'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
torch_npu.npu_fusion_attention
功能描述
实现“Transformer Attention Score”的融合计算,实现的计算公式如下:
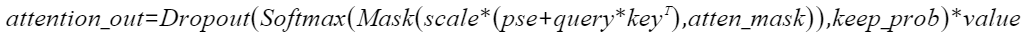
接口原型
torch_npu.npu_fusion_attention(Tensor query, Tensor key, Tensor value, int head_num, str input_layout, Tensor? pse=None, Tensor? padding_mask=None, Tensor? atten_mask=None, float scale=1., float keep_prob=1., int pre_tockens=2147483647, int next_tockens=2147483647, int inner_precise=0, int[]? prefix=None, int[]? actual_seq_qlen=None, int[]? actual_seq_kvlen=None, int sparse_mode=0, bool gen_mask_parallel=True, bool sync=False) -> (Tensor, Tensor, Tensor, Tensor, int, int, int)
参数说明
- query:Device侧的Tensor,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。综合约束请见约束说明。
- key:Device侧的Tensor,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。综合约束请见约束说明。
- value:Device侧的Tensor,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。综合约束请见约束说明。
- head_num:Host侧的int,代表head个数,数据类型支持INT64。综合约束请见约束说明。
- input_layout:Host侧的string,代表输入query、key、value的数据排布格式,支持BSH、SBH、BSND、BNSD、TND(actual_seq_qlen/actual_seq_kvlen需传值);后续章节如无特殊说明,S表示query或key、value的sequence length,Sq表示query的sequence length,Skv表示key、value的sequence length,SS表示Sq*Skv。
- pse:Device侧的Tensor,可选参数,表示位置编码。数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。非varlen场景支持四维输入,包含BNSS格式、BN1Skv格式、1NSS格式。如果非varlen场景Sq大于1024或varlen场景、每个batch的Sq与Skv等长且是sparse_mode为0、2、3的下三角掩码场景,可使能alibi位置编码压缩,此时只需要输入原始PSE最后1024行进行内存优化,即alibi_compress = ori_pse[:, :, -1024:, :],参数每个batch不相同时,输入BNHSkv(H=1024),每个batch相同时,输入1NHSkv(H=1024)。
- padding_mask:Device侧的Tensor,暂不支持该参数。
- atten_mask:Device侧的Tensor,可选参数,取值为1代表该位不参与计算(不生效),为0代表该位参与计算,数据类型支持BOOL、UINT8,数据格式支持ND格式,输入shape类型支持BNSS格式、B1SS格式、11SS格式、SS格式。varlen场景只支持SS格式,SS分别是maxSq和maxSkv。综合约束请见约束说明。
- scale:Host侧的double,可选参数,代表缩放系数,作为计算流中Muls的scalar值,数据类型支持DOUBLE,默认值为1。
- keep_prob:Host侧的double,可选参数,代表Dropout中1的比例,数据类型支持DOUBLE,默认值为1,表示全部保留。
- pre_tockens:Host侧的int,用于稀疏计算的参数,可选参数,数据类型支持INT64,默认值为2147483647。综合约束请见约束说明。
- next_tockens:Host侧的int,用于稀疏计算的参数,可选参数,数据类型支持INT64,默认值为2147483647。next_tockens和pre_tockens取值与atten_mask的关系请参见sparse_mode参数,参数取值与atten_mask分布不一致会导致精度问题。综合约束请见约束说明。
- inner_precise:Host侧的int,用于提升精度,数据类型支持INT64,默认值为0。
说明:当前0、1为保留配置值,2为使能无效行计算,其功能是避免在计算过程中存在整行mask进而导致精度有损失,但是该配置会导致性能下降。
如果算子可判断出存在无效行场景,会自动使能无效行计算,例如sparse_mode为3,Sq > Skv场景。
- prefix:Host侧的int array,可选参数,代表prefix稀疏计算场景每个Batch的N值。数据类型支持INT64,数据格式支持ND。综合约束请见约束说明。
- actual_seq_qlen:Host侧的int array,可选参数,varlen场景时需要传入此参数。表示query每个S的累加和长度,数据类型支持INT64,数据格式支持ND。综合约束请见约束说明。
比如真正的S长度列表为:2 2 2 2 2
则actual_seq_qlen传:2 4 6 8 10
- actual_seq_kvlen:Host侧的int array,可选参数,varlen场景时需要传入此参数。表示key/value每个S的累加和长度。数据类型支持INT64,数据格式支持ND。综合约束请见约束说明。
比如真正的S长度列表为:2 2 2 2 2
则actual_seq_kvlen传:2 4 6 8 10
- sparse_mode:Host侧的int,表示sparse的模式,可选参数。数据类型支持:INT64,默认值为0,支持配置值为0、1、2、3、4、5、6、7、8。当整网的atten_mask都相同且shape小于2048*2048时,建议使用defaultMask模式,来减少内存使用量。综合约束请见约束说明。
表1 sparse_mode不同取值场景说明 sparse_mode
含义
备注
0
defaultMask模式。
-
1
allMask模式。
-
2
leftUpCausal模式。
-
3
rightDownCausal模式。
-
4
band模式。
-
5
prefix非压缩模式。
varlen场景不支持。
6
prefix压缩模式。
-
7
varlen外切场景,rightDownCausal模式。
仅varlen场景支持。
8
varlen外切场景,leftUpCausal模式。
仅varlen场景支持。
atten_mask的工作原理为,在Mask为True的位置遮蔽query(Q)与key(K)的转置矩阵乘积的值,示意如下:
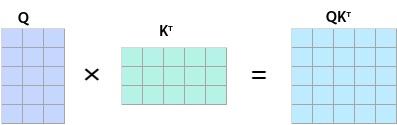
QKT矩阵在atten_mask为True的位置会被遮蔽,效果如下:
 说明:下图中的蓝色表示保留该值,atten_mask中,应该配置为False;阴影表示遮蔽该值,atten_mask中应配置为True。
说明:下图中的蓝色表示保留该值,atten_mask中,应该配置为False;阴影表示遮蔽该值,atten_mask中应配置为True。- sparse_mode为0时,代表defaultMask模式。
- 不传mask:如果atten_mask未传入则不做mask操作,atten_mask取值为None,忽略pre_tockens和next_tockens取值。Masked QKT矩阵示意如下:

