Nano-Pipe流水线并行
背景与挑战
流水线并行是AI大模型大规模分布式训练的关键组成部分之一,但其效率受到流水线中空泡的影响,为了提高吞吐量,需要降低其空泡比例。
解决方案
在大模型流水线调度中,反向的输入梯度和权重梯度通常是一起调度计算的,然而,通过分析他们计算的依赖关系,可以发现其实只有输入梯度的计算存在相互层间的依赖关系。因此,通过独立调度反向的输入梯度和权重梯度的计算,可以减少流水线调度的空泡。
图1 独立调度输入梯度和权重梯度的Nano-Pipe

图2 独立调度权重计算展示图
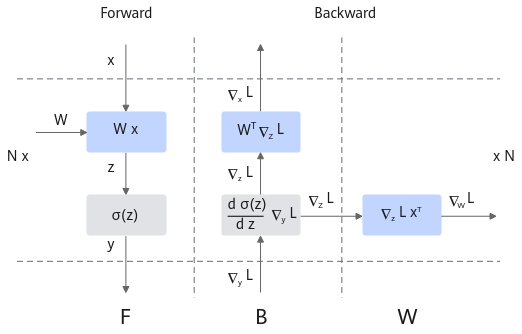
分离权重梯度计算流程,可通过修改RowParallelLinear和ColumnParallelLinear的backward实现,将对权重的梯度计算进行剥离,先存储在调度器上权重的梯度计算队列中。在需要对权重的梯度计算时,从调度器上权重的梯度计算队列中出队列一个计算,然后计算对应的梯度。
使用场景
在训练模型时,降低空泡的比例,从而提升计算效率,达到更好的流水线并行。
使用方法
- Nano-Pipe依赖于虚拟流水线并行。
--num-layers-per-virtual-pipeline-stage N
N表示每个虚拟流水线阶段的层数。
- 使能Nano-Pipe流水线并行。
--use-nanopipe
要求--pipeline-model-parallel-size大于2时进行设置,默认为False,根据用户需求配置。
使用效果
通过流水线并行,Nano-Pipe可以更快地处理大量的数据,提高数据处理的效率和准确性,提升计算的速度,减少空泡占比。
父主题: 流水线并行