Dump数据采集
概述
当训练网络精度未达预期时,可以通过采集训练过程中各算子的运算结果(即Data Dump数据),然后借助精度比对工具,和业界标准算子(如TensorFlow)运算结果进行数据偏差对比,从而帮助开发人员快速定位算子精度问题。当前支持采集的算子数据主要包括:
- input:dump算子的输入数据。
- output:dump算子的输出数据。
- all:同时dump算子的输入和输出数据。

默认训练过程中不采集算子的dump数据,如需采集并对数据进行分析,除了可以参考本节方法外,还可以参考整网数据比对进行一键式dump数据采集和分析,这种方法简化了采集和分析方法,更友好易用,推荐使用。
使用注意事项
- 当前支持采集所有迭代的dump数据,也支持用户指定dump的迭代数。在训练数据集较大的情况下,每次迭代的dump数据量很大(约几十G,甚至更多),建议控制迭代次数。
- 不能同时采集算子的dump数据和溢出检测数据,即不能同时开启enable_dump和enable_dump_debug。
- 支持采集AI Core、AI CPU和集合通信算子的dump数据。
- 建议在dump数据时,仅保留对计算过程的sess.run,删除不必要的sess.run代码,例如sess.run(global_step),否则可能出现dump异常。
Estimator模式下采集Dump数据
- 自动迁移场景
- 检查迁移后的脚本是否存在“init_resource”。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
if __name__ == '__main__': session_config = tf.ConfigProto(allow_soft_placement=True) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # enable_dump:是否开启Data Dump功能 custom_op.parameter_map["enable_dump"].b = True # dump_path:Dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限。 custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") # dump_step:指定采集哪些迭代的Dump数据 custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") # dump_mode:Dump模式,取值:input/output/all custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") # dump_layer:指定需要dump的算子,取值为算子名,多个算子名间用空格分隔。若不配置此参数,morendump全部算子。 custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") (npu_sess, npu_shutdown) = init_resource(config=session_config) tf.app.run() shutdown_resource(npu_sess, npu_shutdown) close_session(npu_sess)
需要注意,仅initialize_system中支持的配置项可在init_resource函数的config中进行配置,若需配置其他功能,请在npu_run_config_init函数的run_config中进行配置。
- 如果不存在,则直接执行下一步。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
- 在迁移后的脚本中查找“npu_run_config_init”,找到运行配置函数,例如示例中的“run_config”。
如果运行配置函数中未传入session_config参数,则需要按照下面示例添加;如果已经传入了session_config参数,则进行下一步。
1 2 3 4 5 6 7 8 9
session_config = tf.ConfigProto(allow_soft_placement=True) run_config = tf.estimator.RunConfig( train_distribute=distribution_strategy, session_config=session_config, save_checkpoints_secs=60*60*24) classifier = tf.estimator.Estimator( model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
- 修改session_config配置,添加Dump相关参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
session_config = tf.ConfigProto(allow_soft_placement=True) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = 'NpuOptimizer' # enable_dump:是否开启Data Dump功能 custom_op.parameter_map["enable_dump"].b = True # dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限 custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") # dump_step:指定采集哪些迭代的Dump数据 custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") # dump_mode:Dump模式,取值:input/output/all custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") # dump_layer:指定需要dump的算子,取值为算子名,多个算子名间用空格分隔。若不配置此参数,morendump全部算子。 custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") run_config = tf.estimator.RunConfig( train_distribute=distribution_strategy, session_config=session_config, save_checkpoints_secs=60*60*24) classifier = tf.estimator.Estimator( model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
- 检查迁移后的脚本是否存在“init_resource”。
- 手工迁移场景
Estimator模式下,通过NPURunConfig中的dump_config采集Dump数据,在创建NPURunConfig之前,实例化一个DumpConfig类进行dump的配置(包括配置dump路径、dump哪些迭代的数据、dump算子的输入还是输出数据等)。
关于DumpConfig类的构造函数中每个字段的详细解释,请参见精度比对。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from npu_bridge.npu_init import * # dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限。 # enable_dump:是否开启Data Dump功能 # dump_step:指定采集哪些迭代的Dump数据 # dump_mode:Dump模式,取值:input/output/all dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all") session_config=tf.ConfigProto(allow_soft_placement=True) config = NPURunConfig( dump_config=dump_config, session_config=session_config )