- next_tockens取值为0,pre_tockens大于等于Sq,表示causal场景sparse,atten_mask应传入下三角矩阵,此时pre_tockens和next_tockens之间的部分需要计算,Masked QKT矩阵示意如下:
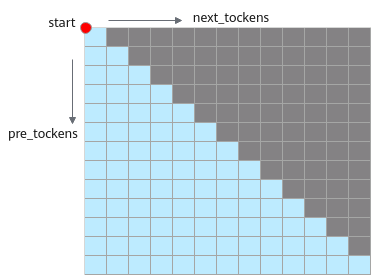
atten_mask应传入下三角矩阵,示意如下:

- pre_tockens小于Sq,next_tockens小于Skv,且都大于等于0,表示band场景,此时pre_tockens和next_tockens之间的部分需要计算。Masked QKT矩阵示意如下:
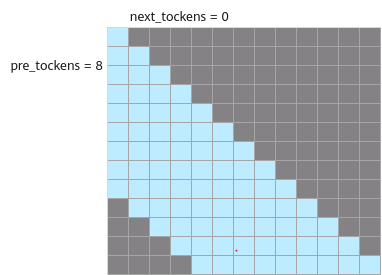
atten_mask应传入band形状矩阵,示意如下:

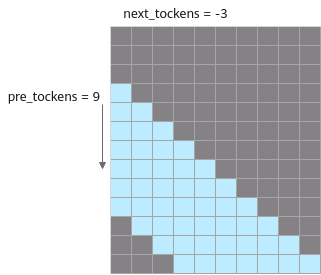
- next_tockens为负数,以pre_tockens=9,next_tockens=-3为例,pre_tockens和next_tockens之间的部分需要计算。Masked QKT示意如下:
说明:next_tockens为负数时,pre_tockens取值必须大于等于next_tockens的绝对值,且next_tockens的绝对值小于Skv。
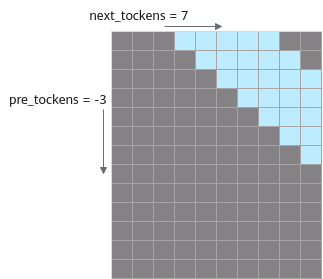
- pre_tockens为负数,以next_tockens=7,pre_tockens=-3为例,pre_tockens和next_tockens之间的部分需要计算。Masked QKT示意如下:
说明:pre_tockens为负数时,next_tockens取值必须大于等于pre_tockens的绝对值,且pre_tockens的绝对值小于Sq。
- 不传mask:如果atten_mask未传入则不做mask操作,atten_mask取值为None,忽略pre_tockens和next_tockens取值。Masked QKT矩阵示意如下:
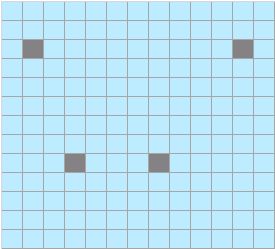
- sparse_mode为1时,代表allMask,即传入完整的atten_mask矩阵。
该场景下忽略next_tockens、pre_tockens取值,Masked QKT矩阵示意如下:
- sparse_mode为2时,代表leftUpCausal模式的mask,对应以左上顶点划分的下三角场景(参数起点为左上角)。该场景下忽略pre_tockens、next_tockens取值,Masked QKT矩阵示意如下:
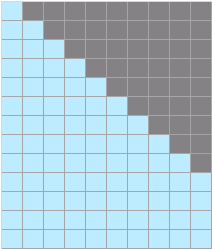
传入的atten_mask为优化后的压缩下三角矩阵(2048*2048),压缩下三角矩阵示意(下同):

