代码可读性和可维护性。
总之,融合算子是一种优化计算的有效手段,可以提高计算效率和内存利用率,优化数据流,简化代码实现。
编程范式
Ascend C提供融合算子的编程范式,方便开发者基于该范式表达融合算子的数据流,快速实现自己的融合算子。
融合算子数据流指融合算子的输入输出在各存储位置间的流向。以一个典型的Cube和Vector融合算子为例,逻辑位置间的数据流向如下图所示:
- Cube的输出可以作为Vector的输入:CO2->VECIN
- Vector的输出可以作为Cube的输入:VECOUT->A1->A2、VECOUT->B1->B2
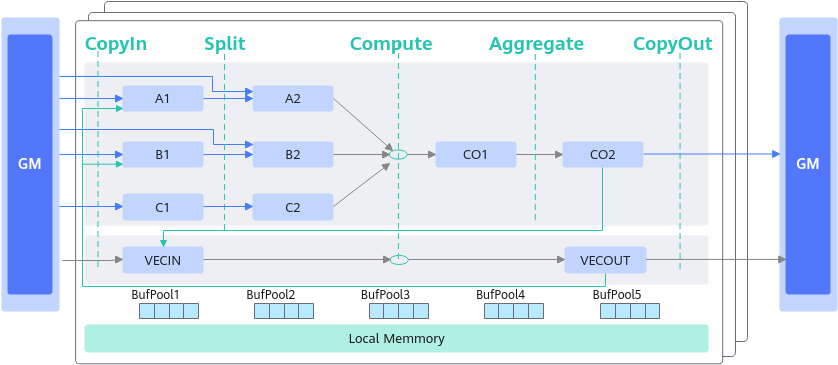
基于Matmul高阶API的融合算子编程范式,对上述数据流简化表达如下:
图3 融合算子编程范式
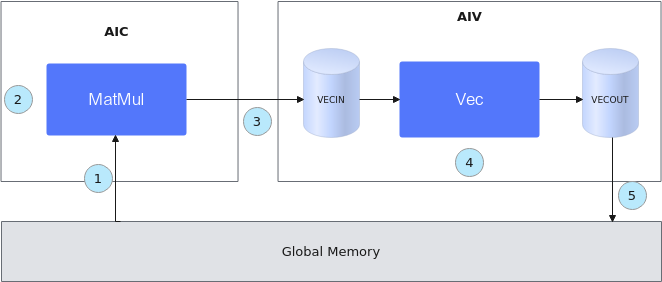
- 初始化一个MatMul对象,将输入数据从Global Memory搬运到Cube核上。
- 进行MatMul内部的计算。
- 将MatMul的计算结果搬运到Vector核上。
- 进行Vector矢量计算。
- 将输出结果搬运到Global Memory上。
整个过程的示例代码如下(伪代码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | template<typename aType, typename bType, typename cType, typename biasType> __aicore__ inline void MatmulLeakyKernel<aType, bType, cType, biasType>::Process() { // 步骤1:初始化一个MatMul对象,将输入数据从Global Memory搬运到Cube核上。 uint32_t computeRound = 0; REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), matmulObj); matmulObj.Init(&tiling); matmulObj.SetTensorA(aGlobal); matmulObj.SetTensorB(bGlobal); matmulObj.SetBias(biasGlobal); while (matmulObj.template Iterate<true>()) { // 步骤2:进行MatMul内部的计算。 // 步骤3:将MatMul的计算结果搬运到Vector核上。 reluOutLocal = reluOutQueue_.AllocTensor<cType>(); matmulObj.template GetTensorC<true>(reluOutLocal, false, true); // 步骤4:进行Vector矢量计算。 AscendC::LeakyRelu(reluOutLocal, reluOutLocal, (cType)alpha, tiling.baseM * tiling.baseN); reluOutQueue_.EnQue(reluOutLocal); // 步骤5:将输出结果搬运到Global Memory上 reluOutQueue_.DeQue<cType>(); ... AscendC::DataCopy(cGlobal[startOffset], reluOutLocal, copyParam); reluOutQueue_.FreeTensor(reluOutLocal); computeRound++; } matmulObj.End(); } |
父主题: 融合算子编程