TIK数据搬运
接口原型
对于Vector计算,一般是用Unified Buffer去存放数据,再进行计算,所以整体数据流应该是从Global Memory>Unified Buffer>Global Memory。TIK提供了data_move接口实现Global Memory和Unified Buffer间的数据搬运,函数原型为:
data_move(dst, src, sid, nburst, burst, src_stride, dst_stride, *args, **argv)
在data_move的函数原型中,用户需要着重关注dst、src、nburst、burst、src_stride、dst_stride等6个参数。其中:
dst为目的操作数,也就是数据搬运的目的地址;src为源操作数,也就是数据搬运的起始地址;nburst表示需要执行的搬运次数;burst表示一次搬运的数据片段长度(单位为32Bytes);src_stride、dst_stride则分别代表源数据与目的数据的数据片段间隔(即前 burst 尾与后 burst 头的间隔)。
data_move支持连续地址与间隔地址两种搬运模式。
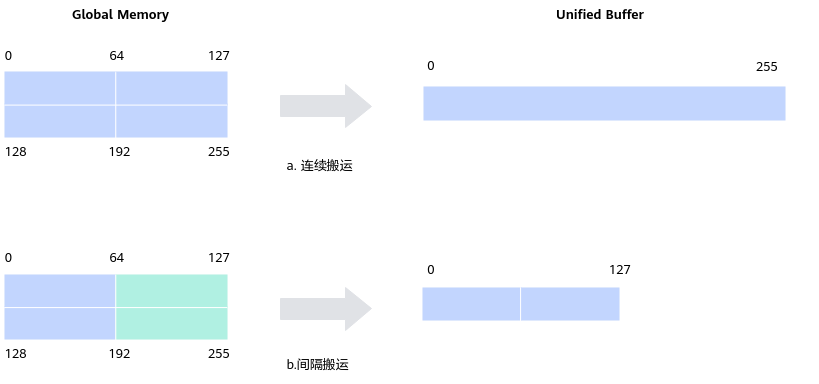
连续地址搬运
连续地址搬运是Tik算子开发中,最常见的数据搬运方式。
from tbe import tik
# 实例化tik_instance对象
tik_instance = tik.Tik()
# 定义一个在gm域的Tensor
data_input_gm = tik_instance.Tensor("int32", (256,), name="data_input_gm", scope=tik.scope_gm)
# 定义一个在ub域的Tensor
data_input_ub = tik_instance.Tensor("int32", (256,), name="data_input_ub", scope=tik.scope_ubuf)
# 使用data_move操作将输入的Tensor从gm搬到ub
tik_instance.data_move(data_input_ub, data_input_gm, 0, 1, 32, 0, 0)
# 对于ub进行一系列指令操作
.............
# 后续的搬出操作
在上述的案例中,我们首先分别在gm和ub空间开辟了一个256长度的,数据类型为int32的Tensor,然后我们执行从gm搬到ub的操作,数据搬运指令中几个参数的实际含义解释如下:
tik_instance.data_move(data_input_ub, data_input_gm, 0, 1, 32, 0, 0)
- 第1个参数dst:因为数据从gm搬到ub,所以目的Tensor就是data_input_ub;
- 第2个参数src:因为数据从gm搬到ub,所以源Tensor就是data_input_gm;
- 第3个参数sid:一般默认为0;
- 第4个参数nburst:源数据总大小是256个int32,每个int32大小为4Byte,即256*4=1024Byte,远小于UB大小,所以搬运一次即可,即nburst等于1。
- 第5个参数burst:连续传输数据片段的长度。一个片段(称之为Block)是32Byte,而源数据大小为1024Byte,所以总共需要1024 ÷ 32 = 32个Block,即连续传输数据的长度为32个片段。
- 第6个参数src_stride:因为是连续搬运,所以相邻搬运的数据片段前尾后头不需要间隔,填0(实际上仅搬运1次)。
- 第7个参数dst_stride:因为是连续搬运,所以相邻搬运的数据片段前尾后头不需要间隔,填0(实际上仅搬运1次)。
如下的数据搬运图所示,每个方块表示一个32Byte的Block,其中存放了8个int32,所以相当于是256个int32点对点进行搬运。

若输入数据较大,超过了UB的大小限制,此时需要将GM中的数据分多次搬入到UB进行计算,同样分多次搬出到GM。假设UB的可用存储空间为248KB,代码示例如下所示:
from tbe import tik
tik_instance = tik.Tik()
src_gm = tik_instance.Tensor("float16", (126976, 2), name="src_gm", scope=tik.scope_gm)
dst_gm = tik_instance.Tensor("float16", (126976, 2), name="dst_gm", scope=tik.scope_gm)
dst_ub = tik_instance.Tensor("float16", (126976, ), name="dst_ub", scope=tik.scope_ubuf)