- sparse_mode为3时,代表rightDownCausal模式的mask,对应以右下顶点划分的下三角场景(参数起点为右下角)。该场景下忽略pre_tockens、next_tockens取值。atten_mask为优化后的压缩下三角矩阵(2048*2048),Masked QKT矩阵示意如下:
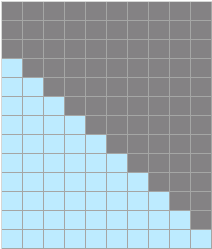
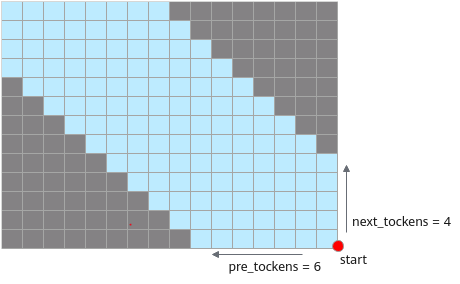
- sparse_mode为4时,代表band场景,即计算pre_tockens和next_tockens之间的部分,参数起点为右下角,pre_tockens和next_tockens之间需要有交集。atten_mask为优化后的压缩下三角矩阵(2048*2048)。Masked QKT矩阵示意如下:
- sparse_mode为5时,代表prefix非压缩场景,即在rightDownCasual的基础上,左侧加上一个长为Sq,宽为N的矩阵,N的值由可选输入prefix获取,例如下图中表示batch=2场景下prefix传入数组[4,5],每个batch轴的N值可以不一样,参数起点为左上角。
该场景下忽略pre_tockens、next_tockens取值,atten_mask矩阵数据格式须为BNSS或B1SS,Masked QKT矩阵示意如下:

atten_mask应传入矩阵示意如下:

- sparse_mode为6时,代表prefix压缩场景,即prefix场景时,attenMask为优化后的压缩下三角+矩形的矩阵(3072*2048):其中上半部分[2048,2048]的下三角矩阵,下半部分为[1024,2048]的矩形矩阵,矩形矩阵左半部分全0,右半部分全1,atten_mask应传入矩阵示意如下。该场景下忽略pre_tockens、next_tockens取值。
- sparse_mode为7时,表示varlen且为长序列外切场景(即长序列在模型脚本中进行多卡切query的sequence length);用户需要确保外切前为使用sparse_mode 3的场景;当前mode下用户需要设置pre_tockens和next_tockens(起点为右下顶点),且需要保证参数正确,否则会存在精度问题。
Masked QKT矩阵示意如下,在第二个batch对query进行切分,key和value不切分,4x6的mask矩阵被切分成2x6和2x6的mask,分别在卡1和卡2上计算:
- 卡1的最后一块mask为band类型的mask,配置pre_tockens=6(保证大于等于最后一个Skv),next_tockens=-2,actual_seq_qlen应传入{3,5},actual_seq_kvlen应传入{3,9}。
- 卡2的mask类型切分后不变,sparse_mode为3,actual_seq_qlen应传入{2,7,11},actual_seq_kvlen应传入{6,11,15}。