sess.run模式下采集Dump数据
- 自动迁移场景
- 检查迁移后的脚本是否存在“init_resource”。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
if __name__ == '__main__': session_config = tf.ConfigProto(allow_soft_placement=True) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # enable_dump:是否开启Data Dump功能 custom_op.parameter_map["enable_dump"].b = True # dump_path:Dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限。 custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") # dump_step:指定采集哪些迭代的Dump数据 custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") # dump_mode:Dump模式,取值:input/output/all custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") # dump_layer:指定需要dump的算子,取值为算子名,多个算子名间用空格分隔。若不配置此参数,morendump全部算子。 custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") (npu_sess, npu_shutdown) = init_resource(config=session_config) tf.app.run() shutdown_resource(npu_sess, npu_shutdown) close_session(npu_sess)
需要注意,仅initialize_system中支持的配置项可在init_resource函数的config中进行配置,若需配置其他功能,请在npu_config_proto函数的config_proto中进行配置。
- 如果不存在,则直接执行下一步。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
- 在迁移后的脚本中找到“npu_config_proto”,找到运行配置参数(例如下面示例中的“session_config”),在运行配置中添加Dump相关配置,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12
session_config = tf.ConfigProto(allow_soft_placement=True) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = 'NpuOptimizer' custom_op.parameter_map["enable_dump"].b = True custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") config = npu_config_proto(config_proto=session_config) with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) interaction_table.init.run()
- 检查迁移后的脚本是否存在“init_resource”。
- 手工迁移场景
sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode等配置参数进行Dump数据采集,详细参数说明可参见精度比对。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
config = tf.ConfigProto(allow_soft_placement=True) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["use_off_line"].b = True # enable_dump:是否开启Data Dump功能 custom_op.parameter_map["enable_dump"].b = True # dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限。 custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") # dump_step:指定采集哪些迭代的Dump数据 custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") # dump_mode:Dump模式,取值:input/output/all custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") # dump_layer:指定需要dump的算子,取值为算子名,多个算子名间用空格分隔。若不配置此参数,morendump全部算子。 custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.Session(config=config) as sess: print(sess.run(cost))
tf.keras模式修改
- 自动迁移场景
- 检查迁移后的脚本是否存在“init_resource”。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
if __name__ == '__main__': session_config = tf.ConfigProto(allow_soft_placement=True) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # enable_dump:是否开启Data Dump功能 custom_op.parameter_map["enable_dump"].b = True # dump_path:Dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限。 custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") # dump_step:指定采集哪些迭代的Dump数据 custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") # dump_mode:Dump模式,取值:input/output/all custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") # dump_layer:指定需要dump的算子,取值为算子名,多个算子名间用空格分隔。若不配置此参数,morendump全部算子。 custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") (npu_sess, npu_shutdown) = init_resource(config=session_config) tf.app.run() shutdown_resource(npu_sess, npu_shutdown) close_session(npu_sess)