with tik_instance.for_range(0, 2) as i:
# gm数据超过ub最大内存,先搬运一部分到ub进行计算,完成之后再搬回gm,可多次重复
tik_instance.data_move(dst_ub, src_gm[i*126976], 0, 1, 7936, 0, 0)
with tik_instance.for_range(0, 3) as j:
# repeat_times最大为255 一次无法全部计算完,可以分多次计算,此处为节省空间src和dst 为同一个ub
tik_instance.vec_add(128, dst_ub[j*128*255], dst_ub[j*128*255], dst_ub[j*128*255], 255, 8, 8, 8)
tik_instance.vec_add(128, dst_ub[3 * 128 * 255], dst_ub[3 * 128 * 255], dst_ub[3 * 128 * 255], 227, 8, 8, 8)
# 将计算好的数据搬回至gm,再计算另外剩余的数据
tik_instance.data_move(dst_gm[i*126976], dst_ub, 0, 1, 7936, 0, 0)
tik_instance.BuildCCE(kernel_name="data_move", inputs=[src_gm], outputs=[dst_gm])

- 本示例中,vec_add的两个源操作数以及目的操作数在UB中都使用相同的Tensor,即地址完全重叠。
- TIK的数据搬运以及计算都是按照一维数据进行处理的。
- GM中输入数据的大小为496KB(126976*2*2/1024),超出了可用UB的空间大小。所以考虑分两次(496KB/248KB = 2)搬运到UB中,即如下语句:
with tik_instance.for_range(0, 2) as i
- 每次搬运的数据大小为248KB,一次即可搬完,所以data_move指令中nburst设置为1即可。由于传输片段的单位是32Byte,即一个Block,所以一次需要传输248*1024/32 = 7936个Block,所以burst设置为7936,如下所示:
tik_instance.data_move(dst_ub, src_gm[i*126976], 0, 1, 7936, 0, 0)
- 由于Vector一次最多可计算256Byte的数据,计算的重复迭代次数最大为255次,所以一次循环计算最多可处理256*255 = 65280 Byte的数据,从而得出一次搬运的数据需要分 248*1024/65280 = 3.89...次循环进行计算。
前3次循环计算按最多数据量(65280Byte)处理,最后一次处理剩余的58112Byte的数据,58112Byte的数据需要重复227次(58112/256 = 227)。
with tik_instance.for_range(0, 3) as j: # 前三次计算,每次计算都处理256*255Byte的数据,即128*255个float16的数据。此处为节省空间src和dst 为同一个ub tik_instance.vec_add(128, dst_ub[j*128*255], dst_ub[j*128*255], dst_ub[j*128*255], 255, 8, 8, 8) # 最后一次计算,处理剩余数据,剩余数据需要重复227迭代进行计算 tik_instance.vec_add(128, dst_ub[3 * 128 * 255], dst_ub[3 * 128 * 255], dst_ub[3 * 128 * 255], 227, 8, 8, 8) - 最后,将计算好的数据搬出到GM,再执行下一次循环,进行剩余数据的处理即可。
间隔地址搬运
上述表示了连续的数据搬运,其中src_stride和dst_stride都是0,非连续的数据搬运的场景则稍显复杂。
from tbe import tik
tik_instance = tik.Tik()
data_input_gm = tik_instance.Tensor("int32", (256,), name="data_input_gm", scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("int32", (176,), name="data_input_ub", scope=tik.scope_ubuf)
# 非连续搬运的案例
tik_instance.data_move(data_input_ub, data_input_gm, 0, 4, 4, 4, 2)
.............