- 如果配置sparse_mode=7,但实际只存在一个batch,用户需按照band模式的要求来配置参数;sparse_mode=7时,用户需要输入2048x2048的下三角mask作为该融合算子的输入。
- 基于sparse_mode=3进行外切产生的band模式的sparse的参数应符合以下条件:
- pre_tockens >= last_Skv。
- next_tockens <= 0。
- 当前模式下不支持可选输入pse。
- sparse_mode为8时,表示varlen且为长序列外切场景;用户需要确保外切前为使用sparse_mode 2的场景;当前mode下用户需要设置pre_tockens和next_tockens(起点为右下顶点),且需要保证参数正确,否则会存在精度问题。
Masked QKT矩阵示意如下,在第二个batch对query进行切分,key和value不切分,5x4的mask矩阵被切分成2x4和3x4的mask,分别在卡1和卡2上计算:
- 卡1的mask类型切分后不变,sparse_mode为2,actual_seq_qlen应传入{3,5},actual_seq_kvlen应传入{3,7}。
- 卡2的第一块mask为band类型的mask,配置pre_tockens=4(保证大于等于第一个Skv),next_tockens=1,actual_seq_qlen应传入{3,8,12},actual_seq_kvlen应传入{4,9,13}。

- 如果配置sparse_mode=8,但实际只存在一个batch,用户需按照band模式的要求来配置参数;sparse_mode=8时,用户需要输入2048x2048的下三角mask作为该融合算子的输入。
- 基于sparse_mode=2进行外切产生的band模式的sparse的参数应符合以下条件:
- pre_tockens >= first_Skv。
- next_tockens范围无约束,根据实际情况进行配置。
- 当前模式下不支持可选输入pse。
- sparse_mode为0时,代表defaultMask模式。
- gen_mask_parallel:debug参数,DSA生成dropout随机数向量mask的控制开关,默认值为True:同AICORE计算并行,False:同AICORE计算串行。
- sync:debug参数,DSA生成dropout随机数向量mask的控制开关,默认值为False:dropout mask异步生成,True:dropout mask同步生成。

