RotaryMul & RotaryMulGrad
算子基础信息
|
算子名称 |
RotaryMul & RotaryMulGrad |
|---|---|
|
torch_npu api接口 |
torch_npu.npu_rotary_mul(x, r1, r2) |
|
支持的torch_npu版本 |
1.11.0, 2.1.0, 2.2.0 |
|
支持的芯片类型 |
Atlas 训练系列产品,Atlas A2 训练系列产品 |
|
支持的数据类型 |
float16, bfloat16, float |
算子IR及torch_npu接口参数
算子IR:
REG_OP(RotaryMul)
.INPUT(x, TensorType({DT_FLOAT16, DT_FLOAT, DT_BFLOAT16}))
.INPUT(r1, TensorType({DT_FLOAT16, DT_FLOAT, DT_BFLOAT16}))
.INPUT(r2, TensorType({DT_FLOAT16, DT_FLOAT, DT_BFLOAT16}))
.OUTPUT(y, TensorType({DT_FLOAT16, DT_FLOAT, DT_BFLOAT16}))
.OP_END_FACTORY_REG(RotaryMul)
torch_npu接口:
torch_npu.npu_rotary_mul(x, r1, r2)
参数说明:
- x:q,k,shape要求输入为4维,一般为[B, N, S, D]或[B, S, N, D]或[S, B, N, D]。
- r1:cos值,shape要求输入为4维,一般为[1, 1, S, D]或[1, S, 1, D]或[S, 1, 1, D]。
- r2:sin值,shape要求输入为4维,一般为[1, 1, S, D]或[1, S, 1, D]或[S, 1, 1, D]。
模型中替换代码及算子计算逻辑
模型中替换代码:
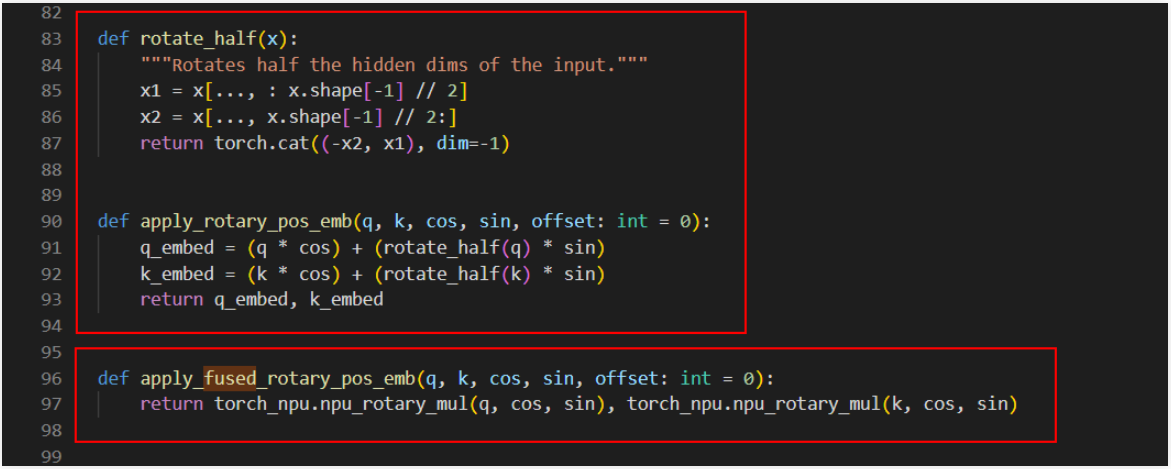
- 示例一
模型中替换代码截图参见图1,上方红框里的内容为模型源码,下方红框里的内容为替换的新接口。
q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
替换为:q = torch_npu.npu_rotary_mul(q, cos, sin) k = torch_npu.npu_rotary_mul(k, cos, sin)
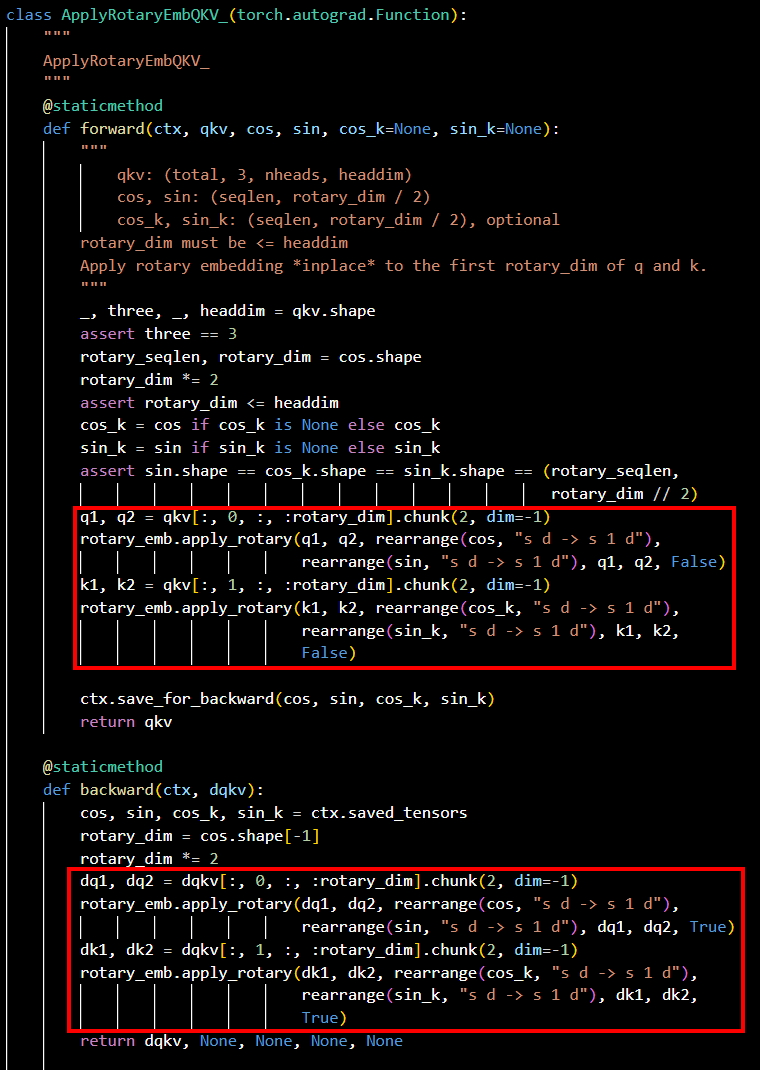
- 示例二
模型源码截图参见图2,红框里的内容为替换前的源码。