- 第4个参数nburst:传输4段数据片段;
- 第5个参数burst:每个数据片段都需要连续传输4个Block,相当于一次只传输32个int32;
- 第6个参数src_stride:相邻搬运的数据片段前尾后头间隔4个Block,相当于间隔32个int32;
- 第7个参数dst_stride:相邻搬运的数据片段前尾后头间隔2个Block,相当于间隔16个int32;
如下的数据搬运图可以直观地表示这样的搬运过程:

间隔地址搬运场景比较少见,经常使用的还是连续地址搬运的场景,平常写算子的时候,也不会在burst上直接写数字,而是用:element_size_to_move * DATA_TYPE_SIZE / BLOCK_SIZE_BYTE 去表示:
tik_instance.data_move(data_input_ub, data_input_gm, SID, DEFAULT_NBURST,
element_size_to_move * DATA_TYPE_SIZE // BLOCK_SIZE_BYTE,
STRIDE_ZERO, STRIDE_ZERO)
其中DEFAULT_NBURST=1,BLOCK_SIZE_BYTE=32,STRIDE_ZERO=0。这样其他用户在阅读TIK算子代码的时候,其中参数的含义会比单纯的数字更加简明易懂。
有偏移的连续地址搬运
在实际的开发过程中也会出现从Tensor某一位置搬运的场景,此时可以有如下的data_move使用方式:
from tbe import tik
tik_instance = tik.Tik()
data_input_gm = tik_instance.Tensor("int32", (256,), name="data_input_gm", scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("int32", (256,), name="data_input_ub", scope=tik.scope_ubuf)
# 有offset的连续数据搬运
tik_instance.data_move(data_input_ub[8], data_input_gm[16], 0, 1, 30, 0, 0)
.............
由数据搬运图可见,总共需要搬运30个Block,但是src是从第3个Block开始搬运,即第16个int32开始搬运,然后将30个Block依次搬到dst第2个开始的Block中,即第8个int32开始填入。

- 由于不同昇腾AI处理器的架构稍有不同,所以对于搬运地址的要求也不同(参考表2),有的需要ub地址32Byte对齐,有的不需要。当ub需要32Byte对齐时,即从ub中读取或者写入的起始地址会根据数据类型的不同,必须是4或者8的倍数,如对于数据类型int32,一个Block记录了8个int32,则ub Tensor起始地址必须是8的倍数,又如int16起始地址必须是16的倍数等等。
- 所有型号的昇腾AI处理器对于gm都不要求起始地址32Byte对齐。但当输入数据不满足32Byte对齐的场景时,为保证计算结果的准确性,针对尾块数据,可采用数据回退的方式,将数据回退为满足32Byte,然后再搬运UB,计算完成后,再采用相同的方式搬回gm。
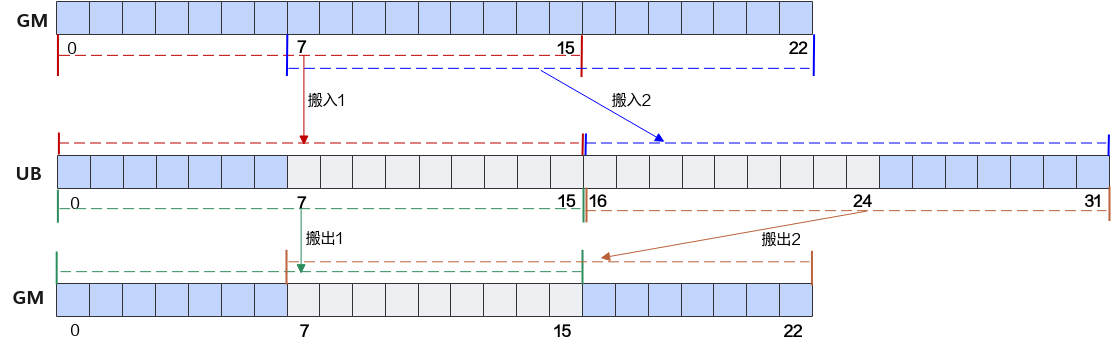
如图2所示,输入数据为23个类型是float16的数据。
数据从GM搬运到UB的场景:数据从UB搬运到GM的场景:代码示例如下所示:from tbe import tik tik_instance = tik.Tik() src_gm = tik_instance.Tensor("float16", (23, ), name="src_gm", scope=tik.scope_gm) dst_gm = tik_instance.Tensor("float16", (23, ), name="dst_gm", scope=tik.scope_gm) src_ub = tik_instance.Tensor("float16", (32, ), name="src_ub", scope=tik.scope_ubuf) dst_ub = tik_instance.Tensor("float16", (32, ), name="dst_ub", scope=tik.scope_ubuf) tik_instance.vec_dup(32, src_ub, 0, 1, 1) tik_instance.vec_dup(32, dst_ub, 0, 1, 