需要注意,仅initialize_system中支持的配置项可在init_resource函数的config中进行配置,若需配置其他功能,请在“set_keras_session_npu_config”函数的config中进行配置。
- 如果不存在,则直接执行下一步。
- 如果存在,则需要参考下面示例,在init_resource函数中传入config配置。
- 在脚本中找到“set_keras_session_npu_config”,找到运行配置,例如config_proto,然后在运行配置中添加Dump相关配置,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import tensorflow as tf import tensorflow.python.keras as keras from tensorflow.python.keras import backend as K from npu_bridge.npu_init import * config_proto = tf.ConfigProto(allow_soft_placement=True) custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = 'NpuOptimizer' custom_op.parameter_map["enable_dump"].b = True custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") npu_keras_sess = set_keras_session_npu_config(config=config_proto) #数据预处理... #模型搭建... #模型编译... #模型训练...
- 检查迁移后的脚本是否存在“init_resource”。
- 手工迁移场景
与sess.run的手工迁移场景配置方式类似,请参见sess.run模式下采集Dump数据。
分布式场景下在指定的RANK上采集Dump数据
分布式的数据并发场景下,如果需要减少dump数据量,可以指定在某个RANK上采集Dump数据,下面以Estimator模式训练脚本为例介绍指定方法。
1 2 3 4 5 |
if int(os.getenv('RANK_ID')) == 7: dump_flag = True else: dump_flag = False dump_config = DumpConfig(enable_dump=dump_flag, dump_path="/home/data_dump", dump_step="20", dump_mode="output") |
执行训练,生成Dump数据
开启Dump数据采集功能后,脚本执行时会自动在当前执行目录下生成计算图的dump文件(不含有权重等数据的基本版dump,仅dump经过GE优化、编译后的图),后续开发者通过工具进行精度比对时,会依赖此计算图文件查找dump数据文件。您也可以通过环境变量DUMP_GRAPH_PATH指定dump图文件存储路径,示例:
export DUMP_GRAPH_PATH=/home/dumpgraph
- 执行训练,生成的dump图文件和dump数据文件。
- dump图文件:生成在${DUMP_GRAPH_PATH}/${pid}_${deviceid}目录下,以“ge”开头。
- dump数据文件:生成在dump_path指定的目录下,即{dump_path}/{time}/{deviceid}/{model_name}/{model_id}/{data_index}目录下,以{dump_path}配置/home/HwHiAiUser/output为例,例如存放在“/home/HwHiAiUser/output/20200808163566/0/ge_default_20200808163719_121/11/0”目录下。

- 每次迭代都会产生dump数据,在训练数据集较大的情况下,每次迭代的dump数据量很大(约几十G,甚至更多),建议控制迭代次数,一般仅执行一次迭代。
- 多p环境下,因训练脚本中多device进程调起时间有差异会导致落盘时产生多个时间戳目录。
- 在docker内执行时,生成的数据存在docker里。
- 图执行时,如下算子不会产生dump数据:
- 在图执行前,某些算子明确不会下发到Device侧执行,如条件类算子(if/while/for/case等)、数据类算子(Data/RefData/Const等)、数据流算子(StackPush/StackPop/Concat/Split等)。
- 在图优化过程中,GE会标识部分算子不下发到Device侧执行,这些算子的Dump图中attr的_no_task属性为true。
- 图中走不到最终执行分支的算子。
表1 dump数据文件路径格式说明 路径key
说明
备注
dump_path
训练脚本中设置的dump_path路径(如果设置的是相对路径,则为拼接后的全路径)。
--
time
dump数据文件落盘的时间
格式为:YYYYMMDDHHMMSS
deviceid
Device设备ID号
--
model_name
子图名称
model_name层可能存在多个文件夹,dump数据取计算图名称对应目录下的数据。
如果model_name出现了“.”、“/”、“\”、空格时,转换为下划线表示。
model_id
子图ID号
--
data_index
迭代数,用于保存对应迭代的dump数据
如果指定了dump_step,则data_index和dump_step一致;如果不指定dump_step,则data_index序号从0开始计数,每dump一个迭代的数据,序号递增1。
dump文件
命名规则格式为{op_type}.{op_name}.{taskid}.{stream_id}.{timestamp}。如果按命名规则定义的文件名称长度超过了OS文件名称长度限制(一般是255个字符),则会将该dump文件重命名为一串随机数字,映射关系可查看同目录下的mapping.csv。
如果op_type、op_name出现了“.”、“/”、“\”、空格时,转换为下划线表示。
由于“ge”开头的dump图文件非常多,而且dump数据文件夹的model_name层可能存在多个文件夹,事实上,我们仅需要找到计算图文件,且仅需要model_name为计算图名称的文件夹。下面提供一些方法帮助用户快速找到对应的文件。
- 选取计算图文件。下面提供两种方法:
- 方法一:在所有以“_Build.txt”为结尾的dump图文件中,查找“Iterator”这个关键词。记录查找出的计算图文件名称,用于后续精度比对。
grep Iterator *_Build.txt
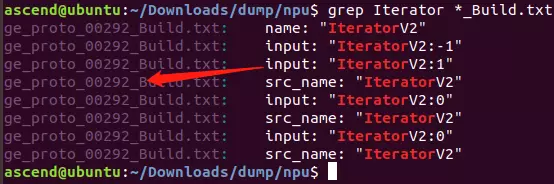
如上图所示,“ge_proto_00292_Build.txt”文件即是我们需要找到的计算图文件。
- 方法二:将TensorFlow模型保存为pb文件,然后查看该模型,选取其中一个计算类算子的名字作为关键字,包含该关键字的dump图文件即为计算图文件。
- 方法一:在所有以“_Build.txt”为结尾的dump图文件中,查找“Iterator”这个关键词。记录查找出的计算图文件名称,用于后续精度比对。
- 选取dump数据文件。
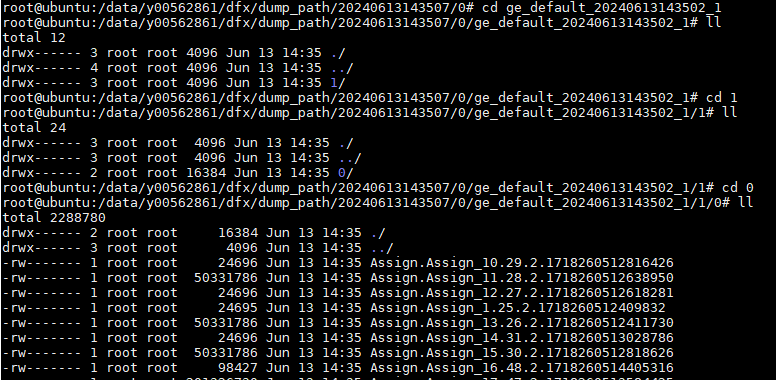
- 打开2中找到的计算图文件,记录graph中的name字段值。如下示例中,记录“ge_default_20240613143502_1”。
graph { name: "ge_default_20240613143502_1" op { name: "atomic_addr_clean0_71" type: "AtomicAddrClean" attr { key: "_fe_imply_type" value { i: 6 } } - 进入以时间戳命名的dump文件存放路径下,我们会看到该目录下存在几个文件夹:
- 找到刚记录的名称为计算图name值的文件夹,例如ge_default_20240613143502_1,该目录下的文件即为需要的dump数据文件。
- 打开2中找到的计算图文件,记录graph中的name字段值。如下示例中,记录“ge_default_20240613143502_1”。