概述
MindSpeed是专为华为昇腾设备设计的大模型加速解决方案。在当前AI领域,大模型训练因其复杂性高、技术挑战多而备受关注。特别是在显存资源受限的情境下,如何高效地进行大模型训练成为业界关注的焦点。针对这一需求,MindSpeed应运而生,以其卓越的性能表现和深度优化的算法体系,助力用户在昇腾设备上高效实现大模型训练。
MindSpeed的优势
优势 |
说明 |
|---|---|
并行算法优化 |
支持模型并行、专家并行、序列并行等多维并行策略,针对昇腾软硬件架构进行亲和优化,显著提升了集群训练的性能和效率。 |
显存资源优化 |
提供内存压缩、复用,以及差异化的重计算技术,最大限度地利用显存资源,有效缓解显存瓶颈,提升训练效率。 |
通信性能优化 |
采用通算融合、通算掩盖等策略,配合高效的算网协同机制,大幅提高算力利用率,减少通信延迟,优化整体训练性能。 |
计算性能优化 |
集成高性能融合算子库,结合昇腾亲和的计算优化,充分释放昇腾算力,显著提升计算效率。 |
MindSpeed作为昇腾设备的专属加速解决方案,凭借其卓越的性能表现与深度优化的算法架构,为客户在AI领域实现大模型训练提供了强有力的支持。借助MindSpeed,用户能够充分挖掘并利用昇腾设备的高性能计算能力,加速大模型训练过程,从而在AI领域更快地实现价值。
软件架构
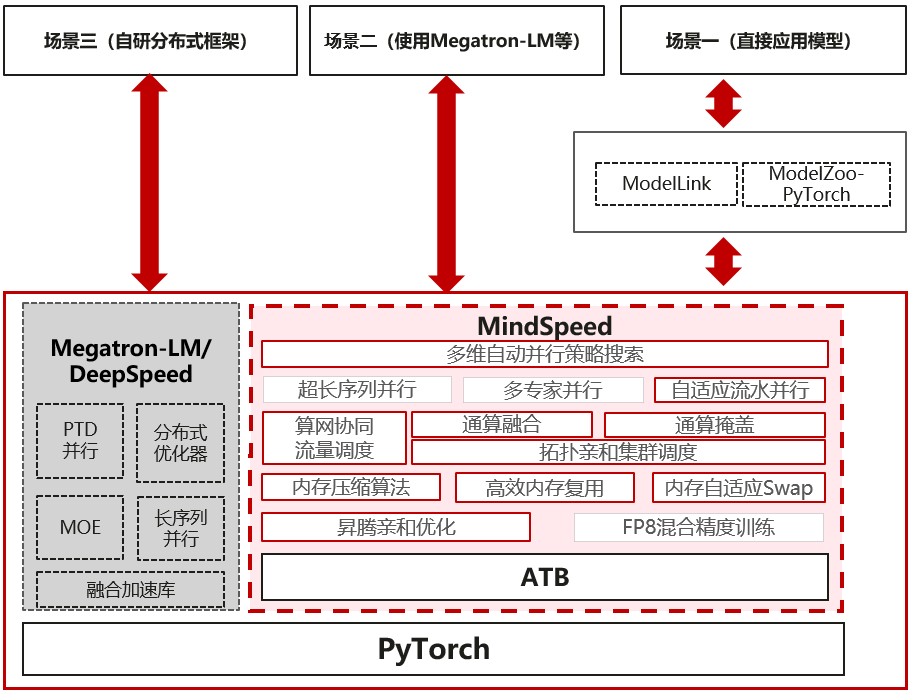
如图1所示,MindSpeed在昇腾的大模型训练性能加速体系中扮演着至关重要的角色,其架构设计旨在实现上下层级间的高效协同与优化。MindSpeed的软件架构不仅确保了与上层应用和下层框架的无缝对接,还集成了丰富的加速与优化技术,以满足大模型训练的高性能需求。
- 对接ModelLink模型仓:MindSpeed直接面向ModelLink模型仓,为用户提供一系列先进的SOTA(State-of-the-Art)模型的加速训练能力。这不仅简化了用户在大模型训练方面的操作流程,还显著提升了训练效率。
- 兼容原生Megatron-LM框架:除了ModelLink模型仓,MindSpeed还支持用户基于类Megatron-LM框架自行开发大模型,包括但不限于LLM(Large Language Model,大语言模型)和多模态大模型。用户可以利用MindSpeed所提供的计算、内存、通信和并行等优化技术,在昇腾上实现模型训练的加速。
下层框架对接
- AI框架集成:MindSpeed向下对接AI框架,通过丰富的API集,充分调动昇腾设备的计算与通信能力,确保资源的有效利用。
- 计算加速与内存优化:MindSpeed内部集成了多项计算加速和内存优化技术,包括但不限于算子融合、内存复用、缓存管理和高效数据布局,旨在最大化昇腾的计算效能和内存使用效率。
- 通信优化:针对大模型训练中常见的通信瓶颈,MindSpeed提供了通信优化技术,包括数据并行、模型并行和流水线并行等策略,以及高效的数据传输和通信调度机制,显著降低了通信延迟,提升了整体训练速度。
- 多维并行能力:MindSpeed具备完备的多维并行能力,包括数据并行、模型并行、专家并行和序列并行,为大模型训练提供了灵活的并行策略选择,以适应不同模型和应用场景的需求。
- 高性能融合算子库:针对大模型训练和推理场景,MindSpeed内置了高性能的融合算子库,通过算子融合技术,充分挖掘和利用昇腾设备的算力,提升执行效率。
适用场景
为满足不同用户的多样化需求,MindSpeed提供了多场景下的高效解决方案。本节将介绍MindSpeed在三种不同场景下的应用及其优势。
- 昇腾模型仓直接应用
对于希望快速部署并享受先进技术的用户,MindSpeed支持直接使用昇腾模型仓中已支持的模型。ModelLink中集成了丰富的SOTA(State-of-the-Art)大模型,用户可即拿即用,无需额外开发。通过MindSpeed的强大能力,这些模型在昇腾设备上展现出了卓越的训练性能,为用户提供了高效、稳定的解决方案。
- 开源框架Megatron-LM适配
对于使用开源大模型训练框架Megatron-LM的用户,MindSpeed通过插件化适配的方式,使原生Megatron-LM框架支持昇腾软硬件环境。用户只需进行简单的适配,即可使能MindSpeed提供的各类加速、优化技术,从而提升训练效率和模型性能。
- 自研分布式训练框架集成
对于使用自研的类Megatron-LM分布式训练框架的用户,MindSpeed同样提供了灵活的集成方案。通过集成MindSpeed中的关键特性,用户可以实现加速效果。MindSpeed中的各类特性相互独立、相互兼容,通过封装成独立的模块或API,为用户提供了方便的集成和优化途径。此外,MindSpeed采用开源开放策略,用户可直接获取MindSpeed源码,并根据自身需求进行源码修改和特性集成。