1) with tik_instance.for_range(0, 2) as i: # 可以进行两次搬运,第一次32Byte对齐搬运,第二次数据前移再按照32Byte对齐方式搬运到ub tik_instance.data_move(src_ub[i*16], src_gm[i*(23-16)], 0, 1, 1, 0, 0) tik_instance.vec_add(32, dst_ub, src_ub, src_ub, 1, 1, 1, 1) # ub -> gm 采取相同搬运方式,第一次搬运32Byte的数据到gm;第二次将gm进行地址回退,满足32Byte对齐后,存储剩余ub中的数据 with tik_instance.for_range(0, 2) as i: tik_instance.data_move(dst_gm[i*(23-16)], dst_ub[i*16], 0, 1, 1, 0, 0) tik_instance.BuildCCE(kernel_name="data_move", inputs=[src_gm], outputs=[dst_gm])
课后练习
请完成一个简单的TIK算子以实现基本的数据搬入搬出功能,要求如下:
- 在gm和ub中开辟一定大小的Tensor空间,要求空间尽量小,在保证正确的情况下尽量不要开辟无用的空间;
- 搬入部分:将129个fp16数据从gm搬到ub中,gm中需要从gm[2]地址开始连续读取,到ub中的排布方式是每搬完16个fp16后,再间隔16个fp16进行写入;
- 搬出部分:将127个int32数据从ub搬到gm中,其中ub要从ub[32]开始搬运,每搬完16个int32后,再间隔32个int32进行搬运,搬到gm中需要连续写入。
注:假设ub的起始地址需要32B对齐。
【参考答案】:
from tbe import tik
tik_instance = tik.Tik()
data_input_gm = tik_instance.Tensor("float16", (146,), name="data_input_gm", scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("float16", (272,), name="data_input_ub", scope=tik.scope_ubuf)
tik_instance.data_move(data_input_ub, data_input_gm[2], 0, 9, 1, 0, 1)
.............
data_output_gm = tik_instance.Tensor("int32", (128,), name="data_output_gm", scope=tik.scope_gm)
data_output_ub = tik_instance.Tensor("int32", (384,), name="data_output_ub", scope=tik.scope_ubuf)
tik_instance.data_move(data_output_gm, data_output_ub[32], 0, 8, 2, 4, 0)
【解析】:
gm搬运到ub的场景:因为129个fp16,每个Block能搬运16个fp16,所以需要搬运9个Block,因为gm从索引为2的数据开始连续搬运,且没有起始地址对齐的限制,所以gm的大小为9 * 16 + 2 = 146;因为ub是搬16个空16个,最后一个空的16个可以不分配空间,所以ub大小为9 * (16+16) - 16 = 272。每次搬1个Block,burst=1,且总共搬9个Block所以需要搬运9次,nburst=9。src端连续,src_stride=0,dst端前尾后头空16个fp16也就是1个Block,dst_stride=1,所以data_move中的参数分别是9, 1, 0, 1。
ub搬运到gm的场景:因为127个int32,每个Block能搬运8个int32,所以需要搬运16个Block,gm大小直接给成16 * 8 = 128即可;因为ub需要搬16个空32个,然后又从32地址开始搬,所以ub大小为8 * (16+32) - 32 + 32= 384。每次搬16个int32,所以每次搬2个Block,burst=2,且总共搬16个Block所以需要搬8次,nburst=8。src端前尾后头空32个int32也就是4个Block,src_stride=4,dst端连续,dst_stride=0,所以data_move中的参数分别是8, 2, 4, 0。