输出说明
共7个输出
(Tensor, Tensor, Tensor, Tensor, int, int, int)
- 第1个输出为Tensor,计算公式的最终输出y,数据类型支持:FLOAT16、BFLOAT16。
- 第2个输出为Tensor,Softmax 计算的Max中间结果,用于反向计算,数据类型支持:FLOAT。
- 第3个输出为Tensor,Softmax计算的Sum中间结果,用于反向计算,数据类型支持:FLOAT。
- 第4个输出为Tensor,保留参数,暂未使用。
- 第5个输出为int,DSA生成dropoutmask中,Philox算法的seed。
- 第6个输出为int,DSA生成dropoutmask中,Philox算法的offset。
- 第7个输出为int,DSA生成dropoutmask的长度。
约束说明
- 输入query、key、value的B:batchsize必须相等,取值范围1~2K。
- 输入query、key、value、pse的数据类型必须一致。
- 输入query、key、value的input_layout必须一致。
- 支持输入query的N和key/value的N不相等,但必须成比例关系,即Nq/Nkv必须是非0整数,Nq取值范围1~256。当Nq/Nkv > 1时,即为GQA(grouped-query attention);当Nkv=1时,即为MQA(multi-query attention)。本文如无特殊说明,N表示的是Nq。
- 输入key/value的shape必须一致。
- 输入query、key、value的S:sequence length,取值范围1~512K。
- 输入query、key、value的D:head dim,取值范围1~512。
- varlen场景T(B*S)取值范围1~512K。
- keep_prob的取值范围为(0, 1] 。
- sparse_mode为1、2、3、4、5、6、7、8时,应传入对应正确的atten_mask,否则将导致计算结果错误。当atten_mask输入为None时,sparse_mode,pre_tockens,next_tockens参数不生效,固定为全计算。
- sparse_mode配置为1、2、3、5、6时,用户配置的pre_tockens、next_tockens不会生效。
- sparse_mode配置为0、4时,须保证atten_mask与pre_tockens、next_tockens的范围一致。
- prefix稀疏计算场景B不大于32,varlen场景不支持非压缩prefix,即不支持sparse_mode=5;当Sq>Skv时,prefix的N值取值范围[0, Skv],当Sq<=Skv时,prefix的N值取值范围[Skv-Sq, Skv]。
- sparse_mode=7或者8时,不支持可选输入pse。
- varlen场景:
- atten_mask输入不支持补pad,即atten_mask中不能存在某一行全1的场景。
- pse仅支持alibi场景,即shape为BNHSkv(H=1024)、1NHSkv(H=1024)两种场景。
- 支持actual_seq_qlen中某个Batch上的S长度为0;如果存在S为0的情况,不支持pse输入, 假设真实的S长度为[2,2,0,2,2],则传入的actual_seq_qlen为[2,4,4,6,8];不支持某个batch中Sq不为0,但是Skv为0的场景。
支持的PyTorch版本
- PyTorch 2.2
- PyTorch 2.1
- PyTorch 1.11.0
支持的型号
Atlas A2 训练系列产品
调用示例
import math
import unittest
import numpy as np
import torch
import torch_npu
from torch_npu.testing.testcase import TestCase, run_tests
from torch_npu.testing.common_utils import SupportedDevices
class TestNPUFlashAttention(TestCase):
def supported_op_exec(self, query, key, value, atten_mask):
scale = 0.08838
qk = torch.matmul(query, key.transpose(2, 3)).mul(scale)
qk = qk + atten_mask * (-10000.0)
softmax_res = torch.nn.functional.softmax(qk, dim=-1)
attention_out = torch.matmul(softmax_res, value)
return attention_out
def custom_op_exec(self, query, key, value, sparse_params):
scale = 0.08838
atten_mask = None
if sparse_params[0] == 0:
shape = [1, 8, 256, 256]
atten_mask_u = np.triu(np.ones(shape), k=sparse_params[1] + 1)
atten_mask_l = np.tril(np.ones(shape), k=-sparse_params[2] - 1)
atten_masks = atten_mask_u + atten_mask_l
atten_mask = torch.tensor(atten_masks).to(torch.float16).bool().npu()
if sparse_params[0] == 2 or sparse_params[0] == 3 or sparse_params[0] == 4:
atten_masks = torch.from_numpy(np.triu(np.ones([2048, 2048]), k=1))
atten_mask = torch.tensor(atten_masks).to(torch.float16).bool().npu()
return torch_npu.npu_fusion_attention(
query, key, value, head_num=8, input_layout="BNSD", scale=scale, sparse_mode=sparse_params[0],
atten_mask=atten_mask, pre_tockens=sparse_params[1], next_tockens=sparse_params[2])
def get_atten_mask(self, sparse_mode=0, pre_tokens=65536, next_tokens=65536):
atten_masks = []
shape = [1, 8, 256, 256]
if sparse_mode == 0:
atten_mask_u = np.triu(np.ones(shape), k=next_tokens + 1)
atten_mask_l = np.tril(np.ones(shape), k=-pre_tokens - 1)
atten_masks = atten_mask_u + atten_mask_l
elif sparse_mode == 1:
atten_masks = np.zeros(shape)
pre_tokens = 65536
next_tokens = 65536
elif sparse_mode == 2:
atten_masks = np.triu(np.ones(shape), k=1)
elif sparse_mode == 3:
atten_masks = np.triu(np.ones(shape), k=1)
elif sparse_mode == 4:
atten_mask_u = np.triu(np.ones(shape), k=next_tokens + 1)
atten_mask_l = np.tril(np.ones(shape), k=-pre_tokens - 1)
atten_masks = atten_mask_u + atten_mask_l
atten_mask = torch.tensor(atten_masks).to(torch.float16)
return atten_mask
# sparse_params = [sparse_mode, pre_tokens, next_tokens]
def check_result(self, query, key, value, sparse_params):
atten_mask = self.get_atten_mask(sparse_params[0], sparse_params[1], sparse_params[2])
output = self.supported_op_exec(query.float(), key.float(), value.float(), atten_mask)
fa_result = self.custom_op_exec(query.npu(), key.npu(), value.npu(), sparse_params)
self.assertRtolEqual(output.half(), fa_result[0], prec=0.01, prec16=0.01)
def test_npu_flash_attention(self, device="npu"):
query = torch.randn(1, 8, 256, 256, dtype=torch.float16)
key = torch.randn(1, 8, 256, 256, dtype=torch.float16)
value = torch.randn(1, 8, 256, 256, dtype=torch.float16)
# sparse_params: [sparse_mode, pre_tokens, next_tokens]
sparse_params_list = [
[0, 128, 128],
[1, 65536, 65536],
[2, 65536, 0],
[3, 65536, 0],
[4, 128, 128]
]
for sparse_params in sparse_params_list:
self.check_result(query, key, value, sparse_params)
if __name__ == "__main__":
run_tests()