## forward q1, q2 = qkv[:, 0, :, :rotary_dim].chunk(2, dim=-1) rotary_emb.apply_rotary(q1, q2, rearrange(cos, "s d -> s 1 d"),rearrange(sin, "s d -> s 1 d"), q1, q2, False) k1, k2 = qkv[:, 1, :, :rotary_dim].chunk(2, dim=-1) rotary_emb.apply_rotary(k1, k2, rearrange(cos_k, "s d -> s 1 d"),rearrange(sin_k, "s d -> s 1 d"), k1, k2, False) ## backward dq1, dq2 = dqkv[:, 0, :, :rotary_dim].chunk(2, dim=-1) rotary_emb.apply_rotary(dq1, dq2, rearrange(cos, "s d -> s 1 d"),rearrange(sin, "s d -> s 1 d"), dq1, dq2, True) dk1, dk2 = dqkv[:, 1, :, :rotary_dim].chunk(2, dim=-1) rotary_emb.apply_rotary(dk1, dk2, rearrange(cos_k, "s d -> s 1 d"),rearrange(sin_k, "s d -> s 1 d"), dk1, dk2, True)
替换为:
## forward qkv[:, 0, :, :rotary_dim] = torch_npu.npu_rotary_mul(qkv[:, 0, :, :rotary_dim], cos, sin) qkv[:, 1, :, :rotary_dim] = torch_npu.npu_rotary_mul(qkv[:, 1, :, :rotary_dim], cos_k, sin_k) ## backward dqkv[:, 0, :, :rotary_dim] = -torch_npu.npu_rotary_mul(dqkv[:, 0, :, :rotary_dim], cos, sin) dqkv[:, 1, :, :rotary_dim] = -torch_npu.npu_rotary_mul(dqkv[:, 1, :, :rotary_dim], cos_k, sin_k)
算子的计算逻辑如下:
x1, x2 = torch.chunk(x, 2, -1) x_new = torch.cat((-x2, x1), dim=-1) output = r1 * x + r2 * x_new
图3 计算流程图
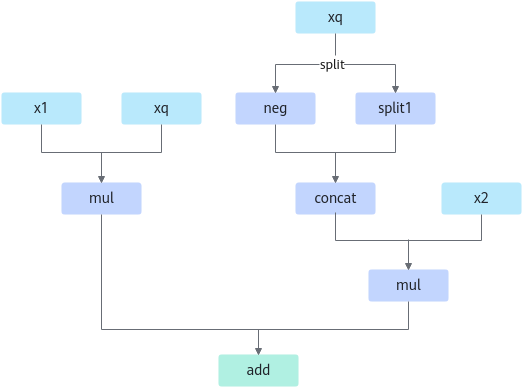
算子替换的模型中小算子

使用限制
目前算子仅支持r1、r2需要broadcast为x的shape的情形,且算子shape中最后一维D必须是128的倍数。
父主题: 融合算子替换